倒排索引和文本Analysis
1、倒排索引
概念:也叫反向索引,反向索引则是通过value找key
结构:

类比现代汉语字典:Term->词语 ;Term Dictionary ->词典;Term Index ->目录索引
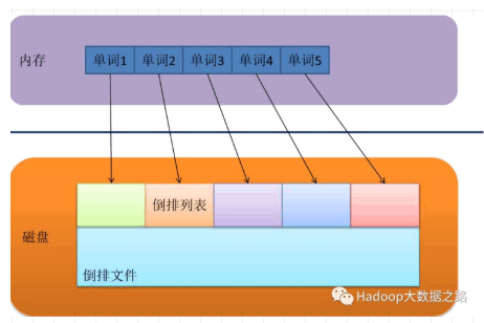
Term(单词):一段文本经过分析器分析输出的一串单词,单个词叫做Term
Term Dictionary(单词字典):维护Term,为Term的集合
Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引
Posting List(倒排列表):某个单词所在的文档ID、单词位置、词频(Term出现的次数)、偏移量(offset)等,每条记录称为一个倒排项(Posting)。
例:

2、文本分析Analysis
2.1、文本分析
概念:将文本(如任何电子邮件的正文或者一篇文章)转换为标记或术语的过程。
构成:分析器由一个分词器(Tokenizer)和零个或多个标记过滤器(TokenFilter)组成,也可以包含零个或多个字符过滤器(Character Filter)。
作用:分析器(Analyzer)的作用就是分析(Analyse),用于把传入Lucene的文档数据转化为倒排索引,把文本处理成可被搜索的词。
过程:字符过滤器对分析文本进行过滤和处理,分词器接收并分割成标记流,标记过滤器对标记流进行过滤处理,处理后的标记流存储在倒排索引中;
ElasticSearch引擎在收到用户的查询请求时,会使用分析器对查询条件进行分析,根据分析的结构,重新构造查询,以搜索倒排索引,完成全文搜索请求,
字符过滤器(Char Filter)
|
名称 [Char Filter] |
类型 |
作用 |
|
映射字符过滤器(Mapping) |
mapping |
映射字符替换 |
|
HTML标记字符过滤器(HTML Strip) |
html_strip |
去除HTML标记 |
|
模式替换字符过滤器(Pattern Replace) |
pattern_replace |
正则替换 |
分词器(Tokenizer)
|
名称 [Tokenizer] |
类型 |
作用 |
适用语言 |
|
标准分词(Standard) |
standard |
使用Unicode文本分割算法对文档进行分词 |
大多数欧洲语言 |
|
edge ngram |
edgeNGram |
|
|
|
keyword |
keyword |
不分词 |
|
|
字母分词器(Letter) |
letter |
在非字母位置上分割文本 |
大多数欧洲语言 |
|
空格分词器(Whitespace) |
Whitespace |
在空格处分割文本 |
|
|
小写分词器(Lowercase) |
lowercase |
在非字母位置上分割文本,并转换成小写 |
|
|
ngram |
ngram |
|
|
|
pattern |
pattern |
定义分隔符的正则表达式 |
|
|
uax email url analyzer |
uax_url_email |
不拆分url和email |
|
|
经典分词器 (Classic) |
classic |
基于语法规则对文本进行分词,对英语文档分词非常有用,在处理首字母缩写,公司名称,邮件地址和Internet主机名上效果非常好。 |
英语 |
|
path hierarchy analyzer |
path_hierarchy |
处理类似/path/to/somthing样式的字符串 |
|
内置分析器(Analyzer)
配置分析器
{
"settings": {
"analysis": {
"analyzer": {
"std_english": {
"type": "standard",
"stopwords": "_english_"
}
}
}
},
}
预定义分析器
|
名称 [Analyzer] |
类型 |
组成 |
|
Standard |
Standard |
标准分词器(Standard Tokenizer),,小写标记过滤器(Lower Case Token Filter)和停用词标记过滤器(Stopwords Token Filter)组成。参数stopwords用于初始化停用词列表,默认是空的。 |
|
Simple |
Simple |
Lower Case Tokenizer |
|
Whitespace |
Whitespace |
Whitespace Tokenizer |
|
Stop |
Stop |
Lower Case Tokenizer 支持排除stop 词,默认使用是_english_ stop words |
|
Keyword |
Keyword |
不分词,内容整体作为一个token (not_analyzed) |
|
Pattern |
|
正则表达式分词,默认匹配W+ |
|
Language |
Lang |
各种语言 |
|
Fingerprint |
|
指纹 |
|
自定义分析器 |
Custom |
Tokenizer,Filter,Char_filter自定义组合 |
2.2、配置示例
1、增加分词器的分词类型
PUT /my_index/_mapping/my_type?update_all_types
{
"properties": {
"title": {
"type": "string",
"analyzer": "english"
}
}
}
2、fielddata字段设置
对分词的field执行聚合,排序或在脚本访问操作时,必须将fielddata设置为true
PUT my_index/_mapping
{
"properties": {
"my_field": {
"type": "text",
"fielddata": true
}
}
}
3、指定词指定分析器
例:对title设置standard分析器
PUT my_index
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "standard"
}
}
}
}