一、静态数据、流数据 以及 批量计算、实时计算
大数据分类两类:静态数据和动态数据(流数据)。针对这两类数据的计算模式分别是批量计算和实时计算。
静态数据:历史数据持久化存储在系统里,这类数据的特点是数据量大、数量有限(数据的时间区间是确定的)。例如企业为了支持决策分析而构建的数据仓库系统。
对这类数据进行分析处理,采用的计算模式是批量计算,如hadopp的MapReduce,这种计算不太在意计算的时长,可以在很充裕的时间里对海量数据慢慢进行批量计算来得到有用的信息。
流数据:数据以流形式持续到达,这类数据的特点是大量、快速、时变,它在时间和数量上都是无限的,随着时间的流逝,这类数据的价值往往会降低。流
因此,对这类数据的处理通常对实时性要求比较高,希望能实时得到计算结果,响应时间一般在秒级,采用的计算模式为实时计算。数据经过处理后,一部分进入数据库成为静态数据,其他部分则会被直接丢弃。流计算中一个比较流行的计算框架就是后面会着重介绍的Storm。
总结:批量计算主要解决的是静态数据的批量处理,即处理的是已经存储到位的数据,一般重视数据的总吞吐量;而流计算的数据是源源不断流入的,在计算启动的时候数据一般并没有到位,流处理更加关注数据处理的延时。
关于大数据领域的一些框架对比,看到过一篇比较好的文章:大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
二、流计算处理流程
流计算处理流程一般包括:数据实时采集、实时计算、实时查询。
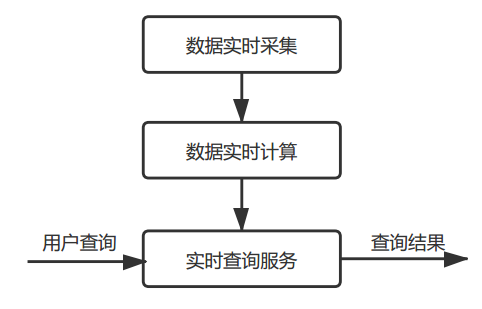
流计算的数据处理流程

传统数据处理流程
在传统数据处理中,都是对旧的数据进行的处理,用户提出查询请求的时候再去处理;而流计算中,无论用户是否发起查询请求,都会实时处理新数据,将计算结果进行存储,当用户发起请求时再进行查询。
2-1 数据实时收集
这个阶段就是从多个数据源获取格式不同、实施产生的一系列海量数据,这个过程我们得保证数据的实时性、低延迟和可靠稳定。数据采集的一般架构:
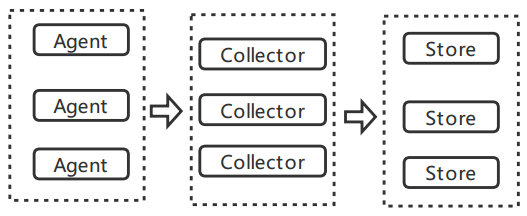
agent:主动采集数据,并推送到Collector
collector:接收多个agent的数据,并实现有序、可靠、高性能的转发。
store:对collector转发的来数据进行存储,但是一般的流计算中不存储,而是直接发送给流计算平台进行实时计算。
2-2 数据实时计算
在这个阶段对实时收集来的数据进行分析计算,并实时反馈计算结果,对于处理候后的数据,可能进行存储以便以后的分析计算,也可能直接丢弃。

2-3 实时查询服务
经过流计算框架得出的结果可以供用户进行实时查询、展示、存储。跟传统的查询需要用户主动查询不同,流计算的实时查询服务不断更新,并把结果主动推送给用户。当然了,你可以在传统的数据处理系统中进行定时查询,但是即时是定时主动上报的查询结果,也是基于对预先存储好的静态“历史”数据的查询结果,而流处理系统则是对实时数据的一个查询,强调的是数据的“实时性”,处理的都是最新的数据,也就是说,你的查询结果依据的都是“当前”数据。