维吉尼亚加密法是一种“多表”替代加密法,曾经在很长时间被认为是无法破译,
它的密钥空间太大了!
vigenere加密算法原理:
相对凯撒加密法的密钥范围0到25,
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| A | B | C | D | E | F | G | H | I | J | K | L | M |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| N | O | P | Q | R | S | T | U | V | W | X | Y | Z |
维吉尼亚加密法不仅仅使用一个数字,而是一系列字母,比如说一个英文单词。
这个单词会分成多个密钥。假设使用'PUZZLE'这个密钥,那么第一个子密钥是'P',用它来
加密明文中的第一个字母,第二个子密钥是'U',用它来加密明文中的第二个字母,当加密完第六个
明文字母时,我们已经用到了第六个子密钥'E',那么,加密下一个明文字母时,将回过头来使用第
一个子密钥,如此循环,直到加密完整个明文消息。
vigenere加密解密算法:
# Vigenere Cipher (Polyalphabetic Substitution Cipher) # http://inventwithpython.com/hacking (BSD Licensed) import pyperclip LETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' def main(): # This text can be copy/pasted from http://invpy.com/vigenereCipher.py myMessage = """Alan Mathison Turing was a British mathematician, logician, cryptanalyst, and computer scientist. He was highly influential in the development of computer science, providing a formalisation of the concepts of "algorithm" and "computation" with the Turing machine. Turing is widely considered to be the father of computer science and artificial intelligence. During World War II, Turing worked for the Government Code and Cypher School (GCCS) at Bletchley Park, Britain's codebreaking centre. For a time he was head of Hut 8, the section responsible for German naval cryptanalysis. He devised a number of techniques for breaking German ciphers, including the method of the bombe, an electromechanical machine that could find settings for the Enigma machine. After the war he worked at the National Physical Laboratory, where he created one of the first designs for a stored-program computer, the ACE. In 1948 Turing joined Max Newman's Computing Laboratory at Manchester University, where he assisted in the development of the Manchester computers and became interested in mathematical biology. He wrote a paper on the chemical basis of morphogenesis, and predicted oscillating chemical reactions such as the Belousov-Zhabotinsky reaction, which were first observed in the 1960s. Turing's homosexuality resulted in a criminal prosecution in 1952, when homosexual acts were still illegal in the United Kingdom. He accepted treatment with female hormones (chemical castration) as an alternative to prison. Turing died in 1954, just over two weeks before his 42nd birthday, from cyanide poisoning. An inquest determined that his death was suicide; his mother and some others believed his death was accidental. On 10 September 2009, following an Internet campaign, British Prime Minister Gordon Brown made an official public apology on behalf of the British government for "the appalling way he was treated." As of May 2012 a private member's bill was before the House of Lords which would grant Turing a statutory pardon if enacted.""" myKey = 'ASIMOV' myMode = 'encrypt' # set to 'encrypt' or 'decrypt' # 由于有大量重复代码,我们把它放进translateMessage,用两个包装器函数,将加密和加密分开, if myMode == 'encrypt': translated = encryptMessage(myKey, myMessage) elif myMode == 'decrypt': translated = decryptMessage(myKey, myMessage) print('%sed message:' % (myMode.title())) print(translated) pyperclip.copy(translated) print() print('The message has been copied to the clipboard.') def encryptMessage(key, message): return translateMessage(key, message, 'encrypt') def decryptMessage(key, message): return translateMessage(key, message, 'decrypt') def translateMessage(key, message, mode): # 使用列表append() + join()方法建立字符串 translated = [] # stores the encrypted/decrypted message string keyIndex = 0 # 确保使用的密钥都是大写 key = key.upper() # symbol遍历消息中的每一个字符,为其加密 for symbol in message: # loop through each character in message num = LETTERS.find(symbol.upper()) # 是字母字符就加密,不是的话 下面的if语句为Flase else不做加解密 if num != -1: # -1 means symbol.upper() was not found in LETTERS if mode == 'encrypt': num += LETTERS.find(key[keyIndex]) # add if encrypting elif mode == 'decrypt': num -= LETTERS.find(key[keyIndex]) # subtract if decrypting # 一行代码处理两种情况的回调 num %= len(LETTERS) # handle the potential wrap-around # add the encrypted/decrypted symbol to the end of translated. # 大小写保留 if symbol.isupper(): translated.append(LETTERS[num]) elif symbol.islower(): translated.append(LETTERS[num].lower()) # 子密钥的循环 keyIndex += 1 # move to the next letter in the key if keyIndex == len(key): keyIndex = 0 else: # The symbol was not in LETTERS, so add it to translated as is. translated.append(symbol) return ''.join(translated) # If vigenereCipher.py is run (instead of imported as a module) call # the main() function. if __name__ == '__main__': main()
输出:
Encrypted message: Adiz Avtzqeci Tmzubb wsa m Pmilqev halpqavtakuoi, lgouqdaf, kdmktsvmztsl, izr xoexghzr kkusitaaf. Vz wsa twbhdg ubalmmzhdad qz hce vmhsgohuqbo ox kaakulmd gxiwvos, krgdurdny i rcmmstugvtawz ca tzm ocicwxfg jf "stscmilpy" oid "uwydptsbuci" wabt hce Lcdwig eiovdnw. Bgfdny qe kddwtk qjnkqpsmev ba pz tzm roohwz at xoexghzr kkusicw izr vrlqrwxist uboedtuuznum. Pimifo Icmlv Emf DI, Lcdwig owdyzd xwd hce Ywhsmnemzh Xovm mby Cqxtsm Supacg (GUKE) oo Bdmfqclwg Bomk, Tzuhvif'a ocyetzqofifo ositjm. Rcm a lqys ce oie vzav wr Vpt 8, lpq gzclqab mekxabnittq tjr Ymdavn fihog cjgbhvnstkgds. Zm psqikmp o iuejqf jf lmoviiicqg aoj jdsvkavs Uzreiz qdpzmdg, dnutgrdny bts helpar jf lpq pjmtm, mb zlwkffjmwktoiiuix avczqzs ohsb ocplv nuby swbfwigk naf ohw Mzwbms umqcifm. Mtoej bts raj pq kjrcmp oo tzm Zooigvmz Khqauqvl Dincmalwdm, rhwzq vz cjmmhzd gvq ca tzm rwmsl lqgdgfa rcm a kbafzd-hzaumae kaakulmd, hce SKQ. Wi 1948 Tmzubb jgqzsy Msf Zsrmsv'e Qjmhcfwig Dincmalwdm vt Eizqcekbqf Pnadqfnilg, ivzrw pq onsaafsy if bts yenmxckmwvf ca tzm Yoiczmehzr uwydptwze oid tmoohe avfsmekbqr dn eifvzmsbuqvl tqazjgq. Pq kmolm m dvpwz ab ohw ktshiuix pvsaa at hojxtcbefmewn, afl bfzdakfsy okkuzgalqzu xhwuuqvl jmmqoigve gpcz ie hce Tmxcpsgd-Lvvbgbubnkq zqoxtawz, kciup isme xqdgo otaqfqev qz hce 1960k. Bgfdny'a tchokmjivlabk fzsmtfsy if i ofdmavmz krgaqqptawz wi 1952, wzmz vjmgaqlpad iohn wwzq goidt uzgeyix wi tzm Gbdtwl Wwigvwy. Vz aukqdoev bdsvtemzh rilp rshadm tcmmgvqg (xhwuuqvl uiehmalqab) vs sv mzoejvmhdvw ba dmikwz. Hpravs rdev qz 1954, xpsl whsm tow iszkk jqtjrw pug 42id tqdhcdsg, rfjm ugmbddw xawnofqzu. Vn avcizsl lqhzreqzsy tzif vds vmmhc wsa eidcalq; vds ewfvzr svp gjmw wfvzrk jqzdenmp vds vmmhc wsa mqxivmzhvl. Gv 10 Esktwunsm 2009, fgtxcrifo mb Dnlmdbzt uiydviyv, Nfdtaat Dmiem Ywiikbqf Bojlab Wrgez avdw iz cafakuog pmjxwx ahwxcby gv nscadn at ohw Jdwoikp scqejvysit xwd "hce sxboglavs kvy zm ion tjmmhzd." Sa at Haq 2012 i bfdvsbq azmtmd'g widt ion bwnafz tzm Tcpsw wr Zjrva ivdcz eaigd yzmbo Tmzubb a kbmhptgzk dvrvwz wa efiohzd. The message has been copied to the clipboard. PS D:PiaYiejczhangSJTU密码学py密码学编程教学代码>
就像在相同的消息上使用多个凯撒加密法。显然,密钥每增加一个字母,可能的密钥数就得乘以26,
vigenere密钥里面的字母越多,加密之后的消息就更可以抵挡暴力破译攻击。

尽管如此,但维吉尼亚加密法终究沦为还是密码分析者的阶下囚
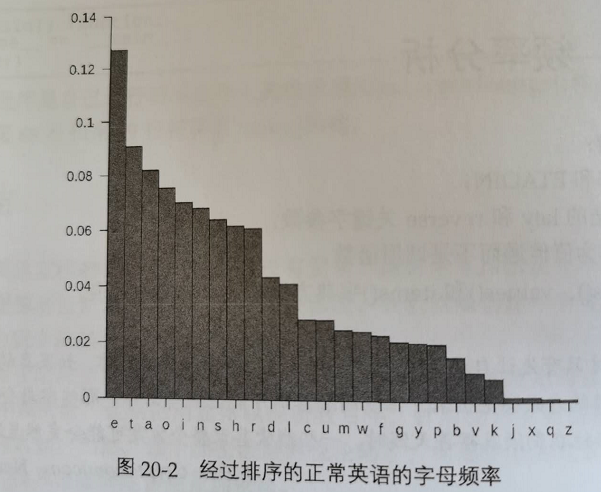
频率分析
频率分析是什么?当我们拿起一本书时候,我们可以遍历书中的每一个字符都,假设他们只有英文字母,
那么肯定可以得到每个字母分别出现了多少次,他们再除以书中总字数,这样就得到了某个字母的出现频率。
有什么用呢?
- 如果是换位加密法,只是字符的位置变化了,每个字母出现频率还是不变,如果说加密之前‘E’出现最多,
加密之后这个特征并不会有任何改变
- 现在如果是用简单的替代加密和凯撒加密方法,我们实际上只是给每个字母都换了一件衣服,
如果之前是'E'出现最多,加密之后‘K’出现最多,那么就说‘K’就是‘E’的衣服,
使用频率分析技术可以用来破译经过维吉尼亚加密的消息。
首先给出几个方便的函数,有利于进一步破译vigenereCipher
# Frequency Finder # http://inventwithpython.com/hacking (BSD Licensed) # frequency taken from http://en.wikipedia.org/wiki/Letter_frequency englishLetterFreq = {'E': 12.70, 'T': 9.06, 'A': 8.17, 'O': 7.51, 'I': 6.97, 'N': 6.75, 'S': 6.33, 'H': 6.09, 'R': 5.99, 'D': 4.25, 'L': 4.03, 'C': 2.78, 'U': 2.76, 'M': 2.41, 'W': 2.36, 'F': 2.23, 'G': 2.02, 'Y': 1.97, 'P': 1.93, 'B': 1.29, 'V': 0.98, 'K': 0.77, 'J': 0.15, 'X': 0.15, 'Q': 0.10, 'Z': 0.07} ETAOIN = 'ETAOINSHRDLCUMWFGYPBVKJXQZ' LETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' def getLetterCount(message): # Returns a dictionary with keys of single letters and values of the # count of how many times they appear in the message parameter. letterCount = {'A': 0, 'B': 0, 'C': 0, 'D': 0, 'E': 0, 'F': 0, 'G': 0, 'H': 0, 'I': 0, 'J': 0, 'K': 0, 'L': 0, 'M': 0, 'N': 0, 'O': 0, 'P': 0, 'Q': 0, 'R': 0, 'S': 0, 'T': 0, 'U': 0, 'V': 0, 'W': 0, 'X': 0, 'Y': 0, 'Z': 0} for letter in message.upper(): if letter in LETTERS: letterCount[letter] += 1 return letterCount # 传给他一个元组,返回第一个索引的项 def getItemAtIndexZero(x): return x[0] # 返回时字母表的26个大写字母按照他们在message参数里出现的频率排序的字符串 # 如果T出现频率最高,显然就是T打头的字符串 def getFrequencyOrder(message): # Returns a string of the alphabet letters arranged in order of most # frequently occurring in the message parameter. # 这个程序分成了5步得到希望的字符串 # first, get a dictionary of each letter and its frequency count #首先得到message的每个字母出现次数 letterToFreq = getLetterCount(message) # second, make a dictionary of each frequency count to each letter(s) # with that frequency # 我们需要这样的一个字典,字典的键是频率(mesage中的次数),值是出现这个次数 # 的字母列表。 # 第二步只是简单的生成这个字典,还不期望它里面有优美的顺序,排序等到下一步再做 # 很明显,最多26个键值对, # 键是某个字母出现的次数是一个数值,键的值是一个列表,列表中的项是单个字母 freqToLetter = {} for letter in LETTERS: if letterToFreq[letter] not in freqToLetter: freqToLetter[letterToFreq[letter]] = [letter] else: freqToLetter[letterToFreq[letter]].append(letter) # third, put each list of letters in reverse "ETAOIN" order, and then # convert it to a string # 当多个字母关联到一个频率时,我们希望这些字母按照他们出现在 ETAOIN 字符串 # 里面的相反顺序排序 保证最后getFrequencyOrder对于相同的输入只有唯一的输出 # 为什么要用相反的顺序还有一点,以便englishFreqMatchScore函数产生 # 较低的匹配分值而不是较高的分值 for freq in freqToLetter: # 把函数作为值传递,这时后的顺序为ETAOIN.find('A')、ETAOIN.find('B')、 # ETAOIN.find('C')、等返回的整数顺序来排序他们 freqToLetter[freq].sort(key=ETAOIN.find, reverse=True) freqToLetter[freq] = ''.join(freqToLetter[freq]) #把键对应的值--->列表,转化为字符串,那些包含多个元素的列表转化成字符串时 # 里面的字母顺序应和 ETAOIN 字符串的字母顺序相反 # fourth, convert the freqToLetter dictionary to a list of tuple # pairs (key, value), then sort them # freqPairs里的项会按照元组值索引0上值得数字顺序来排序,也就是整数频率 freqPairs = list(freqToLetter.items()) freqPairs.sort(key=getItemAtIndexZero, reverse=True) # fifth, now that the letters are ordered by frequency, extract all # the letters for the final string # reqPair[1]上的才是字母哦! freqOrder = [] for freqPair in freqPairs: freqOrder.append(freqPair[1]) return ''.join(freqOrder) # 计算message分数 def englishFreqMatchScore(message): # Return the number of matches that the string in the message # parameter has when its letter frequency is compared to English # letter frequency. A "match" is how many of its six most frequent # and six least frequent letters is among the six most frequent and # six least frequent letters for English. freqOrder = getFrequencyOrder(message) matchScore = 0 # Find how many matches for the six most common letters there are. for commonLetter in ETAOIN[:6]: if commonLetter in freqOrder[:6]: matchScore += 1 # Find how many matches for the six least common letters there are. for uncommonLetter in ETAOIN[-6:]: if uncommonLetter in freqOrder[-6:]: matchScore += 1 return matchScore
分别是:
getLetterCount()计算字母出现频率
getFrequencyOrder()对出现各种频率的字母进行特定排序
englishFreqMatchScore()计算每个message的匹配分值
匹配分值是什么意思?我们这样想,如果现在用英文中的平均情况得到了一个字母出现顺序,
这样的话,从一段使用某种加密方法的密文中我们也计算他的字母出现频率顺序,假设得到的结果为:
messageLetterfreqOrderedToString = 'QWERTYUIOPLKJHGFDSAXCVBNM'
'ETAOINSHRDLCUMWFGYPBVKJXQZ'
'QWERTYUIOPLKJHGFDSAZXCVBNM'
如果前六个字母出现i个ETAOIN中的字母就加i分
如果后六个字母出现j个VKJXQZ中的字母就加j分
'QWERTYUIOPLKJHGFDSAZXCVBNM'字符串的分值便是2分,某个字符串的值是i+j分
分数越高,那就越接近正确英文中的字母顺序,就越有破译的可能。
两种破译vigenereCipher的方法
- 字典攻击------针对那些key使用英文单词
- 一般情况破译-------使用随机的字母字符串作为key
对于字典攻击,在上面我们已经给出了vigenere加密解密算法,
那么只需要用字典中的每个单词作为key,对密文进行破译,然后用isEnglish进行判断,即可得到可能的密文
字典攻击暴力破译源码:
# Vigenere Cipher Dictionary Hacker # http://inventwithpython.com/hacking (BSD Licensed) import detectEnglish, vigenereCipher, pyperclip def main(): ciphertext = """Tzx isnz eccjxkg nfq lol mys bbqq I lxcz.""" hackedMessage = hackVigenere(ciphertext) if hackedMessage != None: print('Copying hacked message to clipboard:') print(hackedMessage) pyperclip.copy(hackedMessage) else: print('Failed to hack encryption.') def hackVigenere(ciphertext): fo = open('dictionary.txt') # fo.readlines()返回一个列表,每一个项都是文件里的一行, # 列表里的每个字符串都是以 换行符号结尾的!!! # 最后一个字符串例外,文件可能不以换行符结束 words = fo.readlines() fo.close() for word in words: # strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。 # 注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。 word = word.strip() # remove the newline at the end decryptedText = vigenereCipher.decryptMessage(word, ciphertext) if detectEnglish.isEnglish(decryptedText, wordPercentage=40): # Check with user to see if the decrypted key has been found. print() print('Possible encryption break:') print('Key ' + str(word) + ': ' + decryptedText[:100]) print() print('Enter D for done, or just press Enter to continue breaking:') response = input('> ') if response.upper().startswith('D'): return decryptedText if __name__ == '__main__': main()
输出:
Possible encryption break: Key ASTROLOGY: The recl yecrets crk not the qnks I tell. Enter D for done, or just press Enter to continue breaking: > d Copying hacked message to clipboard: The recl yecrets crk not the qnks I tell.
但是 The recl yecrets crk not the qnks I tell.看起来并不完整,我们接着破译:
Possible encryption break: Key ASTROLOGY: The recl yecrets crk not the qnks I tell. Enter D for done, or just press Enter to continue breaking: > Possible encryption break: Key ASTRONOMY: The real secrets are not the ones I tell. Enter D for done, or just press Enter to continue breaking: > D Copying hacked message to clipboard: The real secrets are not the ones I tell.
所以,永远不要使用英语单词作为维吉尼亚加密密钥。这很容易受到字典攻击
破译使用一般字母字符串作为加密密钥得到的密文
我们当然希望结合密码分析,来破译那种使用一般字母字符串作为加密密钥得到的密文。 ↓↓↓↓↓↓↓
Charles Babbage 巴贝奇破译了维吉尼亚加密法,但是它没有发表他的方法,他使用的方法后来由数学家
Friedrich Kasiski 卡西斯基发表。
记住这两个哥们
首先简单介绍一下破译整体思路,然后再给出源代码。
破译思路:
这是一个聪明的算法,需要在做少量的计算情况下做最正确的事情(相比于暴力破译来说)
减少计算。。。确定密钥长度就能减少好多计算!!!!只要确定了密钥的长度连暴力破译都看起来那么可爱
假设我们有了某种算法确定了密钥的长度,然后怎么办呢 ?
最终目的是具体的密钥,但人不能一口吃成个胖子,我们需要循序渐进,找出每个子密钥
每个子密钥有26种可能,我们只管概率最大的那个,那就必须有排序了,
回想上面我们讲过的匹配分值,最后的输出不就是一个含顺序的元组列表嘛!(嘿上面的是铺垫)
我们只要找出每个子密钥最可能的那几个解密字符,然后对他们自由组合,一一测试vigenereCipher解密,破译的结果用
之前说过的isEnglish()方法识别,实际上我们大多数的破译结果都用了这个判定方法。
很可能用这个略微机智的办法,我们就把vigenereCipher给盘了!
确定密钥的长度→匹配分值→每个子密钥最可能的那几个解密字符→自由组合→vigenereCipher解密→isEnglish()方法→成败
假设有密文:(被转化为大写后的)
PPQCA XQVEKG YBNKMAZU YBNGBAL JON I TSZM JYIM. VRAG VOHT VRAU C TKSG. DDWUO XITLAZU VAVV RAZ C VKB QP IWPOU
确定密钥的长度(卡希斯基试验)
找出重复序列的间距
密文中的重复序列,比如:
THECATISOUTOFTHEBAG
SPILLTHEBEANSSPILLT
LWMNLMPWPYTBXLWMMLZ
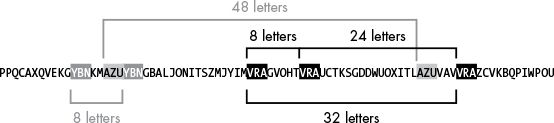
我们可以得到VRA, AZU, 和YBN就是重复序列,然后可以得到他们的间距
VAR:8、24、32
AZU:48
YBN:8
获取间距的因数

对所有因数做统计得到因数序列,并认为:次数最高的因数很可能就是维吉尼亚密钥的长度
显然,2、4、8的出现次数最高,密钥长度很可能就在这些值中
匹配分值(把密文分成密钥长度那么多个序列,用每个序列来确定对应的子密钥
从字符串获取每隔key_length个字母
假设我们使用key_length是4,那么密文会被这样分割:
第一个序列:

第二个序列:

直到密文被全部分割成key_length(= 4)个序列:

频率分析(用子密钥的26种可能对每个对应的子字符串解密,做频率分析,即匹配分值)
每个子密钥都有26种可能(26个英文字母),我们依次确定每个子密钥对应的字母中最可能的那几个:
对第一个密文序列:

那么对于这个序列来说,也是对于第一个子密钥来说,最有可能的子密钥为:A、I、N、W、X
循环所有的序列得到类似的结果:

在程序中 每个序列最可能的几个子密钥,截取几个?这个是我们自己需要设定的参数(常量)
每个子密钥最可能的那几个解密字符→自由组合→vigenereCipher解密→isEnglish()方法
我们希望在上一步得到这样的结果:
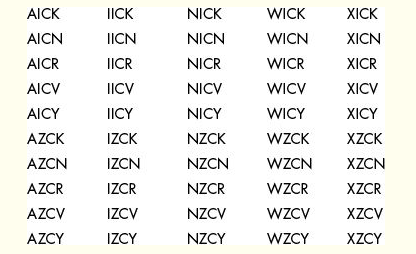
这个例子中,我们不用计算很多次,就会发现:密钥是WICK.
维吉尼亚破译程序源码:
# Vigenere Cipher Hacker # http://inventwithpython.com/hacking (BSD Licensed) import itertools, re import vigenereCipher, pyperclip, freqAnalysis, detectEnglish LETTERS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' SILENT_MODE = False # if set to True, program doesn't print attempts NUM_MOST_FREQ_LETTERS = 4 # attempts this many letters per subkey MAX_KEY_LENGTH = 16 # will not attempt keys longer than this NONLETTERS_PATTERN = re.compile('[^A-Z]') def main(): # Instead of typing this ciphertext out, you can copy & paste it # from http://invpy.com/vigenereHacker.py ciphertext = """Adiz Avtzqeci Tmzubb wsa m Pmilqev halpqavtakuoi, lgouqdaf, kdmktsvmztsl, izr xoexghzr kkusitaaf. Vz wsa twbhdg ubalmmzhdad qz hce vmhsgohuqbo ox kaakulmd gxiwvos, krgdurdny i rcmmstugvtawz ca tzm ocicwxfg jf "stscmilpy" oid "uwydptsbuci" wabt hce Lcdwig eiovdnw. Bgfdny qe kddwtk qjnkqpsmev ba pz tzm roohwz at xoexghzr kkusicw izr vrlqrwxist uboedtuuznum. Pimifo Icmlv Emf DI, Lcdwig owdyzd xwd hce Ywhsmnemzh Xovm mby Cqxtsm Supacg (GUKE) oo Bdmfqclwg Bomk, Tzuhvif'a ocyetzqofifo ositjm. Rcm a lqys ce oie vzav wr Vpt 8, lpq gzclqab mekxabnittq tjr Ymdavn fihog cjgbhvnstkgds. Zm psqikmp o iuejqf jf lmoviiicqg aoj jdsvkavs Uzreiz qdpzmdg, dnutgrdny bts helpar jf lpq pjmtm, mb zlwkffjmwktoiiuix avczqzs ohsb ocplv nuby swbfwigk naf ohw Mzwbms umqcifm. Mtoej bts raj pq kjrcmp oo tzm Zooigvmz Khqauqvl Dincmalwdm, rhwzq vz cjmmhzd gvq ca tzm rwmsl lqgdgfa rcm a kbafzd-hzaumae kaakulmd, hce SKQ. Wi 1948 Tmzubb jgqzsy Msf Zsrmsv'e Qjmhcfwig Dincmalwdm vt Eizqcekbqf Pnadqfnilg, ivzrw pq onsaafsy if bts yenmxckmwvf ca tzm Yoiczmehzr uwydptwze oid tmoohe avfsmekbqr dn eifvzmsbuqvl tqazjgq. Pq kmolm m dvpwz ab ohw ktshiuix pvsaa at hojxtcbefmewn, afl bfzdakfsy okkuzgalqzu xhwuuqvl jmmqoigve gpcz ie hce Tmxcpsgd-Lvvbgbubnkq zqoxtawz, kciup isme xqdgo otaqfqev qz hce 1960k. Bgfdny'a tchokmjivlabk fzsmtfsy if i ofdmavmz krgaqqptawz wi 1952, wzmz vjmgaqlpad iohn wwzq goidt uzgeyix wi tzm Gbdtwl Wwigvwy. Vz aukqdoev bdsvtemzh rilp rshadm tcmmgvqg (xhwuuqvl uiehmalqab) vs sv mzoejvmhdvw ba dmikwz. Hpravs rdev qz 1954, xpsl whsm tow iszkk jqtjrw pug 42id tqdhcdsg, rfjm ugmbddw xawnofqzu. Vn avcizsl lqhzreqzsy tzif vds vmmhc wsa eidcalq; vds ewfvzr svp gjmw wfvzrk jqzdenmp vds vmmhc wsa mqxivmzhvl. Gv 10 Esktwunsm 2009, fgtxcrifo mb Dnlmdbzt uiydviyv, Nfdtaat Dmiem Ywiikbqf Bojlab Wrgez avdw iz cafakuog pmjxwx ahwxcby gv nscadn at ohw Jdwoikp scqejvysit xwd "hce sxboglavs kvy zm ion tjmmhzd." Sa at Haq 2012 i bfdvsbq azmtmd'g widt ion bwnafz tzm Tcpsw wr Zjrva ivdcz eaigd yzmbo Tmzubb a kbmhptgzk dvrvwz wa efiohzd.""" hackedMessage = hackVigenere(ciphertext) if hackedMessage != None: print('Copying hacked message to clipboard:') print(hackedMessage) pyperclip.copy(hackedMessage) else: print('Failed to hack encryption.') #得到的结果类似为:字典{'VAR':[8, 24, 32], 'AZU':[48], 'YBN':[8]} def findRepeatSequencesSpacings(message): # Goes through the message and finds any 3 to 5 letter sequences # that are repeated. Returns a dict with the keys of the sequence and # values of a list of spacings (num of letters between the repeats). # Use a regular expression to remove non-letters from the message. # 使用正则表达式来移除message中的非A~Z字符 message = NONLETTERS_PATTERN.sub('', message.upper()) # Compile a list of seqLen-letter sequences found in the message. seqSpacings = {} # keys are sequences, values are list of int spacings # 寻找重复序列,这个序列的长度设为多少 如果range(3, 6) 就是要找所有长度为3 4 5 的短序列 for seqLen in range(3, 6): # seqStart会在什么位置? 因为最后的seqLen长度的那个seq在整个串的最后啊,就没有检测的必要了 for seqStart in range(len(message) - seqLen): # Determine what the sequence is, and store it in seq seq = message[seqStart:seqStart + seqLen] # Look for this sequence in the rest of the message # i 是本轮检测开始的位置 for i in range(seqStart + seqLen, len(message) - seqLen): if message[i:i + seqLen] == seq: # Found a repeated sequence. if seq not in seqSpacings: seqSpacings[seq] = [] # initialize blank list # Append the spacing distance between the repeated # sequence and the original sequence. seqSpacings[seq].append(i - seqStart) return seqSpacings # 用遍历一定范围的数(key的长度) def getUsefulFactors(num): # Returns a list of useful factors of num. By "useful" we mean factors # less than MAX_KEY_LENGTH + 1. For example, getUsefulFactors(144) # returns [2, 72, 3, 48, 4, 36, 6, 24, 8, 18, 9, 16, 12] if num < 2: return [] # numbers less than 2 have no useful factors factors = [] # the list of factors found # When finding factors, you only need to check the integers up to # MAX_KEY_LENGTH. for i in range(2, MAX_KEY_LENGTH + 1): # don't test 1 if num % i == 0: factors.append(i) factors.append(int(num / i)) if 1 in factors: factors.remove(1) #使用set()方法返回一个集合达到移除重复元素的目的 return list(set(factors)) def getItemAtIndexOne(x): return x[1] def getMostCommonFactors(seqFactors): # First, get a count of how many times a factor occurs in seqFactors. factorCounts = {} # key is a factor, value is how often if occurs # seqFactors keys are sequences, values are lists of factors of the # spacings. seqFactors has a value like: {'GFD': [2, 3, 4, 6, 9, 12, # 18, 23, 36, 46, 69, 92, 138, 207], 'ALW': [2, 3, 4, 6, ...], ...} for seq in seqFactors: factorList = seqFactors[seq] for factor in factorList: if factor not in factorCounts: factorCounts[factor] = 0 factorCounts[factor] += 1 # factorCounts是字典,我们还是希望得到元组列表(第一个值是因子,第二个是该因子出现的次数),而且是排序过的如 # [(3,56), (2, 36), (4, 24), ... , (13, 2)] ===>factorsByCount # Second, put the factor and its count into a tuple, and make a list # of these tuples so we can sort them. factorsByCount = [] for factor in factorCounts: # exclude factors larger than MAX_KEY_LENGTH if factor <= MAX_KEY_LENGTH: # factorsByCount is a list of tuples: (factor, factorCount) # factorsByCount has a value like: [(3, 497), (2, 487), ...] factorsByCount.append( (factor, factorCounts[factor]) ) # Sort the list by the factor count. # 使用sort方法的key关键字和reverse关键字+函数值作为参数而不是调用 来排序 这种方法牛逼啊 factorsByCount.sort(key=getItemAtIndexOne, reverse=True) return factorsByCount # 把上面的几个步骤先封装起来,在做另一些操作 # 返回一组给定密文最有可能的密钥长度,这些密钥长度是列表里的整数, # 列表开头是最有可能的长度,下一个元素次之 # (要说明的是只是用seq来得到有可能的密钥长度才是关键的,得到完了之后用别的方法来确定 # # 卡西斯基测试就是希望得到一个可能密钥长度的列表 def kasiskiExamination(ciphertext): # Find out the sequences of 3 to 5 letters that occur multiple times # in the ciphertext. repeatedSeqSpacings has a value like: # {'EXG': [192], 'NAF': [339, 972, 633], ... } repeatedSeqSpacings = findRepeatSequencesSpacings(ciphertext) # See getMostCommonFactors() for a description of seqFactors. seqFactors = {} for seq in repeatedSeqSpacings: seqFactors[seq] = [] for spacing in repeatedSeqSpacings[seq]: seqFactors[seq].extend(getUsefulFactors(spacing)) # See getMostCommonFactors() for a description of factorsByCount. factorsByCount = getMostCommonFactors(seqFactors) # Now we extract the factor counts from factorsByCount and # put them in allLikelyKeyLengths so that they are easier to # use later. allLikelyKeyLengths = [] for twoIntTuple in factorsByCount: allLikelyKeyLengths.append(twoIntTuple[0]) return allLikelyKeyLengths # 得到密钥长度后我们怎么操作? # 1、使用密钥长度除len(message得到一个整数,也就是一共用了几轮密钥) # 2、key_length把密文分成了key_length这么多个段 显然,第一段用key中第一个子密钥加密 # 第i(i<= key_length)(i th)段用key中第i个子密钥加密 def getNthSubkeysLetters(n, keyLength, message): # Returns every Nth letter for each keyLength set of letters in text. # E.g. getNthSubkeysLetters(1, 3, 'ABCABCABC') returns 'AAA' # getNthSubkeysLetters(2, 3, 'ABCABCABC') returns 'BBB' # getNthSubkeysLetters(3, 3, 'ABCABCABC') returns 'CCC' # getNthSubkeysLetters(1, 5, 'ABCDEFGHI') returns 'AF' # Use a regular expression to remove non-letters from the message. # 使用正则表达式的sub方法去除message中的何既不是从A到Z的字母也不是空格字符的字符 message = NONLETTERS_PATTERN.sub('', message) # 使用列表append+join方法快速创建字符串 i = n - 1 letters = [] while i < len(message): letters.append(message[i]) i += keyLength return ''.join(letters) def attemptHackWithKeyLength(ciphertext, mostLikelyKeyLength): # Determine the most likely letters for each letter in the key. ciphertextUp = ciphertext.upper() # allFreqScores is a list of mostLikelyKeyLength number of lists. # These inner lists are the freqScores lists. # 返回的是双重列表 第一重里面有mostLikelyKeyLength个内层列表 第i个内层列表里面的元素是第i个子密钥的可能元组(共 NUM_MOST_FREQ_LETTERS 可设置) allFreqScores = [] for nth in range(1, mostLikelyKeyLength + 1): nthLetters = getNthSubkeysLetters(nth, mostLikelyKeyLength, ciphertextUp) # freqScores is a list of tuples like: # [(<letter>, <Eng. Freq. match score>), ... ] # List is sorted by match score. Higher score means better match. # See the englishFreqMatchScore() comments in freqAnalysis.py. freqScores = [] for possibleKey in LETTERS: decryptedText = vigenereCipher.decryptMessage(possibleKey, nthLetters) keyAndFreqMatchTuple = (possibleKey, freqAnalysis.englishFreqMatchScore(decryptedText)) freqScores.append(keyAndFreqMatchTuple) # Sort by match score # 按分数排序元组 元组中第一个元素是pussibleKey 第二个元素是他的分数 这个pussible # 数值的默认排序是升序,我们要的是降序,所以要把reverse值True # 此轮for循环在LETTERS中,返回的元组列表有26个元组,每个元组对应子密钥中的一个 # [('A', 8), ('B', 2), ('C', 2), ('D', 1), ('E', 4), ('F', 2), ('G', 3), ('H', 2), ('I', 2), ('J', 0), ('K', 2), ('L', 5), ('M', 5), ('N', 4), ...] freqScores.sort(key=getItemAtIndexOne, reverse=True) #NUM_MOST_FREQ_LETTERS 但是我们不要考虑全部26个 肯定是要分数高的,截取下来备用即可 allFreqScores.append(freqScores[:NUM_MOST_FREQ_LETTERS]) #[[(...), (...), (...), (...)], [(...), (...), (...), (...)], [(...), (...), (...), (...)]] # 处理形如:[[('F', score), ('H', score), ('N', score), ('Q', sxore)], [(, ), (, ), (, ), (, )], [(, ), (, ), (, ), (, )]] mostLikelyKeyLength=3 NUM_MOST_FREQ_LETTERS= 4 if not SILENT_MODE: for i in range(len(allFreqScores)): # use i + 1 so the first letter is not called the "0th" letter # print()函数我们知道,打印 python会把传给他的东西+' '换行符号一起输出 # 但是有时候我们并不想一换行符号结尾, 就可以用print的end关键字参数 想以什么结尾就用什么结尾 print('Possible letters for letter %s of the key: ' % (i + 1), end='') for freqScore in allFreqScores[i]: print('%s ' % freqScore[0], end='') print() # print a newline # Try every combination of the most likely letters for each position # in the key. # 太牛了 使用python中的接口,遍历每一种组合 for indexes in itertools.product(range(NUM_MOST_FREQ_LETTERS), repeat=mostLikelyKeyLength): # Create a possible key from the letters in allFreqScores possibleKey = '' for i in range(mostLikelyKeyLength): possibleKey += allFreqScores[i][indexes[i]][0] #元组中的字符串中的字母字符 if not SILENT_MODE: print('Attempting with key: %s' % (possibleKey)) # 这步需要使用明确的子密钥,尽管只是尝试 decryptedText = vigenereCipher.decryptMessage(possibleKey, ciphertextUp) if detectEnglish.isEnglish(decryptedText): # Set the hacked ciphertext to the original casing. origCase = [] for i in range(len(ciphertext)): if ciphertext[i].isupper(): origCase.append(decryptedText[i].upper()) else: origCase.append(decryptedText[i].lower()) decryptedText = ''.join(origCase) # Check with user to see if the key has been found. print('Possible encryption hack with key %s:' % (possibleKey)) print(decryptedText[:200]) # only show first 200 characters print() print('Enter D for done, or just press Enter to continue hacking:') response = input('> ') if response.strip().upper().startswith('D'): return decryptedText # No English-looking decryption found, so return None. # 上面已经有return了 这个return是破译未成功的防线 return None def hackVigenere(ciphertext): # First, we need to do Kasiski Examination to figure out what the # length of the ciphertext's encryption key is. allLikelyKeyLengths = kasiskiExamination(ciphertext) if not SILENT_MODE: keyLengthStr = '' for keyLength in allLikelyKeyLengths: keyLengthStr += '%s ' % (keyLength) print('Kasiski Examination results say the most likely key lengths are: ' + keyLengthStr + ' ') for keyLength in allLikelyKeyLengths: if not SILENT_MODE: print('Attempting hack with key length %s (%s possible keys)...' % (keyLength, NUM_MOST_FREQ_LETTERS ** keyLength)) hackedMessage = attemptHackWithKeyLength(ciphertext, keyLength) # 如果没有返回None 就破译成功了 if hackedMessage != None: break # If none of the key lengths we found using Kasiski Examination # worked, start brute-forcing through key lengths. if hackedMessage == None: if not SILENT_MODE: print('Unable to hack message with likely key length(s). Brute forcing key length...') for keyLength in range(1, MAX_KEY_LENGTH + 1): # don't re-check key lengths already tried from Kasiski if keyLength not in allLikelyKeyLengths: if not SILENT_MODE: print('Attempting hack with key length %s (%s possible keys)...' % (keyLength, NUM_MOST_FREQ_LETTERS ** keyLength)) hackedMessage = attemptHackWithKeyLength(ciphertext, keyLength) if hackedMessage != None: break return hackedMessage # If vigenereHacker.py is run (instead of imported as a module) call # the main() function. if __name__ == '__main__': main()
输出:
Kasiski Examination results say the most likely key lengths are: 3 2 6 4 12 8 9 16 5 11 10 15 7 14 13 Attempting hack with key length 3 (64 possible keys)... Possible letters for letter 1 of the key: A L M E Possible letters for letter 2 of the key: S N O C Possible letters for letter 3 of the key: V I Z B Attempting with key: ASV Attempting with key: ASI Attempting with key: ASZ Attempting with key: ASB Attempting with key: ANV Attempting with key: ANI Attempting with key: ANZ Attempting with key: ANB Attempting with key: AOV Attempting with key: AOI Attempting with key: AOZ Attempting with key: AOB Attempting with key: ACV Attempting with key: ACI Attempting with key: ACZ Attempting with key: ACB Attempting with key: LSV Attempting with key: LSI Attempting with key: LSZ Attempting with key: LSB Attempting with key: LNV Attempting with key: LNI Attempting with key: LNZ Attempting with key: LNB Attempting with key: LOV Attempting with key: LOI Attempting with key: LOZ Attempting with key: LOB Attempting with key: LCV Attempting with key: LCI Attempting with key: LCZ Attempting with key: LCB Attempting with key: MSV Attempting with key: MSI Attempting with key: MSZ Attempting with key: MSB Attempting with key: MNV Attempting with key: MNI Attempting with key: MNZ Attempting with key: MNB Attempting with key: MOV Attempting with key: MOI Attempting with key: MOZ Attempting with key: MOB Attempting with key: MCV Attempting with key: MCI Attempting with key: MCZ Attempting with key: MCB Attempting with key: ESV Attempting with key: ESI Attempting with key: ESZ Attempting with key: ESB Attempting with key: ENV Attempting with key: ENI Attempting with key: ENZ Attempting with key: ENB Attempting with key: EOV Attempting with key: EOI Attempting with key: EOZ Attempting with key: EOB Attempting with key: ECV Attempting with key: ECI Attempting with key: ECZ Attempting with key: ECB Attempting hack with key length 2 (16 possible keys)... Possible letters for letter 1 of the key: O A E Z Possible letters for letter 2 of the key: M S I D Attempting with key: OM Attempting with key: OS Attempting with key: OI Attempting with key: OD Attempting with key: AM Attempting with key: AS Attempting with key: AI Attempting with key: AD Attempting with key: EM Attempting with key: ES Attempting with key: EI Attempting with key: ED Attempting with key: ZM Attempting with key: ZS Attempting with key: ZI Attempting with key: ZD Attempting hack with key length 6 (4096 possible keys)... Possible letters for letter 1 of the key: A E O P Possible letters for letter 2 of the key: S D G H Possible letters for letter 3 of the key: I V X B Possible letters for letter 4 of the key: M Z Q A Possible letters for letter 5 of the key: O B Z A Possible letters for letter 6 of the key: V I K Z Attempting with key: ASIMOV Possible encryption hack with key ASIMOV: Alan Mathison Turing was a British mathematician, logician, cryptanalyst, and computer scientist. He was highly influential in the development of computer science, providing a formalisation of the con Enter D for done, or just press Enter to continue hacking: > d Copying hacked message to clipboard: Alan Mathison Turing was a British mathematician, logician, cryptanalyst, and computer scientist. He was highly influential in the development of computer science, providing a formalisation of the concepts of "algorithm" and "computation" with the Turing machine. Turing is widely considered to be the father of computer science and artificial intelligence. During World War II, Turing worked for the Government Code and Cypher School (GCCS) at Bletchley Park, Britain's codebreaking centre. For a time he was head of Hut 8, the section responsible for German naval cryptanalysis. He devised a number of techniques for breaking German ciphers, including the method of the bombe, an electromechanical machine that could find settings for the Enigma machine. After the war he worked at the National Physical Laboratory, where he created one of the first designs for a stored-program computer, the ACE. In 1948 Turing joined Max Newman's Computing Laboratory at Manchester University, where he assisted in the development of the Manchester computers and became interested in mathematical biology. He wrote a paper on the chemical basis of morphogenesis, and predicted oscillating chemical reactions such as the Belousov-Zhabotinsky reaction, which were first observed in the 1960s. Turing's homosexuality resulted in a criminal prosecution in 1952, when homosexual acts were still illegal in the United Kingdom. He accepted treatment with female hormones (chemical castration) as an alternative to prison. Turing died in 1954, just over two weeks before his 42nd birthday, from cyanide poisoning. An inquest determined that his death was suicide; his mother and some others believed his death was accidental. On 10 September 2009, following an Internet campaign, British Prime Minister Gordon Brown made an official public apology on behalf of the British government for "the appalling way he was treated." As of May 2012 a private member's bill was before the House of Lords which would grant Turing a statutory pardon if enacted. PS D:PiaYiejczhang\密码学py密码学编程教学代码>