概
当面对时序信息的时候, 如果利用GAN呢?
主要内容
一般的生成器接受一个噪声, 其输出是一个连续的域, 当我们希望输出的实际上是一个离散的场合, 或者输出是一个序列的时候, 直接用GAN是不合时宜的. 另外, 让判别器通过部分序列的数据来判断数据的真假似乎也有问题(虽然我没感觉出啥问题).
一个具体的实例便是生成视频, 视频的帧与帧之间是具有关联性的, 其是一个(C imes T imes H imes W)的数据, 当然可以直接利用3D的卷积去处理, 但这意味着, 我们将(T, H, W)放在一个尺度之上, 这显然是不合适的. 所以作者的想法是, 将一个生成器分开成两个生成器, 分别为时域生成器(G_0)和图片生成器(G_1).
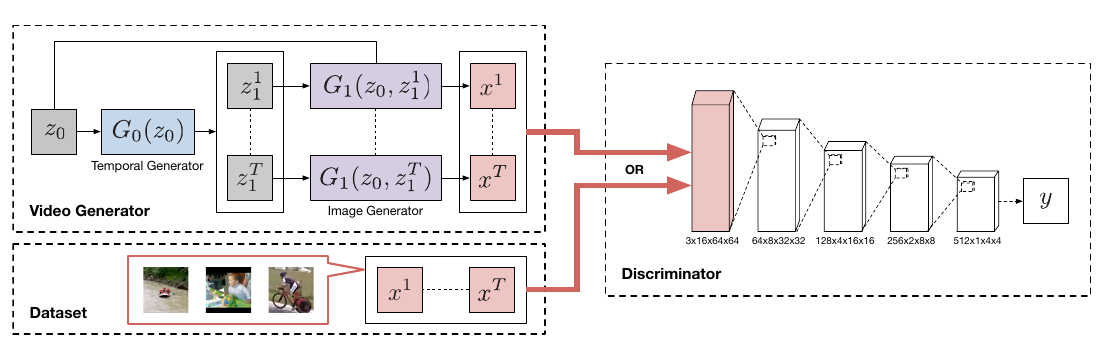
(G_0)接受一个噪声(z_0)生成一组时域的变量(z_1^1, z_1^2, ldots, z_1^T), 然后(G_1)同时接受(z_0, z_1)生成一组图片. 这比直接用一个生成器看起来要靠谱的多, 当然感觉上还是有点困难的. 余下的工作就是普通的GAN的工作了.
实际上本文还有另外一个创新点, 但是印象中之后还会有更好的解决办法, 这里也就不提了.