Numpy是python科学计算的基础包,为python提供快速的数组处理能力,也可以作为在算法之间传递数据的容器
安装相关软件包
安装需要的包
pip3 install numpy/pandas/mtaplotlib/ipython/scipy/xlrd/lxml/basemap/pymogo/PyQt/statsmodels/PyTables
验证ipython
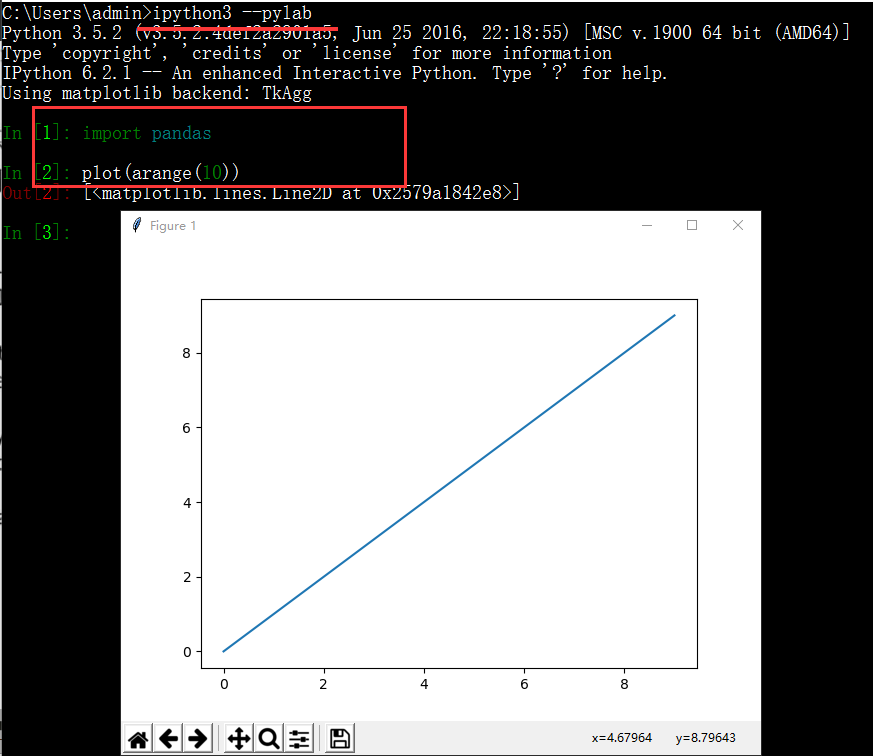
Numpy
NumPy的主要对象是同质多维数组。它是一张表,所有元素(通常是数字)的类型都相同,并通过正整数元组索引。在NumPy中,维度称为轴。轴的数目为秩rank。
ndarray 是一个数据多维容器,所以,其中所有的元素类型必须是相同的,每个数组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对象)
Numpy的ndarray:一种多维数组对象
例如:
3D空间中的点的坐标[1, 2, 1]是rank为1的数组,因为它具有一个轴。该轴的长度为3。在下面所示的示例中,数组的rank为2(它是2维的)。
第一维度(轴)的长度为2,第二维度的长度为3。
[[ 1., 0., 0.],[ 0., 1., 2.]]
NumPy的数组的类称为ndarray。别名为array
实例代码与说明:
In [48]: import numpy as np In [49]: a = np.arange(15).reshape(3,5) #reshape可以理解为设置维度,3行5列 In [50]: a Out[50]: array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [10, 11, 12, 13, 14]])
数组的维度shape。这是一个整数的元组,表示每个维度中数组的大小。
对于具有n行和m列的矩阵,shape将是(n,m)。 因此,shape元组的长度就是rank或维度的个数ndim。
In [51]: a.shape Out[51]: (3, 5) In [52]: a.ndim ##数组的轴(维度)的个数。在Python中,维度的数量被称为rank。 Out[52]: 2 In [58]: a.size ##数组元素的总数。这等于shape的元素的乘积。 Out[58]: 15 ##数组中每个元素的字节大小。例如,元素为float64类型的数组的itemsize为8(=64/8),而complex32类型的数组的comitemsize为4(=32/8)。它等于ndarray.dtype.itemsize。 In [53]: a.itemsize Out[53]: 8 In [54]: type(a) Out[54]: numpy.ndarray In [55]: b = np.array([6,7,8]) In [56]: b Out[56]: array([6, 7, 8])
创建数组
创建数组最简单的方法用array函数,array函数会为数组推断出一个合适的数据类型,数据类型保存在dtype对象中,例如
In [4]: data = [5,3,11,2.3,0] In [5]: arr1 = np.array(data) In [6]: arr1 Out[6]: array([ 5. , 3. , 11. , 2.3, 0. ]) In [7]: data2 = [[1,2,4,5],[5,6,7,8]] In [8]: arr2 = np.array(data2) In [9]: arr2 Out[9]: array([[1, 2, 4, 5], [5, 6, 7, 8]]) In [10]: arr1.dtype Out[10]: dtype('float64') In [11]: arr2.dtype Out[11]: dtype('int32')
python内置函数range函数的数组版arange
In [12]: np.arange(15)
Out[12]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])

ndarray的数据类型 dtype
dtype 用于说明数组数据类型的对象
dtype含有ndarray将一块内存解释为特定数据类型所需的信息,语法
arr3 = np.array([数组],dtype=np.float64) #数组类型
通过astype方法转化dtype
arr1 = np.array([5,3,11,2.3,0]) float_arr = arr1.astype(np.float64)
如果数组元素都为字符串可用astype转换为数值类型,调用astype会创建出一个新的数组,即使新数组和老数组dtype相同
如果浮点型数组转换为整数,小数点后面的将会被截断,并且不会四舍五入
数组间的转换
数组A = 。。 数组B = 。。 数组A.astype(数组B.dtype)
数组运算(矢量化)
数组与标量的算数运算应用到每个值
In [13]: arr1 Out[13]: array([ 5. , 3. , 11. , 2.3, 0. ]) In [14]: arr1 * arr1 Out[14]: array([ 25. , 9. , 121. , 5.29, 0. ]) In [15]: arr1 - arr1 Out[15]: array([ 0., 0., 0., 0., 0.]) In [16]: 1 / arr1 C:Program FilesPython35Scriptsipython3:1: RuntimeWarning: divide by zero encountered in true_divide Out[16]: array([ 0.2 , 0.33333333, 0.09090909, 0.43478261, inf]) In [17]: 1 / arr1 ** 0.5 C:Program FilesPython35Scriptsipython3:1: RuntimeWarning: divide by zero encountered in true_divide Out[17]: array([ 0.4472136 , 0.57735027, 0.30151134, 0.65938047, inf]) In [18]:
索引和切片
一维数组
In [25]: arr = np.array([4,3,6,7,2,7,9,8]) #一维数组与python的列表取值方式一样 In [26]: arr Out[26]: array([4, 3, 6, 7, 2, 7, 9, 8]) In [27]: arr[0] Out[27]: 4 In [28]: arr[1] Out[28]: 3 In [29]: arr[3:6] #取值索引为 3,4,5的值 Out[29]: array([7, 2, 7]) In [30]: arr[3:6] = 11 #赋值为所有 In [31]: arr Out[31]: array([ 4, 3, 6, 11, 11, 11, 9, 8])
二维数组
各索引位置上的值不再是一个标量,而是一个一维数组(python里的列表)
In [33]: arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]]) #shape为(3,3)
In [34]: np.ndim(arr2d) #二维数组查看方法 Out[34]: 2 In [35]: arr2d[2] Out[35]: array([7, 8, 9])
所以,可以对单个元素进行递归访问
In [35]: arr2d[2] Out[35]: array([7, 8, 9]) In [36]: arr2d[2][0] Out[36]: 7
二维数组索引方式
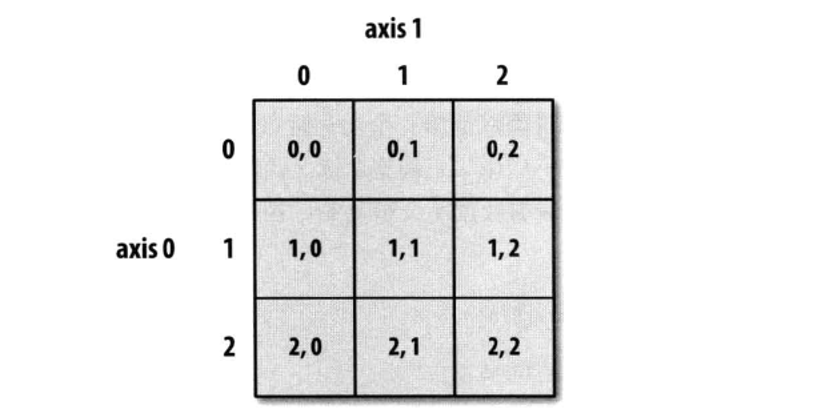
多维数组索引
In [37]: arr3d = np.array([[[1,2,3],[4,5,6]],[[7,8,9,],[10,11,12]]]) In [38]: arr3d Out[38]: array([[[ 1, 2, 3], [ 4, 5, 6]], [[ 7, 8, 9], [10, 11, 12]]]) In [39]: arr3d[0] #取第一个值 Out[39]: array([[1, 2, 3], [4, 5, 6]]) In [40]: arr3d[0] = 42 #给元素赋值 In [41]: arr3d[0] Out[41]: array([[42, 42, 42], [42, 42, 42]]) In [42]: arr3d #新的数组 Out[42]: array([[[42, 42, 42], [42, 42, 42]], [[ 7, 8, 9], [10, 11, 12]]]) In [43]: arr3d[1,0] #多维数组元素取值,等同于 arr3d[1][0] Out[43]: array([7, 8, 9])
切片索引
二维数组切片
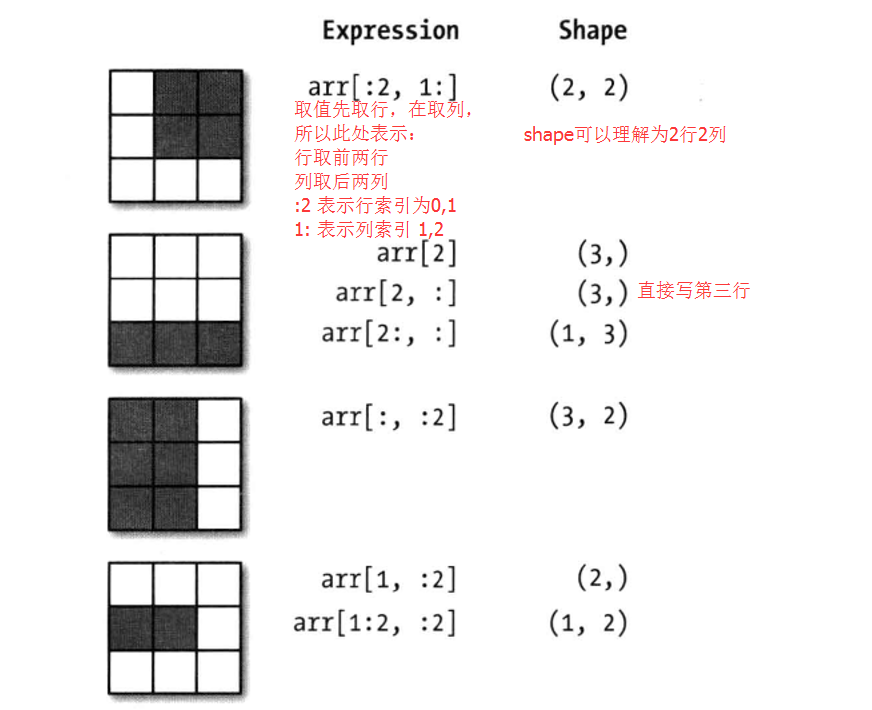
ndarry的切片语法跟python列表的取值差不多,例
In [45]: arr2d Out[45]: array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) In [46]: arr2d[:2] Out[46]: array([[1, 2, 3], [4, 5, 6]]) #一次传入多个切片取值
In [47]: arr2d[:2,1:] #取前两行的值,再取其索引为1及以后的值
Out[47]:
array([[2, 3],
[5, 6]])
#对高维数组切片
arr2d[:,:1] #算作是语法
布尔型索引
布尔型数组可用于数组索引,布尔型数组的长度必须与被索引的轴的长度一致
In [48]: names = np.array(['Bob','Joe','will','Bob','will','Joe','Joe']) In [49]: data = randn(7,4) In [50]: names Out[50]: array(['Bob', 'Joe', 'will', 'Bob', 'will', 'Joe', 'Joe'], dtype='<U4') In [51]: data Out[51]: array([[ 0.10178629, -1.07043495, 0.39996302, 0.86182796], [-0.4353786 , -0.03595137, -0.50582915, 0.72286381], [-0.08335713, -0.88924282, -0.34335741, -1.11461641], [-0.69570247, 2.41029154, -0.62120433, -0.54820488], [-0.56408913, -0.43663855, 0.00482595, 0.36397724], [-0.32140443, -1.84666651, 0.11527445, -2.36827836], [-1.72703212, 0.13889588, 0.93259899, -0.92023785]])
In [57]: names == 'Bob'
Out[57]: array([ True, False, False, True, False, False, False], dtype=bool)
In [58]: data[names=='Bob'] #根据名称的索引取data里的值
Out[58]:
array([[ 0.10178629, -1.07043495, 0.39996302, 0.86182796],
[-0.69570247, 2.41029154, -0.62120433, -0.54820488]])
In [59]: data[names=='Bob',2:] #取值,与切片整数混合使用
Out[59]:
array([[ 0.39996302, 0.86182796],
[-0.62120433, -0.54820488]])
#选择非值操作,可使用!= 或者 - 符号表示非值,例:
In [62]: names != 'Bob'
Out[62]: array([False, True, True, False, True, True, True], dtype=bool)
In [64]: data[-(names == 'Bob')]
Out[64]:
array([[-0.4353786 , -0.03595137, -0.50582915, 0.72286381],
[-0.08335713, -0.88924282, -0.34335741, -1.11461641],
[-0.56408913, -0.43663855, 0.00482595, 0.36397724],
[-0.32140443, -1.84666651, 0.11527445, -2.36827836],
[-1.72703212, 0.13889588, 0.93259899, -0.92023785]])
#将data中的负值设置为0
In [69]: data[data<0]
Out[69]:
array([-1.07043495, -0.4353786 , -0.03595137, -0.50582915, -0.08335713,
-0.88924282, -0.34335741, -1.11461641, -0.69570247, -0.62120433,
-0.54820488, -0.56408913, -0.43663855, -0.32140443, -1.84666651,
-2.36827836, -1.72703212, -0.92023785])
In [70]: data[data<0] = 0
In [71]: data
Out[71]:
array([[ 0.10178629, 0. , 0.39996302, 0.86182796],
[ 0. , 0. , 0. , 0.72286381],
[ 0. , 0. , 0. , 0. ],
[ 0. , 2.41029154, 0. , 0. ],
[ 0. , 0. , 0.00482595, 0.36397724],
[ 0. , 0. , 0.11527445, 0. ],
[ 0. , 0.13889588, 0.93259899, 0. ]])
In [72]:
#通过一维布尔数组设置正行或整列的值
In [74]: data[names != 'Joe'] = 0
In [75]: data
Out[75]:
array([[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0.72286381],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0. , 0. ],
[ 0. , 0. , 0.11527445, 0. ],
[ 0. , 0.13889588, 0.93259899, 0. ]])
In [76]:
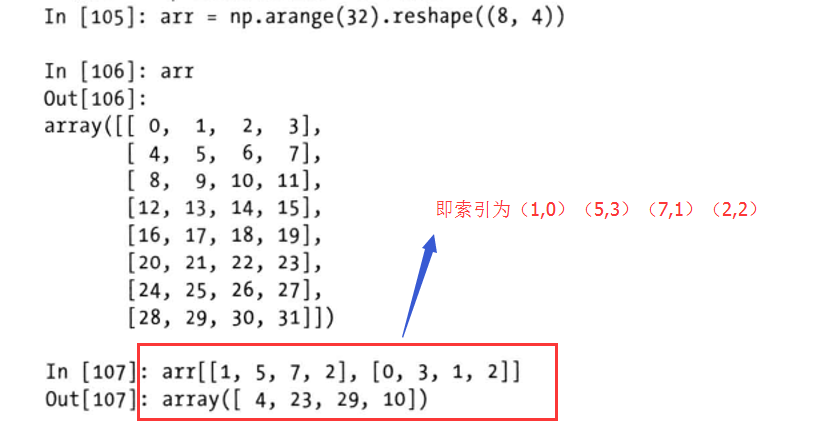
花式索引
花式索引是利用整数进行索引

一次性传入多个索引数组

数组转置和轴对换


通用函数




