1.fofa.py
import requests
from lxml import etree
import base64
import re
import time
import config
from urllib.parse import quote
def spider():
searchbs64 = quote(str(base64.b64encode(config.SearchKEY.encode()), encoding='utf-8'))
print("爬取页面为:https://fofa.so/result?&qbase64=" + searchbs64)
html = requests.get(url="https://fofa.so/result?&qbase64=" + searchbs64, headers=config.headers).text
tree = etree.HTML(html)
pagenum = tree.xpath('//li[@class="number"]/text()')[5]
# pagenum = re.findall('>(d*)</a> <a class="next_page" rel="next"', html)
print("该关键字存在页码: " + pagenum)
config.StartPage = input("请输入开始页码:
")
config.StopPage = input("请输入终止页码:
")
doc = open("result.txt", "a+")
for i in range(int(config.StartPage), int(pagenum)):
print("Now write " + str(i) + " page")
rep = requests.get(
'https://api.fofa.so/v1/search?qbase64=' + searchbs64 + "&full=false&pn=" + str(i) + "&ps=10",
headers=config.headers)
pattern = re.compile('"link":"(.*?)",')
urllist = re.findall(pattern, rep.text)
print(urllist)
for j in urllist:
print(j)
doc.write(j + "
")
if i == int(config.StopPage):
break
time.sleep(config.TimeSleep)
doc.close()
print("OK,Spider is End .")
if __name__ == '__main__':
spider()
2.config.py
Authorization = ""
headers = {
"Connection": "keep-alive",
"Authorization": Authorization
}
SearchKEY="title='天清汉马usg防火墙'"
StopPage=""
StartPage=""
TimeSleep=5
3.使用方法
config.py中 Authorization 填写参考以下图片位置
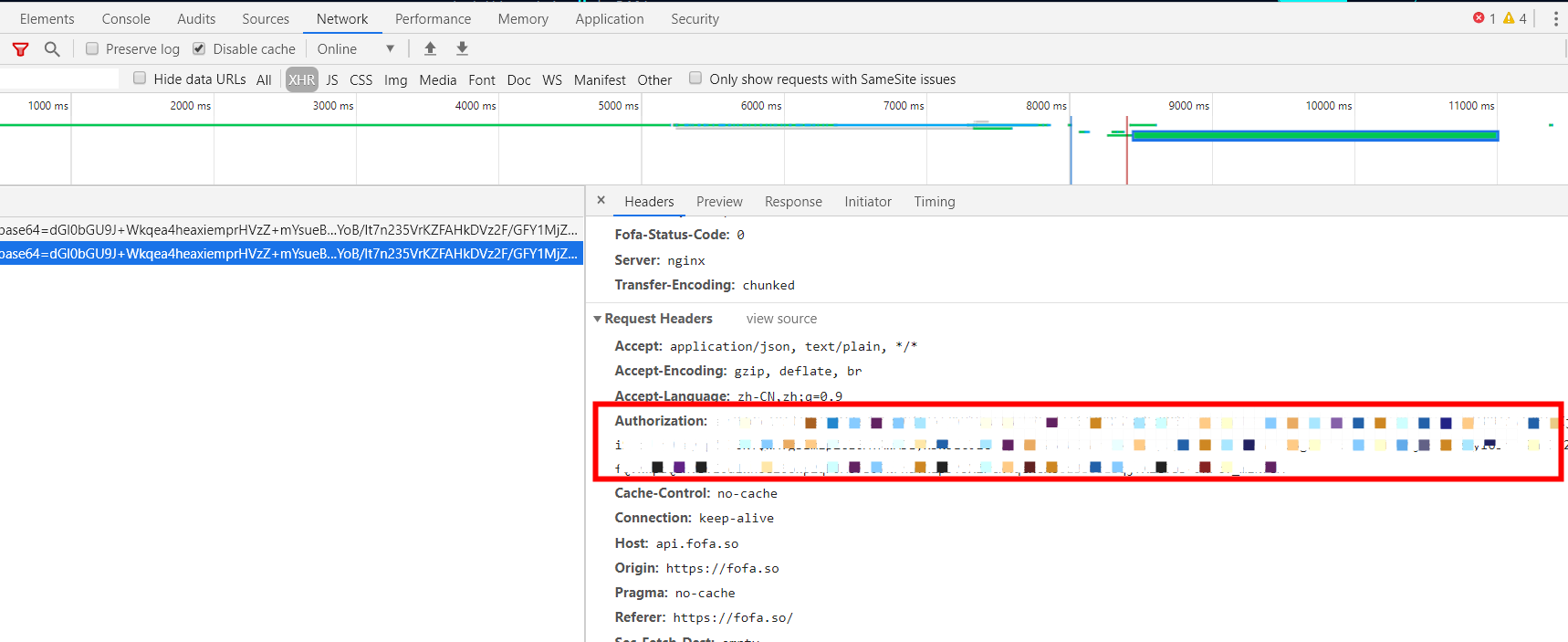
SearchKEY 为要搜索的关键字
执行python fofa.py 生成result.txt