爬虫固定套路
1.提取数据(1.找到需要爬取的url,通过http请求获取html页面)
2.解析数据(1.数据筛选,2.数据过滤,3.获取有效数据) 最难搞的就是这一步,因为你要去分析解析人家前端页面Html的格式,这里也就是爬虫功放战的主要战场
3.数据入库
一、提取数据
1.找到需要爬取页面的url
2.下载html


/// <summary> /// 下载html /// http://tool.sufeinet.com/HttpHelper.aspx /// HttpWebRequest功能比较丰富,WebClient使用比较简单 /// WebRequest /// /// </summary> /// <param name="url"></param> /// <returns></returns> public static string DownloadHtml(string url, Encoding encode) { string html = string.Empty; try { HttpWebRequest request = HttpWebRequest.Create(url) as HttpWebRequest;//模拟请求 request.Timeout = 30 * 1000;//设置30s的超时 request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36"; //request.UserAgent = "User - Agent:Mozilla / 5.0(iPhone; CPU iPhone OS 7_1_2 like Mac OS X) App leWebKit/ 537.51.2(KHTML, like Gecko) Version / 7.0 Mobile / 11D257 Safari / 9537.53"; request.ContentType = "text/html; charset=utf-8";// "text/html;charset=gbk";// //request.Host = "search.yhd.com"; //如果请求标头用request.*** 找不出来 就用heades添加 //request.Headers.Add("Cookie", @"newUserFlag=1; guid=YFT7C9E6TMFU93FKFVEN7TEA5HTCF5DQ26HZ; gray=959782; cid=av9kKvNkAPJ10JGqM_rB_vDhKxKM62PfyjkB4kdFgFY5y5VO; abtest=31; _ga=GA1.2.334889819.1425524072; grouponAreaId=37; provinceId=20; search_showFreeShipping=1; rURL=http%3A%2F%2Fsearch.yhd.com%2Fc0-0%2Fkiphone%2F20%2F%3Ftp%3D1.1.12.0.73.Ko3mjRR-11-FH7eo; aut=5GTM45VFJZ3RCTU21MHT4YCG1QTYXERWBBUFS4; ac=57265177%40qq.com; msessionid=H5ACCUBNPHMJY3HCK4DRF5VD5VA9MYQW; gc=84358431%2C102362736%2C20001585%2C73387122; tma=40580330.95741028.1425524063040.1430288358914.1430790348439.9; tmd=23.40580330.95741028.1425524063040.; search_browse_history=998435%2C1092925%2C32116683%2C1013204%2C6486125%2C38022757%2C36224528%2C24281304%2C22691497%2C26029325; detail_yhdareas=""; cart_cookie_uuid=b64b04b6-fca7-423b-b2d1-ff091d17e5e5; gla=20.237_0_0; JSESSIONID=14F1F4D714C4EE1DD9E11D11DDCD8EBA; wide_screen=1; linkPosition=search"); //request.Headers.Add("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"); //request.Headers.Add("Accept-Encoding", "gzip, deflate, sdch"); //request.Headers.Add("Referer", "http://list.yhd.com/c0-0/b/a-s1-v0-p1-price-d0-f0-m1-rt0-pid-mid0-kiphone/"); //Encoding enc = Encoding.GetEncoding("GB2312"); // 如果是乱码就改成 utf-8 / GB2312 //如何自动读取cookie request.CookieContainer = new CookieContainer();//1 给请求准备个container using (HttpWebResponse response = request.GetResponse() as HttpWebResponse)//发起请求 { if (response.StatusCode != HttpStatusCode.OK) { logger.Warn(string.Format("抓取{0}地址返回失败,response.StatusCode为{1}", url, response.StatusCode)); } else { try { //string sessionValue = response.Cookies["ASP.NET_SessionId"].Value;//2 读取cookie StreamReader sr = new StreamReader(response.GetResponseStream(), encode); html = sr.ReadToEnd();//读取数据 sr.Close(); } catch (Exception ex) { logger.Error(string.Format($"DownloadHtml抓取{url}失败"), ex); html = null; } } } } catch (System.Net.WebException ex) { if (ex.Message.Equals("远程服务器返回错误: (306)。")) { logger.Error("远程服务器返回错误: (306)。", ex); html = null; } } catch (Exception ex) { logger.Error(string.Format("DownloadHtml抓取{0}出现异常", url), ex); html = null; } return html; }
通过谷歌浏览器f12-newwork-name第一个页面-Headers 找到里面需要的信息 像什么cookie 请求状态之类
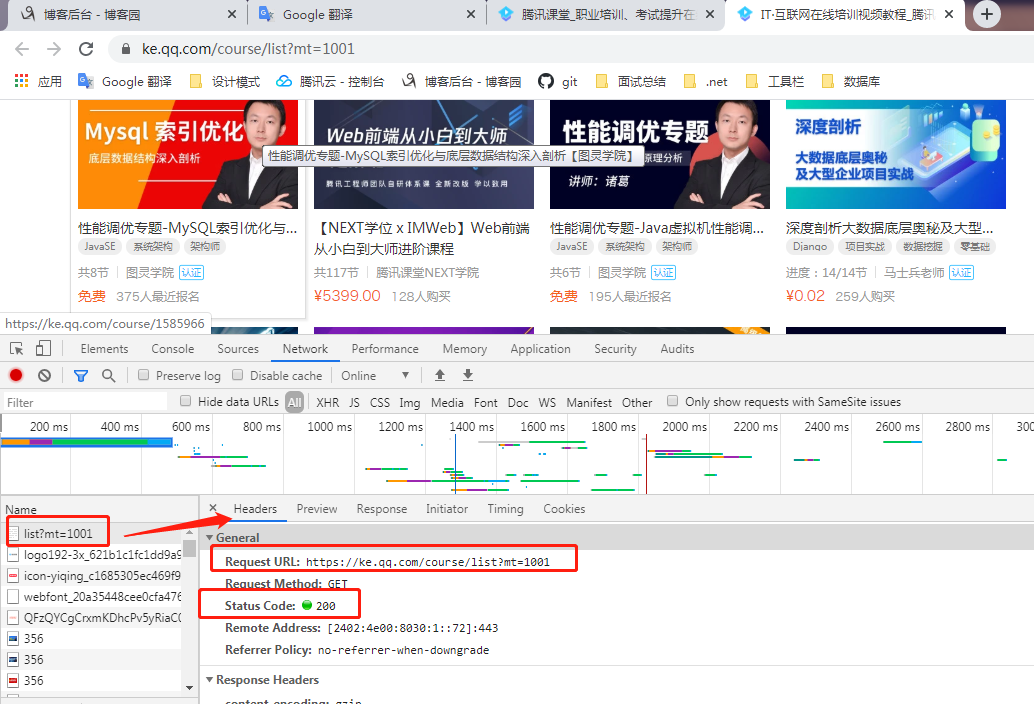
3.获取到有效信息
//定制爬虫 public void Show(string url) { //1.获取某个网站页面的url string strHtml = HttpHelper.DownloadUrl(url); //2.加载html文档 HtmlDocument document = new HtmlDocument(); document.LoadHtml(strHtml); //3.获取xpath string liPath = "/html/body/section[1]/div/div[@class='market-bd market-bd-6 course-list course-card-list-multi-wrap js-course-list']/ul/li"; //4, HtmlNodeCollection liNodes = document.DocumentNode.SelectNodes(liPath); foreach (var node in liNodes) { Console.WriteLine(); Console.WriteLine(); Console.WriteLine("************************************************"); HtmlDocument lidocument = new HtmlDocument(); lidocument.LoadHtml(node.OuterHtml); string aPath = "//*/a[1]"; HtmlNode classANode = lidocument.DocumentNode.SelectSingleNode(aPath); string aHref = classANode.Attributes["href"].Value; Console.WriteLine($"课程Url:{aHref}"); string Id = classANode.Attributes["data-id"].Value; Console.WriteLine($"课程Id:{Id}"); string imgPath = "//*/a[1]/img"; HtmlNode imgNode = lidocument.DocumentNode.SelectSingleNode(imgPath); string imgUrl = imgNode.Attributes["src"].Value; Console.WriteLine($"ImageUrl:{imgUrl}"); string namePaths = "//*/h4/a[1]"; HtmlNode nameNode = lidocument.DocumentNode.SelectSingleNode(namePaths); string name = nameNode.InnerText; Console.WriteLine(name); Console.WriteLine($"课程名称:{name}"); //腾讯课堂上的价格就是使用了js算法的一种爬虫防御方式 // courseEntity.Price = new Random().Next(100, 10000); count = count + 1; } }
#region 分页抓取 private void GetPageCourseData() { //1. 确定总页数 //2. 分别抓取每一页的数据 //3. 分析 过滤 清洗 //4. 入库 //1.获取URl TencentCategoryEntity category11 = null; //2.加载html string strHtml = HttpHelper.DownloadUrl(category11.Url); HtmlDocument document = new HtmlDocument(); document.LoadHtml(strHtml); //3.解析Xpath string pagePath = "/html/body/section[1]/div/div[@class='sort-page']/a[@class='page-btn']"; HtmlNodeCollection pageNodes = document.DocumentNode.SelectNodes(pagePath); int pageCount = 1; //获取分页最大的页数 if (pageNodes != null) { pageCount = pageNodes.Select(a => int.Parse(a.InnerText)).Max(); } List<CourseEntity> courseList = new List<CourseEntity>(); //4.分析解析筛选数据 for (int pageIndex = 1; pageIndex <= pageCount; pageIndex++) { Console.WriteLine($"******************************当前是第{pageIndex}页数据************************************"); string pageIndexUrl = $"{category11.Url}&page={pageIndex}"; List<CourseEntity> courseEntities = GetPageIndeData(pageIndexUrl); courseList.AddRange(courseEntities); } //这里获取到分页的总数据就可以做入库了 把list转实体然后插库 var listarror = courseList; } private List<CourseEntity> GetPageIndeData(string url) { //获取li标签里面的数据 // 先获取所有的Li // 然后循环获取li中的有效数据 string strHtml = HttpHelper.DownloadUrl(url); HtmlDocument document = new HtmlDocument(); document.LoadHtml(strHtml); string liPath = "/html/body/section[1]/div/div[@class='market-bd market-bd-6 course-list course-card-list-multi-wrap js-course-list']/ul/li"; HtmlNodeCollection liNodes = document.DocumentNode.SelectNodes(liPath); List<CourseEntity> courseEntities = new List<CourseEntity>(); foreach (var node in liNodes) { CourseEntity courseEntity = GetLiData(node); courseEntities.Add(courseEntity); } return courseEntities; } public class CourseEntity : BaseModel { public long CourseId { get; set; } public int CategoryId { get; set; } //类别Id public string Title { get; set; } public decimal Price { get; set; } public string Url { get; set; } public string ImageUrl { get; set; } } /// <summary> /// 当我们把这些数据获取到以后,那就应该保存起来 /// </summary> /// <param name="node"></param> private CourseEntity GetLiData(HtmlNode node) { CourseEntity courseEntity = new CourseEntity(); //从这里开始 HtmlDocument document = new HtmlDocument(); document.LoadHtml(node.OuterHtml); string aPath = "//*/a[1]"; HtmlNode classANode = document.DocumentNode.SelectSingleNode(aPath); string aHref = classANode.Attributes["href"].Value; courseEntity.Url = aHref; Console.WriteLine($"课程Url:{aHref}"); string Id = classANode.Attributes["data-id"].Value; Console.WriteLine($"课程Id:{Id}"); courseEntity.CourseId = long.Parse(Id); string imgPath = "//*/a[1]/img"; HtmlNode imgNode = document.DocumentNode.SelectSingleNode(imgPath); string imgUrl = imgNode.Attributes["src"].Value; courseEntity.ImageUrl = imgUrl; Console.WriteLine($"ImageUrl:{imgUrl}"); string namePaths = "//*/h4/a[1]"; HtmlNode nameNode = document.DocumentNode.SelectSingleNode(namePaths); string name = nameNode.InnerText; courseEntity.Title = name; Console.WriteLine($"课程名称:{name}"); courseEntity.Price = new Random().Next(100, 10000); //关于腾讯课堂上的课程价格抓取 这是一个进阶内容 通过普通方式搞不了(他有一个自己的算法) return courseEntity; } #endregion
4.判断页面Ajax请求 谷歌浏览器f12 network 选择XHR 筛选出来的就是ajax请求

多线程爬虫
List<Action> actions = new List<Action>(); foreach (TencentCategoryEntity category in categoryquery) { //1.模拟http请求 //2.加载html文档 //3.解析自己需要的数据 //开启多个线程爬取 actions.Add(new Action(自己爬取的方法); } //需要控制数量 //为什么,线程数量也是需要调度的,就像员工多了 管理人员管理起来更费事,反而影响性能 ParallelOptions options = new ParallelOptions(); options.MaxDegreeOfParallelism = 10; //控制了最大的线程数量是10 个线程 Parallel.Invoke(options, actions.ToArray()); //Parallel 表示有多少个委托 就开启多少个线程