垃圾回收:为了防止内存泄漏,对堆中死亡的对象进行清除,并回收相应空间的机制。
某些有GC机制的语言(Java, Python...),平时不会特别在意内存的分配和释放。但是对于C/C++等语言来说,稍有不慎就会造成Memory Leak/Double Frees/Use-after-frees等问题。
Garbage
垃圾顾名思义就是以后不再使用的对象。但是要确定一个对象是垃圾通常很难,所以我们认为不可达(没有被引用)对象就是垃圾,但是需要明确的是:许多可达对象也不再会使用,也是垃圾,但是这种垃圾我们无法回收,所以即使拥有GC机制的语言也很容易造成内存泄漏。
Reference Counting
Python/C++的shared_ptr等主要采用引用计数法,实现简单:
每个对象都与一个引用计数器cnt相关联,每当有一个引用指向该对象,++cnt;一个引用失效时,--cnt。当cnt==0时:Remove all outgoing references from that object,并且清理该对象。
由于每个cnt记录的是引用数,而不是可达的引用数,只关注自己的对象而没有全局的信息,循环引用的情况就无法被回收:

Mark-Sweep
Lua/Ruby等主要采用Mark-Sweep算法:
有一些位置是明确知道可达的:全局变量、栈中的变量以及寄存器中的变量等,这些区域作为root set,从root set出发可达的对象视为存活对象,不可达对象视为待回收对象。
- mark阶段目标是找到可达对象。
-- 将root set中的对象放入worklist;
-- 当worklist不空:
从worklist中移除一个对象;
如果该对象没有标记,标记它并且把从它出发的所有可达对象加入worklist。 - sweep阶段目标是回收死亡对象。
-- 对于所有已经分配的对象:
如果未标记,释放;
如果已经标记,为了下一次的GC,unmark。
有时候确实很难想象如此简洁的设计竟然是Lua 5.0之前采用的机制,不过工程上一条重要的原则就是:先完成、再完善。这个比较简单的GC实现过程可以参考自己动手写GC。
这种Naive的方式虽然简洁,但是却有很大的缺点:即mark和sweep阶段必须一口气执行完毕,不能分步骤进行,结果就是在进行GC时其他线程都必须挂起,也就是通常说的Stop The World。
原因在于:假如在mark完成后,新创建了若干对象,这些对象显然没有被标记,在本次的sweep阶段就会被清除,造成无法挽回的后果。
为了改进上述算法的时间和空间性能,Baker's algorithm应运而生:
每个分配的内存块只能属于四种状态之一:Marked(可达)/Enqueued(in the worklist)/Unknown(未处理)/Deallocated(已释放),维护4个双向链表保存4个状态的对象。
- 将root set中的所有对象移入enqueued链表;
- 当enqueued链表不空:
-- 将enqueued链表的对象移入marked链表;
-- 对于unknown链表中的被引用对象,移入enqueued链表。 - 合并unknown链表和Deallocated链表并释放,耗时(O(1));
- 将marked链表中的所有对象移入unknown链表,耗时(O(1))。
这样时间复杂度优化为runs in time proportional to the number of reachable objects.
Generational GC
分代收集的核心思想是将内存划分为若干代,每次新的对象总是被分在新生代,新生代没有空间时,做一次迅速的GC,之后将新生代中剩余的对象移入next generation,实在没有空间可用时,对整个内存进行一次GC。
Java的GC就是基于这种算法,新生代分为Eden和Survivor:
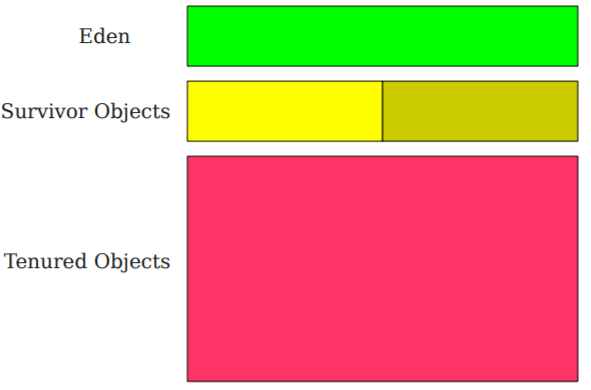
开始的分配都在eden中,满了之后做一次GC,将留下的对象移入survivor浅色区,具体过程可以参考文献中的200页。