一、系统调用
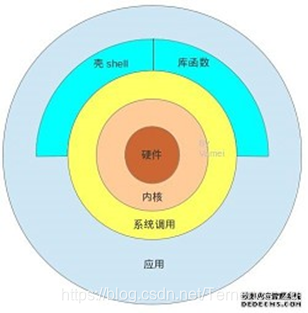
系统调用,我们可以理解是操作系统为用户提供的一系列操作的接口(API),这些接口提供了对系统硬件设备功能的操作。
系统调用是操作系统的一个入口点,在内核地址空间执行,需要在用户空间和内核上下文环境间切换,开销较大。
系统中的各种共享资源都由操作系统统一掌管,在用户程序中,凡是与硬件资源有关的操作(如存储分配、进行I/0传输以及管理文件等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
二、标准库函数调用
库函数可以理解为是对系统调用的一层封装。
函数库调用与用户程序相联系,在用户地址空间执行,属于过程调用,调用开销较小。
库函数调用面向的是应用开发的,相当于应用程序的api,采用这样的方式有很多种原因:
第一:双缓冲技术的实现。第二,可移植性。第三,底层调用本身的一些性能方面的缺陷。第四:让api也可以有了级别和专门的工作面向。
三、 系统调用与标准库函数调用区别
系统调用发生在内核空间,因此如果在用户空间的一般应用程序中使用系统调用来进行文件操作,会有用户空间到内核空间切换的开销,因此开销较大。
事实上,即使在用户空间使用库函数来对文件进行操作,因为文件总是存在于存储介质上,因此不管是读写操作,都是对硬件(存储器)的操作,都必然会引起系统调用。
也就是说,库函数对文件的操作实际上是通过系统调用来实现的。例如C库函数fwrite()就是通过write()系统调用来实现的,因此使用库函数也有系统调用的开销。
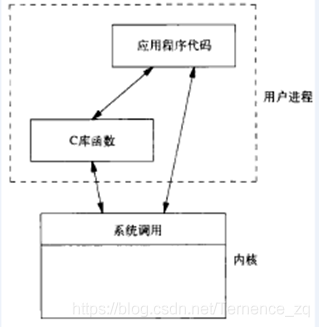
为什么不直接使用系统调用呢?
因为读写文件通常是大量的数据(相对于底层驱动的系统调用所实现的数据操作单位),这时,使用库函数可以大大减少系统调用的次数。
因为缓冲区技术,在用户空间和内核空间对文件操作都使用了缓冲区。当用户空间缓冲区满或者写操作结束时,才将用户缓冲区的内容写到内核缓存区。同理,内核缓冲区满或写结束时,才将内核缓冲区内容写到文件对应的硬件媒介。
系统调用
系统调用函数:open, close, read, write, ioctl等,需要包含头文件unistd.h;
系统调用通常用于底层文件访问,例如在驱动程序中对设备文件的直接访问;
系统调用是操作系统相关的,因此一般没有跨操作系统的可移植性。
标准库函数调用
标准库调用函数:fopen, fread, fwrite, fclose, fflush, fseek等,需要包含头文件stdio.h
标准库函数调用通常用于应用程序中对一般文件的访问。
标准库函数调用是系统无关的,因此可移植性好。
由于标准库函数调用是基于C库的,因此不可能用于内核空间的驱动程序中对设备的操作。
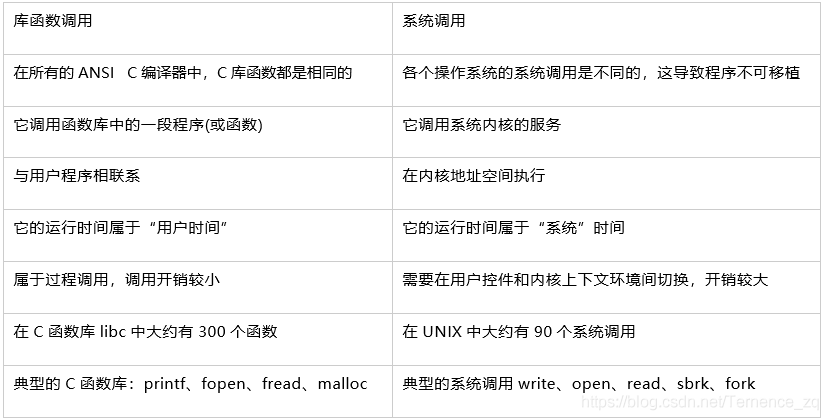
详细可参考如下表格
参考:
https://blog.csdn.net/u010318270/article/details/81058065
https://blog.csdn.net/sz_bb/article/details/51337007