- OLTP 联机事务处理数据库(处理面向用户的大量请求,查询一般是预定义的)
- OLAP 联机分析数据库(处理复杂的聚合)
- HTAP 混合数据库(结合前两者)
数据库架构
- 通信器(连接器)负责传输请求
- 查询处理器对语法进行解释、分析,然后对查询进行优化
- 执行引擎负责执行查询计划
- 存储引擎负责对文件的查询等等
接下来首先重点考察的是存储引擎,考虑在最底层数据如何存储到硬盘上、如何组织成为一个文件,如何将硬盘中的数据拉到内存中进行缓存等等。
存储引擎
一个存储引擎可以粗浅地分为以下的模块:
-
事务管理器
调度事务,确保不会出现逻辑不一致的状态
-
锁管理器
为正在运行的事务锁定数据库,保证并发操作不会破坏物理数据
-
访问方法(存储结构)
管理磁盘上的数据访问并组织磁盘上的数据。包括堆文件和存储结构(例如B树、LSM树等等)
-
缓冲区管理器
将数据页缓冲到内存中
-
恢复管理器
还原系统状态
数据布局
-
面向列的数据库
适合OLAP类聚合分析的工作负载。(如查找趋势、查找平均值等等),可以提高压缩率。
-
面向行的数据库
适合按行读取的数据。
-
宽列式存储
列被分为列族,每个列族中数据逐行存储(例如MongoDB等文档数据库)
文件
-
数据文件
可以采用索引组织表、堆组织表或哈希组织表等来实现。
-
索引文件
数据结构
B树
-
扇出
存储在每个节点中键的数目。
根节点、叶节点、内部节点。B树中每个节点都可以存储数据。
B+ 树
在B树的基础上,只在叶节点上存储数据,而在其他节点上只存储索引信息(分割键)。
WiredTiger
MongoDB中使用的存储引擎,是一种惰性B树,更新会首先保存到更新缓冲区(使用跳表进行实现)中,然后在刷盘时将所有缓冲区中的内容与页协调并进行保存。优点是页更新和结构调整在后台进行,读写进程不用等待。
LA树(惰性自适应树)
相比WiredTiger树,LA树为每个子树都附加了更新缓冲区。每当缓冲区充满时,缓冲区中的更改会进行复制并传播到下一层的缓冲区中。当更新达到叶子结点时,会在叶子结点进行批量的插入、更新或者删除操作。
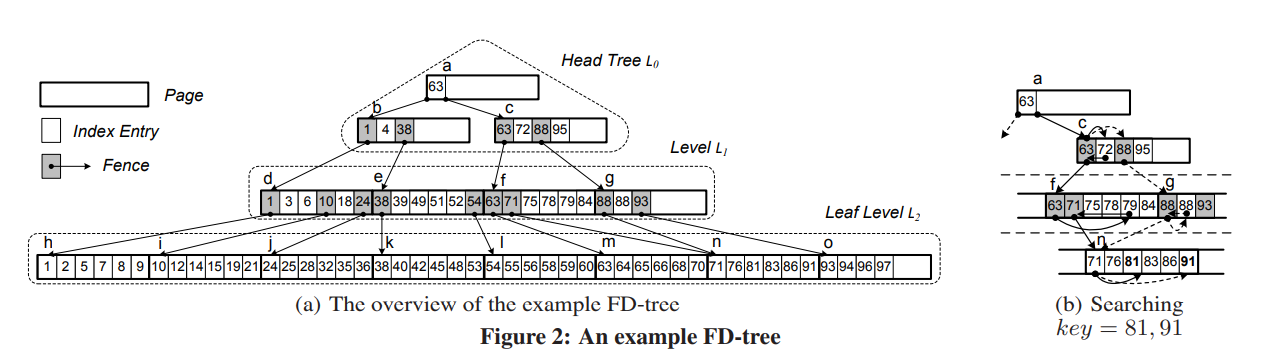
FD树
闪存盘树。由一个小的、可变的头部树和多个不可变的有序段组成。当随机IO产生时,会在头部树上进行,当头部树被填满时,内容会被转移到有序段上。有序段大小超过限制时,会与下一层有序段进行合并,从上至下传递数据。
有序段上采用分段级联进行连接,下一层中每隔n-1项,就把一项(的指针)插入到上一层中。这样搜索时采用二分法,本层找不到时,可以根据下一层的两个指针缩短查找范围。
merge过程如下:每当i-1层满了之后,对i-1和i层进行合并,然后对0-i层的级联进行更新。i至i+1层上如果满了,在进行merge。
Bw树
通过仅追加的存储对不同节点进行批量更新,将节点连接成链。不再更改磁盘上的数据,而是将更改形成一个链直接链在基节点上。
LSM树
LSM树是B树的一种变体,其中节点完全被填满,且写入之后不可变。
-
内存驻留件
通常称为memtable,缓冲数据记录,当达到一定阈值时,被持久化到硬盘上。
-
磁盘驻留件
仅用于读取,对磁盘和内存中的表进行读、合并和文件删除的操作。
双组件LSM树
只有一个磁盘组件,被组织为B树。具有100%的节点占用率和只读的页。
在刷写之后,磁盘和内存中的LSM树都将被丢弃,被合并之后的结果替代。
多组件LSM树
具有不止一个磁盘驻留件。磁盘驻留表的数量会不断增加,增加到一定数量时会触发压实操作,将多张驻留表中的数据进行压实整理和合并。压实前在查找时需要找到全部的驻留表中的数据并进行协调。
BitCask
文件无序,使用Hash表维护顺序。
WiscKey
文件无序,使用B树维护一个索引。
并发控制
乐观并发控制
OCC,允许多个事务执行并发的读取和写入操作。在提交前进行检查,如果存在冲突时会终止其中一个任务。
多版本并发控制
MVCC,允许一条记录同时存在多个时间戳的版本。保证事务督导的是数据库某个时刻的一致视图。
悲观并发控制
PCC,在事务运行时确定其间的冲突,并阻塞或终止执行。