0~8 基本上来自MPI 教程https://mpitutorial.com/tutorials/mpi-introduction/zh_cn/
9 是一些注意事项和实际问题
0. mpicxx && mpirun
//编译
mpicc 是编译C程序的
mpicxx 是编译C++程序的
-g 允许使用调试器
-Wall 显示警告(W大写)
-o outfile.o 编译出可执行的文件,文件名为outfile.o
-02 告诉编译器对代码进行优化
//运行,其中n指定创建的进程数
mpirun -n 4 ./mpi_hello.o
MPI可以跨主机在进程间通信,传统的MPI函数只能用于传输主机内存,且传递之前必须在CPU和GPU之间进行拷贝;
CUDA-aware MPI则可以将GPU中的内容直接传递到MPI函数上,不需要通过主机内存中转数据。
1. Mpi--hello world
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// 初始化 MPI 环境
MPI_Init(NULL, NULL);
// 通过调用以下方法来得到所有可以工作的进程数量
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// 得到当前进程的秩
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// 得到当前进程的名字
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
// 打印一条带有当前进程名字,秩以及
// 整个 communicator 的大小的 hello world 消息。
printf("Hello world from processor %s, rank %d out of %d processors
",
processor_name, world_rank, world_size);
// 释放 MPI 的一些资源
MPI_Finalize();
}
第一步,mpi初始化,所有 MPI 的全局变量或者内部变量都会被创建,比如一个通讯器 communicator 会根据所有可用的进程被创建出来(进程是我们通过 mpi 运行时的参数指定的),然后每个进程会被分配独一无二的秩 rank。
MPI_Init(
int* argc,
char*** argv)
之后主要用到了两个函数,一个是MPI_Comm_size,它会返回communicator 的大小,也就是 communicator中可用的进程数量。例子中使用的MPI_COMM_WORLD这个communicator是MPI生成的,其中包含了当前任务中所有的进程。
另一个是MPI_Comm_rank,它会返回 communicator 中当前进程的rank,每个进程会以此得到一个从0开始递增的数字作为rank值,rank 值主要是用来指定发送或者接受信息时对应的进程。
MPI_Comm_size(
MPI_Comm communicator,
int* size)
而MPI_Get_processor_name的作用是会得到当前进程实际跑的时候所在的处理器名字。
MPI_Get_processor_name(
char* name,
int* name_length)
最后MPI_Finalize是用来清理 MPI 环境的,调用之后就没有MPI函数可以被调用了。
2. MPI发送和接收方法
MPI_Send(
void* data, //数据缓存
int count, //数据的数量
MPI_Datatype datatype, //数据类型
int destination, //发送方或者接收方的rank
int tag, //信息的tag
MPI_Comm communicator) //使用的communicator
MPI_Recv(
void* data, //接受的数据缓存地址
int count, //发送数据的数量
MPI_Datatype datatype, //发送数据类型
int source, //发送方或者接收方的rank,目的地进程号
int tag, //信息的tag
MPI_Comm communicator,//使用的communicator,即MPI进程组所在的通信域
MPI_Status* status) //接受到的信息的状态,返回状态信息,以使用 MPI_STATUS_IGNORE 忽略
首先有一个基本的前提,A进程发送给B进程的过程:数据打包到缓存->所有数据打包到message中->B接受message->确认发送方为A进程->发送成功。
当A需要传递很多不同的message的时候,就会额外指定tag,当B只接受到某些tag的时候,其他tag的message会被缓存起来。
现在看MPI_Send会发送count个元素,而MPI_Recv最多接受count个元素。
注意,MPI_Send 和 MPI_Recv 会阻塞直到数据传递完成。
3. 动态传递信息
MPI_Status结构体可以作为参数传递给MPI_Recv,则当该操作完成之后结构体就会得到一些状态信息,主要如下:
以一个 MPI_Status stat 变量为例子,
-
发送方的秩,在结构体中的
MPI_SOURCE元素中; -
message的tag,在元素
MPI_TAG中; -
message的长度,需要使用
MPI_Get_Count得到,函数原型如下:
MPI_Get_count(
MPI_Status* status, //状态结构体
MPI_Datatype datatype,//message的数据类型
int* count)//已接受的数据的数目
事实证明,MPI_Recv 可以将 MPI_ANY_SOURCE 用作发送端的秩,将 MPI_ANY_TAG 用作消息的标签。 在这种情况下,MPI_Status 结构体是找出消息的实际发送端和标签的唯一方法。 此外,并不能保证 MPI_Recv 能够接收函数调用参数的全部元素。 相反,它只接收已发送给它的元素数量(如果发送的元素多于所需的接收数量,则返回错误。) MPI_Get_count 函数用于确定实际的接收量。
3.1 状态信息查询例子
程序将随机数量的数字发送给接收端,然后接收端找出发送了多少个数字。
const int MAX_NUMBERS = 100;
int numbers[MAX_NUMBERS];
int number_amount;
if (world_rank == 0) {
// Pick a random amount of integers to send to process one
srand(time(NULL));
number_amount = (rand() / (float)RAND_MAX) * MAX_NUMBERS;
// Send the amount of integers to process one
MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD);
printf("0 sent %d numbers to 1
", number_amount);
} else if (world_rank == 1) {
MPI_Status status;
// Receive at most MAX_NUMBERS from process zero
MPI_Recv(numbers, MAX_NUMBERS, MPI_INT, 0, 0, MPI_COMM_WORLD,
&status);
// After receiving the message, check the status to determine
// how many numbers were actually received
MPI_Get_count(&status, MPI_INT, &number_amount);
// Print off the amount of numbers, and also print additional
// information in the status object
printf("1 received %d numbers from 0. Message source = %d, "
"tag = %d
",
number_amount, status.MPI_SOURCE, status.MPI_TAG);
}
3.2 使用 MPI_Probe 找出消息大小(在实际接受到message之前)
可以使用 MPI_Probe 在实际接收消息之前查询消息大小,原型如下:
MPI_Probe(
int source,
int tag,
MPI_Comm comm,
MPI_Status* status)
除了不接收消息外,与 MPI_Recv 类似,MPI_Probe 将阻塞具有匹配标签和发送端的消息。 当消息可用时,它将填充 status 结构体。 然后,用户可以使用 MPI_Recv 接收实际的消息,具体例子如下:
int number_amount;
if (world_rank == 0) {
const int MAX_NUMBERS = 100;
int numbers[MAX_NUMBERS];
// Pick a random amount of integers to send to process one
srand(time(NULL));
number_amount = (rand() / (float)RAND_MAX) * MAX_NUMBERS;
// Send the random amount of integers to process one
MPI_Send(numbers, number_amount, MPI_INT, 1, 0, MPI_COMM_WORLD);
printf("0 sent %d numbers to 1
", number_amount);
} else if (world_rank == 1) {
MPI_Status status;
// Probe for an incoming message from process zero
MPI_Probe(0, 0, MPI_COMM_WORLD, &status);
// When probe returns, the status object has the size and other
// attributes of the incoming message. Get the message size
MPI_Get_count(&status, MPI_INT, &number_amount);
// Allocate a buffer to hold the incoming numbers
int* number_buf = (int*)malloc(sizeof(int) * number_amount);
// Now receive the message with the allocated buffer
MPI_Recv(number_buf, number_amount, MPI_INT, 0, 0,
MPI_COMM_WORLD, MPI_STATUS_IGNORE);
printf("1 dynamically received %d numbers from 0.
",
number_amount);
free(number_buf);
}
4. 随机游走问题的并行化
并行的问题中,首要任务就是在各个进程之间划分域,随机游走问题的一维域大小为max-min+1,如果每次只能整数步长,则可以容易的将其划分为相等的块,比如下图所示:
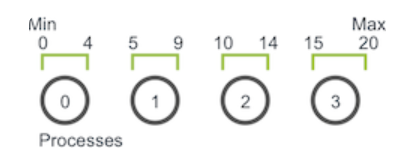
当游走器在进程0上移动了6步(假设每次步长为1),当其到4的时候就到了进程0的边界,此时进程0必须和进程1交流游走器的信息,然后进程1接受游走器继续移动,直到移动总数达到6为止,以此类推。
问题分析:
可以使用 MPI_Send 和 MPI_Recv 对组织代码。 理清楚程序的一些初步特征和功能:
- 明确每个进程在域中的部分。
- 每个进程初始化 N 个 walker,所有这些 walker 都从其局部域的第一个值开始。
- 每个 walker 都有两个相关的整数值:当前位置和剩余步数。
- Walkers 开始遍历该域,并传递到其他进程,直到完成所有移动。
- 当所有 walker 完成时,该进程终止。
代码如下:
#include <mpi.h>
#include <iostream>
#include <string>
#include <time.h>
#include <vector>
#include <cstdio>
using namespace std;
/*
* 随机游走并行程序流程如下:
初始化 walkers.
使用 walk 函数使 walkers 前进。
发出 outgoing_walkers 向量中的所有的 walkers。
将新接收的 walkers 放入 incoming_walkers 向量中。
重复步骤 2 到 4,直到所有 walkers 完成。
*/
typedef struct
{
/* data */
int location;
int num_steps_left_in_work;
}Walker;
void decompose_domain(int domain_size,int world_rank,int world_size,int* subdomain_start,int *subdomain_size);
void init_walkers(int num_walkers_pre_process,int max_walk_size,
int subdomain_start,int subdomain_size,
vector<Walker>*incoming_walkers);
void walk(Walker * walker, int subdomain_start,int subdomain_size, int domain_size, vector<Walker>* outgoing_walkers);
void send_outgoing_walkers(vector<Walker>*outgoing_walkers, int world_rank, int world_size);
void receive_incoming_walkers(vector<Walker>* incoming_walkers, int world_rank, int world_size);
int main(int argc, char** argv)
{
int domain_size;
int max_walk_size;
int num_walkers_per_proc;
if (argc < 4) {
cerr << "Usage: random_walk domain_size max_walk_size "
<< "num_walkers_per_proc" << endl;
exit(1);
}
domain_size = atoi(argv[1]);
max_walk_size = atoi(argv[2]);
num_walkers_per_proc = atoi(argv[3]);
// 初始化 MPI 环境
MPI_Init(NULL, NULL);
// 得到当前进程的 rank 以及整个 communicator 的大小
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
srand(time(NULL) * world_rank);
int subdomain_start=0,subdomain_size=0;
vector<Walker>incoming_walkers, outgoing_walkers;
//首先找到当前进程所在的子域
decompose_domain(domain_size , world_rank, world_size,&subdomain_start,&subdomain_size);
//在子域中初始化游走器
init_walkers(num_walkers_per_proc, max_walk_size,
subdomain_start,subdomain_size,&incoming_walkers);
cout << "Process " << world_rank << " initiated " << num_walkers_per_proc
<< " walkers in subdomain " << subdomain_start << " - "
<< subdomain_start + subdomain_size - 1 << endl;
int maximum_sends_recvs = max_walk_size / (domain_size / world_size) + 1;
//决定游走器完成与否
for (int m = 0; m < maximum_sends_recvs; m++)
{
//处理所有的incoming_walkers
for(int i=0;i< incoming_walkers.size(); i++)
{
walk(&incoming_walkers[i], subdomain_start, subdomain_size, domain_size, &outgoing_walkers);
}
cout << "Process " << world_rank << " sending " << outgoing_walkers.size()
<< " outgoing walkers to process " << (world_rank + 1) % world_size
<< endl;
if (world_rank % 2 == 0) {
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
} else {
receive_incoming_walkers(&incoming_walkers, world_rank,
world_size);
send_outgoing_walkers(&outgoing_walkers, world_rank,
world_size);
}
cout << "Process " << world_rank << " received " << incoming_walkers.size()
<< " incoming walkers" << endl;
}
cout << "Process " << world_rank << " done" << endl;
MPI_Finalize();
return 0;
}
void decompose_domain(int domain_size,int world_rank,int world_size,int* subdomain_start,int *subdomain_size)
{
if(world_size > domain_size)
{
// Don't worry about this special case. Assume the domain
// size is greater than the world size.
MPI_Abort(MPI_COMM_WORLD, 1);
}
*subdomain_start = domain_size / world_size *world_rank;
*subdomain_size = domain_size / world_size;
//最后一个块包含了最后剩余的所有部分
if(world_rank == world_size - 1)
{
//give remainder to last process
*subdomain_size+= domain_size% world_size;
}
}
//初始化游走器,采用子域的边界,并将游走器添加到当前活跃的游走器(队列)中
void init_walkers(int num_walkers_per_proc,int max_walk_size,
int subdomain_start,int subdomain_size,
vector<Walker>*incoming_walkers)
{
Walker walker_now;
for(int i=0; i< num_walkers_per_proc ; i++)
{
//把游走器放在子域的中间,随机剩余步数
walker_now.location = subdomain_start;
walker_now.num_steps_left_in_work = (rand() / (float)RAND_MAX) *max_walk_size;
incoming_walkers->push_back(walker_now);
}
}
//定义一个游走器移动函数;
//负责使 walkers 前进,直到完成移动为止。 如果超出局部域范围,则将其添加到 outgoing_walkers vector 中。
void walk(Walker * walker, int subdomain_start,int subdomain_size, int domain_size, vector<Walker>* outgoing_walkers)
{
while(walker->num_steps_left_in_work>0)
{
if(walker->location == subdomain_start + subdomain_size)
{
//如果游走器到了整个域的边界就将其放到起始位置
if(walker->location == domain_size)
{
walker->location=0;
}
outgoing_walkers->push_back(*walker);
break;
}else{
--walker->num_steps_left_in_work;
++walker->location;
}
}
}
//发送穿过边界的游走器
void send_outgoing_walkers(vector<Walker>*outgoing_walkers, int world_rank, int world_size)
{
//把越过边界的游走器以MPI_BYTE的形式发送给下一个接受的进程,最后一个进程会发送给进程0
MPI_Send((void*)outgoing_walkers->data(),
outgoing_walkers->size()*sizeof(Walker), MPI_BYTE, (world_rank + 1)% world_size, 0, MPI_COMM_WORLD);
//清除当前进程中越过边界的游走器,因为都发送给下一个进程了
outgoing_walkers->clear();
}
//接受别的进程发送过来的游走器
void receive_incoming_walkers(vector<Walker>* incoming_walkers, int world_rank, int world_size)
{
MPI_Status status;
//接受之前的进程发送来的数据,如果当前进程为进程0的话,就是接受来自最后一个进程的数据;
int incoming_rank= (world_rank==0)?world_size-1 : world_rank-1;
MPI_Probe(incoming_rank,0,MPI_COMM_WORLD,&status);
//重新分配incoming_walkers的空间,依据MPI_Probe得到的数据大小
int incoming_walkers_size;
MPI_Get_count(&status, MPI_BYTE,&incoming_walkers_size);
incoming_walkers->resize(incoming_walkers_size / sizeof(Walker));
MPI_Recv((void*)incoming_walkers->data(), incoming_walkers_size,MPI_BYTE, incoming_rank,0, MPI_COMM_WORLD,MPI_STATUS_IGNORE);
}
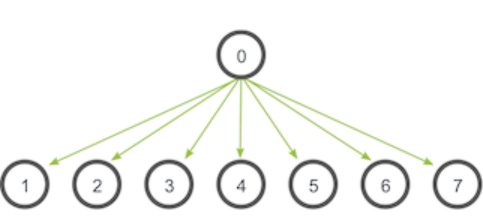
5. 多对一和一对多
MPI_Barrier用来同步不同的进程;
MPI_Bcast来进行广播,广播的目的是把同样一份数据传递给一个communicator里面的所有其他进程,广播的主要用途之一是把用户的输入传递给一个分布式程序,或者把一些配置参数传递给所有的进程。广播的通信模式如下:
函数原型如下,根节点和接受节点可能完成的工作不相同,但是都需要调用MPI_Bcast来实现广播。当根节点(在我们的例子是节点0)调用 MPI_Bcast 函数的时候,data 变量里的值会被发送到其他的节点上。当其他的节点调用 MPI_Bcast 的时候,data 变量会被赋值成从根节点接受到的数据。
MPI_Bcast(
void* data, //根节点发送的数据,其他节点接受的数据
int count,
MPI_Datatype datatype,
int root,
MPI_Comm communicator)
理论上可以用在 MPI_Send 和 MPI_Recv 基础上进行了一层包装实现MPI_Bcast ,只需要判断一个world_rank即可,但是这样的效率极低(如果只是从根节点发送数据的话),高效的话(NDN?)
5.1 MPI_Scatter 的介绍
MPI_Scatter 的操作会设计一个指定的根进程,根进程会将数据发送到 communicator 里面的所有进程。MPI_Bcast 和 MPI_Scatter 的主要区别很小但是很重要。MPI_Bcast 给每个进程发送的是同样的数据,然而 MPI_Scatter 给每个进程发送的是一个数组的一部分数据。下图进一步展示了这个区别。
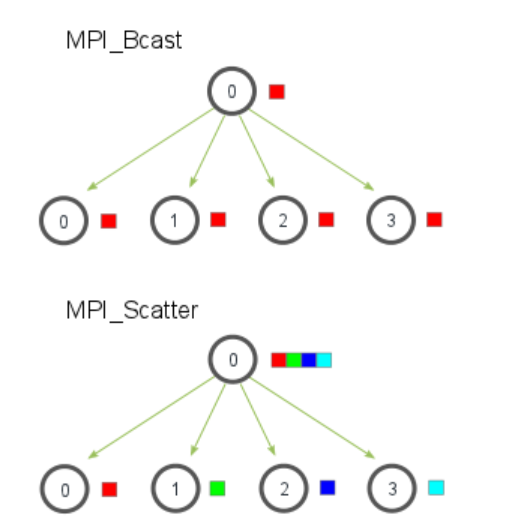
MPI_Scatter(
void* send_data, //发送数据数组
int send_count, //发送给每个进程的数据数量
MPI_Datatype send_datatype, //发送数据的数据类型
void* recv_data, //接收缓存,用于缓存recv_count个recv_datatype数据类型的元素
int recv_count,
MPI_Datatype recv_datatype,
int root, //root 和 communicator 分别指定开始分发数组的根进程以及对应的communicator
MPI_Comm communicator)
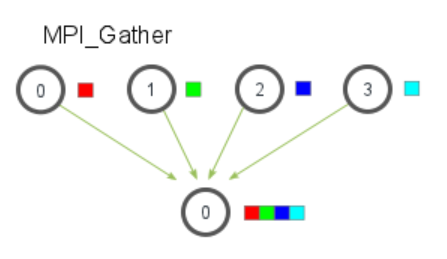
5.2 MPI_Gather 的介绍
MPI_Gather 跟 MPI_Scatter 是相反的,如下图所示:
MPI_Gather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
int root,
MPI_Comm communicator)
在MPI_Gather中,只有根进程需要一个有效的接收缓存。所有其他的调用进程可以传递NULL给recv_data。另外,别忘记recv_count参数是从每个进程接收到的数据数量,而不是所有进程的数据总量之和。这一点对MPI初学者来说经常容易搞错。
5.3 使用使用 MPI_Scatter 和 MPI_Gather 来计算平均数
- 在根进程(进程0)上生成一个充满随机数字的数组。
- 把所有数字用
MPI_Scatter分发给每个进程,每个进程得到的同样多的数字。 - 每个进程计算它们各自得到的数字的平均数。
- 根进程收集所有的平均数,然后计算这个平均数的平均数,得出最后结果。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <mpi.h>
#include <assert.h>
// Creates an array of random numbers. Each number has a value from 0 - 1
float *create_rand_nums(int num_elements) {
float *rand_nums = (float *)malloc(sizeof(float) * num_elements);
assert(rand_nums != NULL);
int i;
for (i = 0; i < num_elements; i++) {
rand_nums[i] = (rand() / (float)RAND_MAX);
}
return rand_nums;
}
// Computes the average of an array of numbers
float compute_avg(float *array, int num_elements) {
float sum = 0.f;
int i;
for (i = 0; i < num_elements; i++) {
sum += array[i];
}
return sum / num_elements;
}
int main(int argc, char** argv) {
if (argc != 2) {
fprintf(stderr, "Usage: avg num_elements_per_proc
");
exit(1);
}
int num_elements_per_proc = atoi(argv[1]);
// Seed the random number generator to get different results each time
srand(time(NULL));
MPI_Init(NULL, NULL);
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Create a random array of elements on the root process. Its total
// size will be the number of elements per process times the number
// of processes
float *rand_nums = NULL;
if (world_rank == 0) {
rand_nums = create_rand_nums(num_elements_per_proc * world_size);
}
// For each process, create a buffer that will hold a subset of the entire
// array
float *sub_rand_nums = (float *)malloc(sizeof(float) * num_elements_per_proc);
assert(sub_rand_nums != NULL);
// Scatter the random numbers from the root process to all processes in
// the MPI world
MPI_Scatter(rand_nums, num_elements_per_proc, MPI_FLOAT, sub_rand_nums,
num_elements_per_proc, MPI_FLOAT, 0, MPI_COMM_WORLD);
// Compute the average of your subset
float sub_avg = compute_avg(sub_rand_nums, num_elements_per_proc);
// Gather all partial averages down to the root process
float *sub_avgs = NULL;
if (world_rank == 0) {
sub_avgs = (float *)malloc(sizeof(float) * world_size);
assert(sub_avgs != NULL);
}
MPI_Gather(&sub_avg, 1, MPI_FLOAT, sub_avgs, 1, MPI_FLOAT, 0, MPI_COMM_WORLD);
// Now that we have all of the partial averages on the root, compute the
// total average of all numbers. Since we are assuming each process computed
// an average across an equal amount of elements, this computation will
// produce the correct answer.
if (world_rank == 0) {
float avg = compute_avg(sub_avgs, world_size);
printf("Avg of all elements is %f
", avg);
// Compute the average across the original data for comparison
float original_data_avg =
compute_avg(rand_nums, num_elements_per_proc * world_size);
printf("Avg computed across original data is %f
", original_data_avg);
}
// Clean up
if (world_rank == 0) {
free(rand_nums);
free(sub_avgs);
}
free(sub_rand_nums);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
}
6. 多对多广播–MPI_Allgather
MPI_Allgather会收集所有数据到所有进程上,如下图所示,
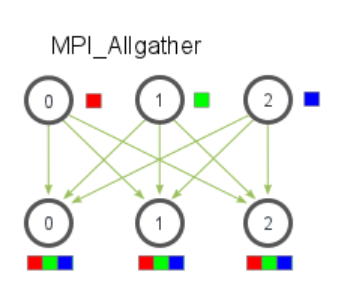
函数原型如下,但是MPI_Allgather不需要root这个参数来指定根节点。
MPI_Allgather(
void* send_data,
int send_count,
MPI_Datatype send_datatype,
void* recv_data,
int recv_count,
MPI_Datatype recv_datatype,
MPI_Comm communicator)
使用MPI_Allgather来计算平均数,主要区别如下,这样每个进程都可以拿到最后的结果。
// Gather all partial averages down to all the processes
float *sub_avgs = (float *)malloc(sizeof(float) * world_size);
MPI_Allgather(&sub_avg, 1, MPI_FLOAT, sub_avgs, 1, MPI_FLOAT,
MPI_COMM_WORLD);
// Compute the total average of all numbers.
float avg = compute_avg(sub_avgs, world_size);
7. 使用MPI计算并行排名–使用MPI_Gather和MPI_Scatter
问题概述:每一个进程都在其本地内存中存储了一个数,所有进程中存储的数字构成了一个数字集合(set of numbers),目的就是对这个集合进行并行排序。
算法流程如下,图示中的进程(标记为0到3)开始时有四个数字—— 5、2、7和4。然后,并行排名算法算出进程1在数字集合中的排名为0(即第一个数字),进程3排名为1,进程0排名为2,进程2排在整个数字集合的最后。
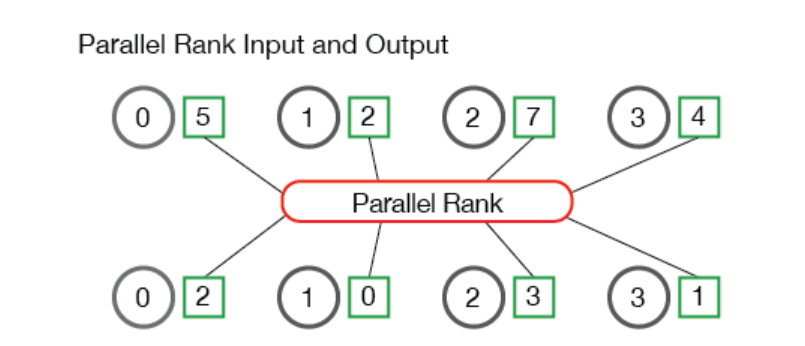
首先定义好需要的工具和函数,主要目的是在每个进程上取一个数字,并返回其相对于所有其他进程中的数字的排名和一些通讯信息,具体如下:TMPI_Rank 把 send_data 作为缓冲区,其中包含一个类型为 datatype 的数字。 recv_data 在每个进程中只接收一个整数,即 send_data 的排名。comm 变量是进行排名的通讯器。
TMPI_Rank(
void *send_data,
void *recv_data,
MPI_Datatype datatype,
MPI_Comm comm)
7.1 将所有数字收集到一个进程中进行排序
// 为进程0的TMPI_Rank收集数字。为MPI的数据类型分配空间
// 对进程0返回 void * 指向的缓冲区
// 对所有其他进程返回NULL
void *gather_numbers_to_root(void *number, MPI_Datatype datatype,
MPI_Comm comm) {
int comm_rank, comm_size;
MPI_Comm_rank(comm, &comm_rank);
MPI_Comm_size(comm, &comm_size);
// 在根进程上分配一个数组
// 数组大小取决于所用的MPI数据类型
int datatype_size;
MPI_Type_size(datatype, &datatype_size);
void *gathered_numbers;
if (comm_rank == 0) {
gathered_numbers = malloc(datatype_size * comm_size);
}
// 在根进程上收集所有数字
MPI_Gather(number, 1, datatype, gathered_numbers, 1,
datatype, 0, comm);
return gathered_numbers;
}
8. non-blocking API交换数据
/*
– MPI_Isend(...)与MPI_Irecv(...)
– I:immediate
– 使用CUDA-aware MPI实现时,可以直接把设备内存指针传给MPI函数
– 使用传统MPI时,需要先将设备内存拷贝到相应的主机内存中
*/
MPI_Irecv(r_buf, size, MPI_CHAR, other_proc, 100,
MPI_COMM_WORLD, &recv_request);
MPI_Isend(s_buf, size, MPI_CHAR, other_proc, 10, MPI_COMM_WORLD, &send_request);
MPI_Waitall(1, &send_request, &reqstat);
MPI_Waitall(1, &recv_request, &reqstat);
9. Summary & parallel particle tracing
随机游走问题已经体现了一个并行问题的基本框架,基本步骤如下:
- 划分数据域
- 设定好每个进程管理的数据域以及需要做的事情
- 进程之间的数据交换(异步需加锁,同步可能死锁)
- 数据合并
其中进程之间的数据交换(同步)是比较关键的地方,正好最近有涉及parallel particle tracing,简单记录一些问题。
particle tracing在流场可视化中是常见的方法之一,比如pathline(粒子随时间流动);
首先是根据给定的数据集进行数据域的划分,划分之后每个进程对应一个数据子域;
其基本流程是随机撒seeding points—tracing—exchange—combine data—finish;
第一步是在整个数据域中随机撒点作为最开始的seeding points,该过程结束之后可能一部分进程会得到粒子,另一部分没有粒子;
第二步是得到粒子的进程开始开始trace,并将trace得到的pathline进行保存;
第三步是将该条pathline最后跨过该进程的数据子域边界的粒子交换给下一个进程;
第四步是将所有的pathline进程合并,其效果和https://mpitutorial.com/tutorials/point-to-point-communication-application-random-walk/zh_cn/这个类似;
9.1 Some questions
但是实际我在实现的时候还是需要的不少的问题,当然也可能是我对MPI的理解不够深;
首先是第一步中进程得到粒子,这里很明显不能使用同步操作,因为对于每个进程而言,只知道有人会发送给我随机的粒子,但是不知道谁会发给我;所以点对点通信是不现实的,只能是异步通信或者广播通信(比如MPI_Allgather)。
第二个问题是当一个进程trace结束之后需要保存已经得到的pathline,并发送越界粒子,这同样涉及同步问题,如果采用异步通信,也就是把发送越界粒子这个动作异步的话,假如不加锁就会出现发送缓冲区被刷新导致发送粒子不全的问题,也就是该进程还没有发送完上一次的越界粒子的时候又进行了一次trace,从而刷新了缓冲区。
第三个问题是结束条件,当没有粒子的情况下就结束,因为粒子在流场中进行流动的时候,它一定会在某处停下来,当粒子越过整个数据域的边界或者它停下来不动了,这个粒子形成的pathline就终止了,当所有粒子都终止了,整个过程就结束了。所以还需要能够让所有进程都得到这个情况,所以Allreduce就很合适。
第四个问题是pathline的合并,当粒子越界也就意味着该条pathline并没有终止,所以越界粒子前后两段pathline是属于同一条的两段,在最后的合并结果上,它们必须被合并在同一条上pathline,所以这个信息必须也被传递以方便合并。同时由于同一个粒子只能出现在一个地方,所以只需要给一个标记来标识一段pathline属于那一条即可,因为前后关系已经被指定了,即被接受的分段一定是按顺序被接受的。
第五个问题就是接受数据和整合,单独开一个进程来接受所有的数据明显更好操作,只需要使用Gather操作就可以完成,然后根据给定的标记来进行分段pathline整合即可。
9.2 Other questions
MPI的共享内存只能对单节点操作,因为共享内存基于虚拟内存实现,如果虚拟地址不能操作同一段物理内存,共享内存就无法起作用。