初学python,记录学习过程。
新上榜,七日热门等同理。
此次主要为了学习python中对mongodb的操作,顺便巩固requests与BeautifulSoup。
点击,得到URL https://www.jianshu.com/trending/monthly?utm_medium=index-banner-s&utm_source=desktop
下拉,发现Ajax自动加载,F12观察请求。
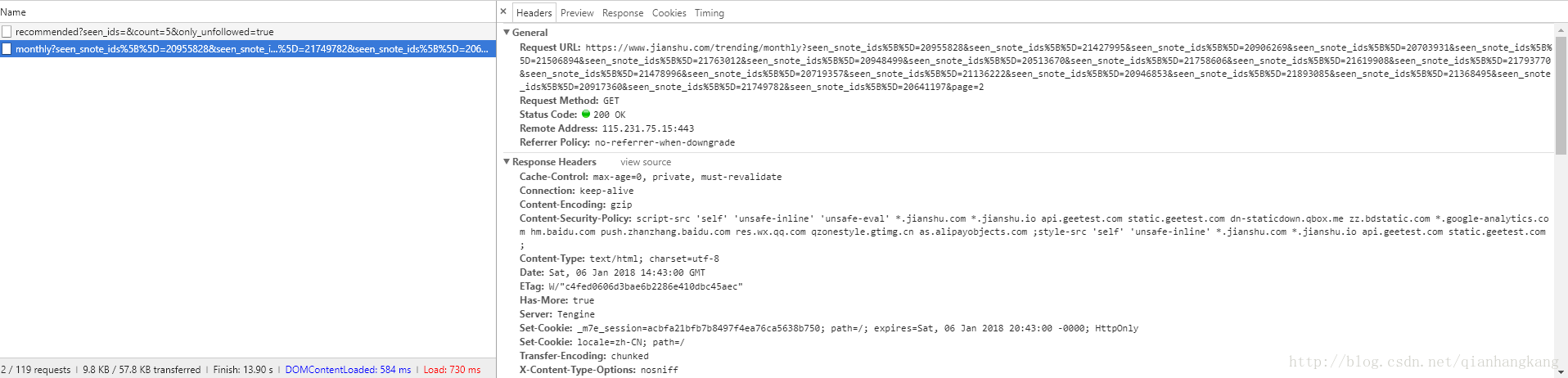
Ajax的请求为:https://www.jianshu.com/trending/monthly?seen_snote_ids%5B%5D=20955828&seen_snote_ids%5B%5D=21427995&seen_snote_ids%5B%5D=20906269&seen_snote_ids%5B%5D=20703931&seen_snote_ids%5B%5D=21506894&seen_snote_ids%5B%5D=21763012&seen_snote_ids%5B%5D=20948499&seen_snote_ids%5B%5D=20513670&seen_snote_ids%5B%5D=21758606&seen_snote_ids%5B%5D=21619908&seen_snote_ids%5B%5D=21793770&seen_snote_ids%5B%5D=21478996&seen_snote_ids%5B%5D=20719357&seen_snote_ids%5B%5D=21136222&seen_snote_ids%5B%5D=20946853&seen_snote_ids%5B%5D=21893085&seen_snote_ids%5B%5D=21368495&seen_snote_ids%5B%5D=20917360&seen_snote_ids%5B%5D=21749782&seen_snote_ids%5B%5D=20641197&page=2
仔细观察发现中间存在众多重复的seen_snote_ids,不知啥用,那么去掉试试,将URL换成 https://www.jianshu.com/trending/monthly?page=2,发现OK,中间的seen_snote_ids参数对于请求结果没有影响,那么得到接口https://www.jianshu.com/trending/monthly?page=(1,2,3……),测试了下发现page=11就没了...并且一页加载20条文章。
OK,预习下mongodb在python中的操作。
1、需要用到 pymongo,怎么下载就不多说了,百度谷歌你看着办
2、开启mongodb,用配置文件启动。

顺便给出配置文件吧....
- #设置数据目录的路径
- dbpath = g:datadb
- #设置日志信息的文件路径
- logpath = D:MongoDBlogmongodb.log
- #打开日志输出操作
- logappend = true
- #在以后进行用户管理的时候使用它
- noauth = true
- #监听的端口号
- port = 27017
3、在python中使用,给出我当初参考的博客,我觉得蛮清晰明了了点击打开链接
最后,给出源代码
- #爬取简书上三十日榜并存入数据库中 mongodb
- import pymongo
- import requests
- from requests import RequestException
- from bs4 import BeautifulSoup
- client = pymongo.MongoClient('localhost', 27017)
- db = client.jianshu # mldn是连接的数据库名 若不存在则自动创建
- TABLENAME = 'top'
- def get_jianshu_monthTop(url):
- try:
- response = requests.get(url)
- if response.status_code ==200:
- return response.text
- print(url + ',visit error')
- return None
- except RequestException:
- return None
- def parse_html(html):
- base_url = 'https://www.jianshu.com'
- soup = BeautifulSoup(html, "html.parser")
- nickname = [i.string for i in soup.select('.info > .nickname')];
- span = soup.find_all('span',class_ = 'time')
- time = []
- for i in span:
- time.append(i['data-shared-at'][0:10])##截取,例2017-12-27T10:11:11+08:00截取成2017-12-27
- title = [i.string for i in soup.select('.content > .title')]
- url = [base_url+i['href'] for i in soup.select('.content > .title')]
- intro = [i.get_text().strip() for i in soup.select('.content > .abstract')]
- readcount = [i.get_text().strip() for i in soup.select('.meta > a:nth-of-type(1)')]
- commentcount = [i.get_text().strip() for i in soup.select('.meta > a:nth-of-type(2)')]
- likecount = [i.get_text().strip() for i in soup.select('.meta > span:nth-of-type(1)')]
- tipcount = [i.get_text().strip() for i in soup.select('.meta > span:nth-of-type(2)')]
- return zip(nickname,time,title,url,intro,readcount,commentcount,likecount,tipcount)
- #将数据存到mongodb中
- def save_to_mongodb(item):
- if db[TABLENAME].insert(item):
- print('save success:',item)
- return True
- print('save fail:',item)
- return False
- #将数据存到results.txt中
- def save_to_file(item):
- file = open('result.txt', 'a', encoding='utf-8')
- file.write(item)
- file.write(' ')
- file.close()
- def main(offset):
- url = """https://www.jianshu.com/trending/monthly?page=""" + str(offset)
- html = get_jianshu_monthTop(url)
- for i in parse_html(html):
- item = {
- '作者':i[0],
- '发布时间':i[1],
- '标题':i[2],
- 'URL':i[3],
- '简介':i[4],
- '阅读量':i[5],
- '评论量':i[6],
- '点赞量':i[7],
- '打赏量':i[8]
- }
- save_to_mongodb(item)
- save_to_file(str(item))
- if __name__ == '__main__':
- for i in range(1,11):
- main(i)
OK,最后给出效果图
TIPS:右键,新标签页打开图片,查看高清大图:)

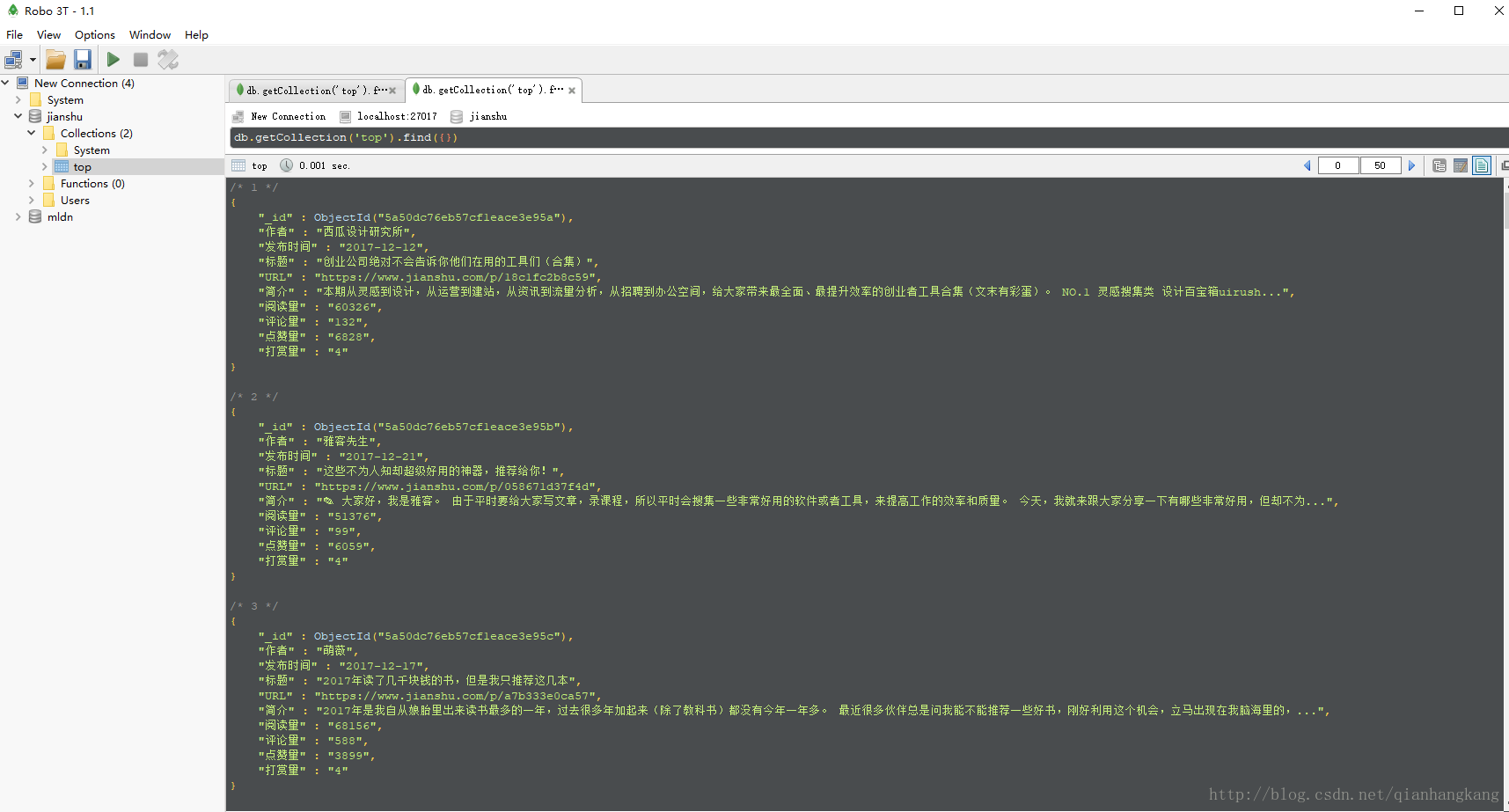
抓了共157条数据。。。