背景介绍
构建一个大型混合云容器网络,首先需要考虑的是性能问题,还有容器网络架构是不是经过大规模验证,云厂商是不是有类似方案的选择,如何设计一个能支撑 5K 节点的容器网络呢?其实经过大规模验证的容器网络组件屈指可数,其中大名鼎鼎的 cilium 公开数据显示支持过单集群 5k node 规模,各大云厂商齐头并进支持 cilium ebpf。
本文将包括如下几部分:
- Kubernetes Pod 网络概览
- Kubernetes Service 网络概览
- 构建一个大型容器网络
阅读本文你将了解到我司容器网络的进化路线,从容器小集群成长为大集群的新一代容器网络架构;您还将发现老容器集群潜在的网络架构缺陷,除旧迎新恒久不变,一代更比一代强。
『深入容器』系列文章第一篇,请收藏与关注系列文章,欢迎加入我们。
1、Kubernetes Pod 网络概览
在使用 Kubernetes 编排应用时,您必须改变对应用和其主机的网络的思维方式。使用 Kubernetes 时,您需要考虑的是 Pod、Service 和外部客户端的通信方式,而不是主机或虚拟机的连接方式。
Kubernetes 的高级软件定义网络 (SDN) 支持在同一区域级集群中的不同地区之间路由和转发 Pod、Service、Node 的数据包。
IP 地址相关的术语
Kubernetes 网络模型在很大程度上依赖于 IP 地址。Service、Pod、容器和 Node 使用 IP 地址和端口进行通信。Kubernetes 提供不同类型的负载均衡,用于将流量定向到正确的 Pod。
相关术语:
- ClusterIP:分配给 Service 的 IP 地址,此地址会在 Service 的生命周期内保持不变
- Pod IP:分配给 Pod 的 IP 地址,大部分情况生命周期随 Pod 的销毁而终止
- Node IP:分配给节点的 IP 地址
几种经典容器网络模式
隧道封包模式: VxLan/IPIP/GRE ,通过tunnel隧道封包建立overlay 网络,实现Pod到Pod的通信。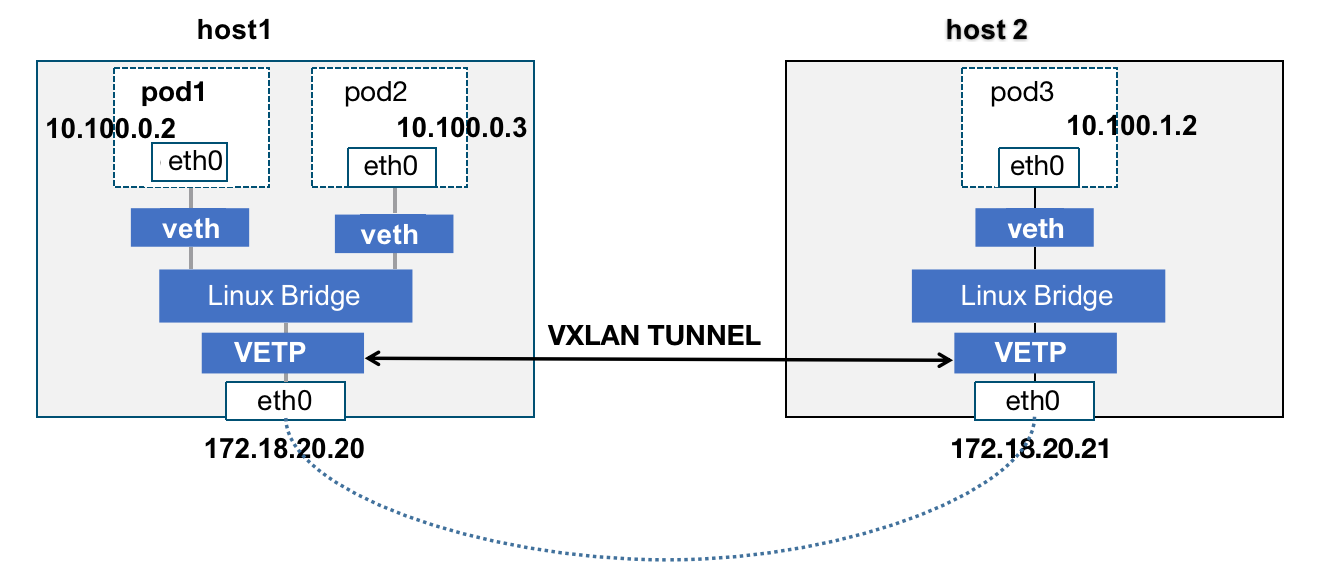
路由模式:通过映射目标容器网段和主机IP的关系,Pod 之间的通信数据包通过路由表转发到相应节点上。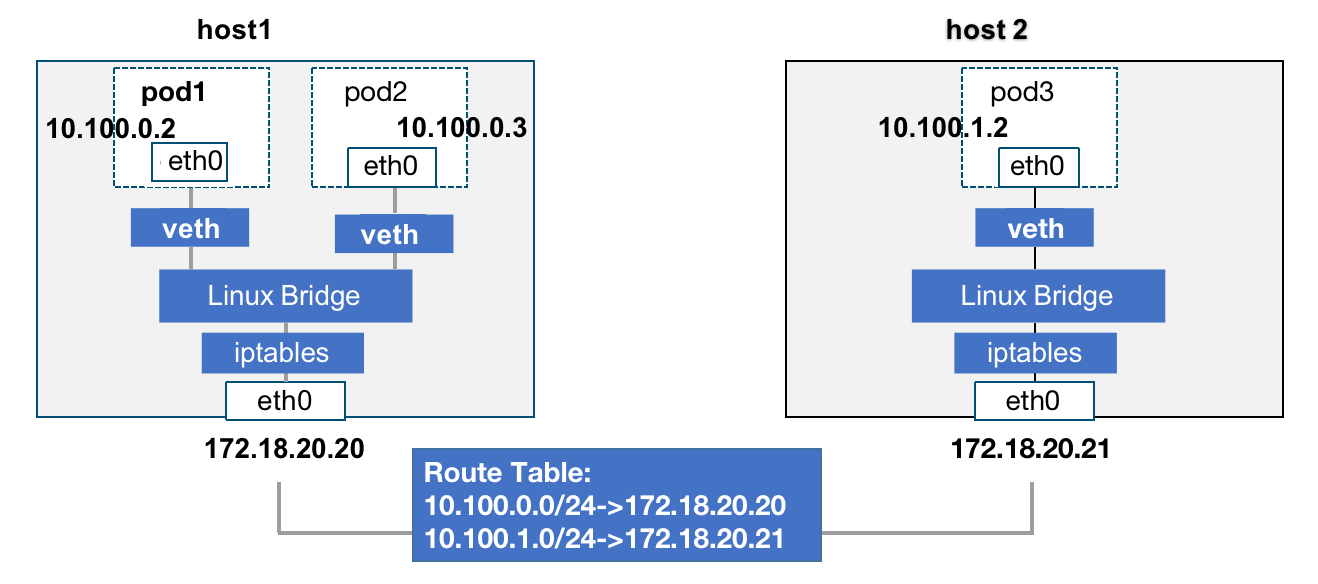
2、Kubernetes Service 网络概览
Kubernetes 的 Service 到底是个啥 ?其实 Kubernetes 的 Service 主要解决的是 Pod IP 短生命周期带来的问题,Service clutserIP 就是 node side Loadbalancer。
需要思考的问题:
- 当一个应用拥有多个 Pod 时如何去做负载均衡
- 会话保持如何去处理
- 某个容器销毁后短生命周期的 IP 变更如何去处理
下图显示了 Service 负载均衡的不同实现性能对比(数据来源于阿里云容器团队)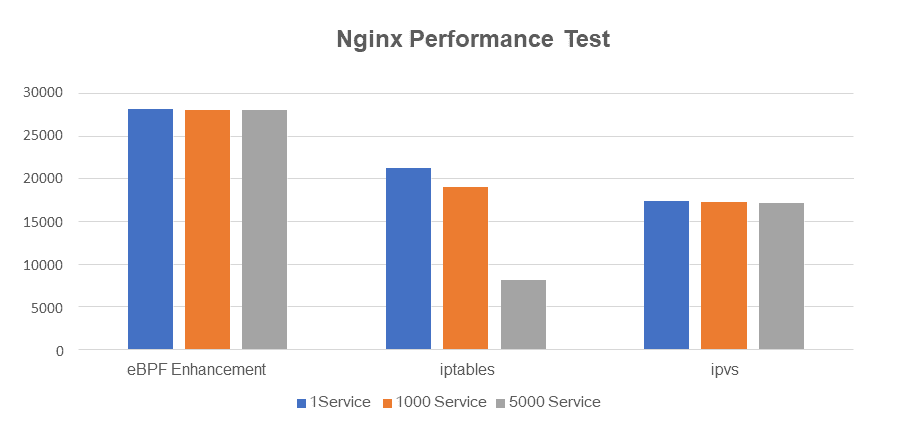
2.1、iptables 与 IPVS 的实现
iptables的实现
iptables 的 Serivce 实现诞生于 kubernetes 1.2 版本,iptables 和 -j DNAT 为 Service 提供负载均衡的规则。
iptables 规则更新的缺点:
- 更新时延:规则更新是全量更新,缺乏增量,增加/删除一条规则,需要整体修改 netfilter 规则表
- 可扩展性:iptables 增加规则的时延,随着规则数的增加呈指数级上升,同时因为全量提交的过程中做了保护会出现 kernel lock 问题
- 可用性不足:服务扩容/缩容时,iptables 规则的刷新会导致连接中断,服务不可用。
iptables 的更新时延统计:
- 5k service (40k 规则),每增加一条 iptables 规则需要 11min
- 20k service (160k 规则),每增加一条 iptables 规则需要 5h
IPVS 的 Service 实现
显然由于 iptabes 的缺点只能运行在小规模集群下,2018 年华为容器团队使用 IPVS 取代 iptables 实现大规模 Service 负载均衡,社区 GA 于 kubernetes 1.11 版本。IPVS 与 iptables 都是基于 netfilter 框架实现,规则存储于 hash 表中,规则更新的时延不会随着基数上升而不可用。
iptabes VS IPVS 规则增加时延(数据来源于华为容器团队)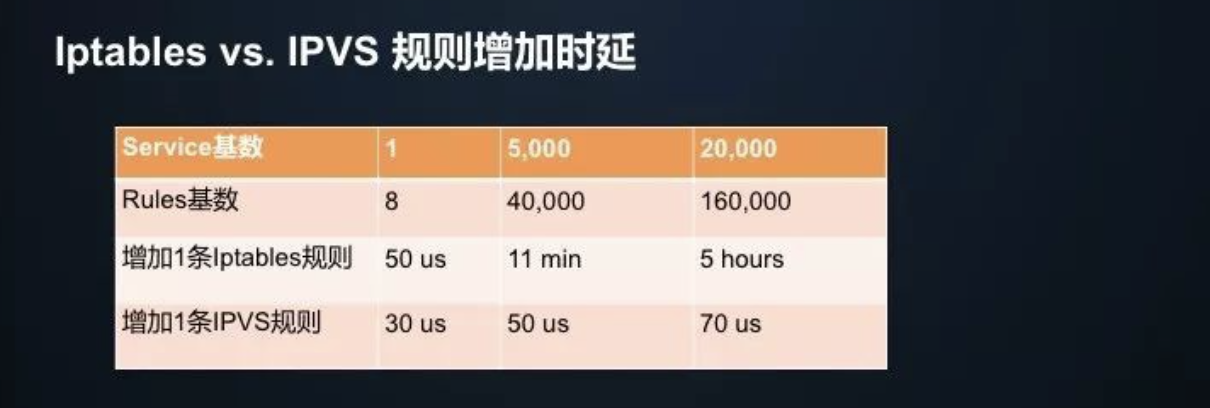
内核 conntrack 竞态问题
kubeproxy 的 IPVS 模式,由于 IPVS 缺乏 SNAT 模块,利用 nf_conntrack/iptables 实现 SNAT,IPVS 使用 ipset 来存储需要 DROP 或 masquared 的流量的源或目标地址。
iptables 依赖 netfilter 和 kernel conntrack 连接跟踪模块,Linux 低版本内核在进行源网络地址转换 (SNAT) 时存在已知的竞态问题,这可能导致 SYN 数据包被丢弃。
规避建议
- iptables 需要开启 random-fully 选项端口随机,缓解 SNAT 端口竞争情况
- Pod 容器环境开启 DNS single-request-open 选项禁用并行查找
- 由于常用容器镜像 alpine 系统的 musl libc 限制,导致无法生效 single-request-open 禁用并行查找,故不建议使用 alpine 系统
2.2、eBPF 的实现
近年来 BPF 以疯狂的速度发展,应用范围从内核性能分析扩展到了网络领域。 这是由于 BPF 提供了强大、高效的可编程性。
Linux 内核社区在 2018 年宣布了 bpfilter ,它将取代 iptables 的长期内核实现,由 Linux BPF 提供支持的网络过滤,同时保证无中断。
BPF 主要推动者:
- Facebook 率先使用 BPF/XDP 代替 IPVS 实现负载均衡,Facebook 从 IPVS 迁移到 BPF 后性能提高了几倍
- 大名鼎鼎的 Brendan Gregg(《性能之鼎》作者),一直在利用 BPF 用于性能分析和跟踪的能力
- kubernetes 网络组件 Cilium 使用 BPF 实现容器网络与 Serivce 负载均衡,项目发起者为十年以上 Linux 网络模块维护者
早期的 bpfilter 与 iptables 的比较 (数据来源于 cilium 团队)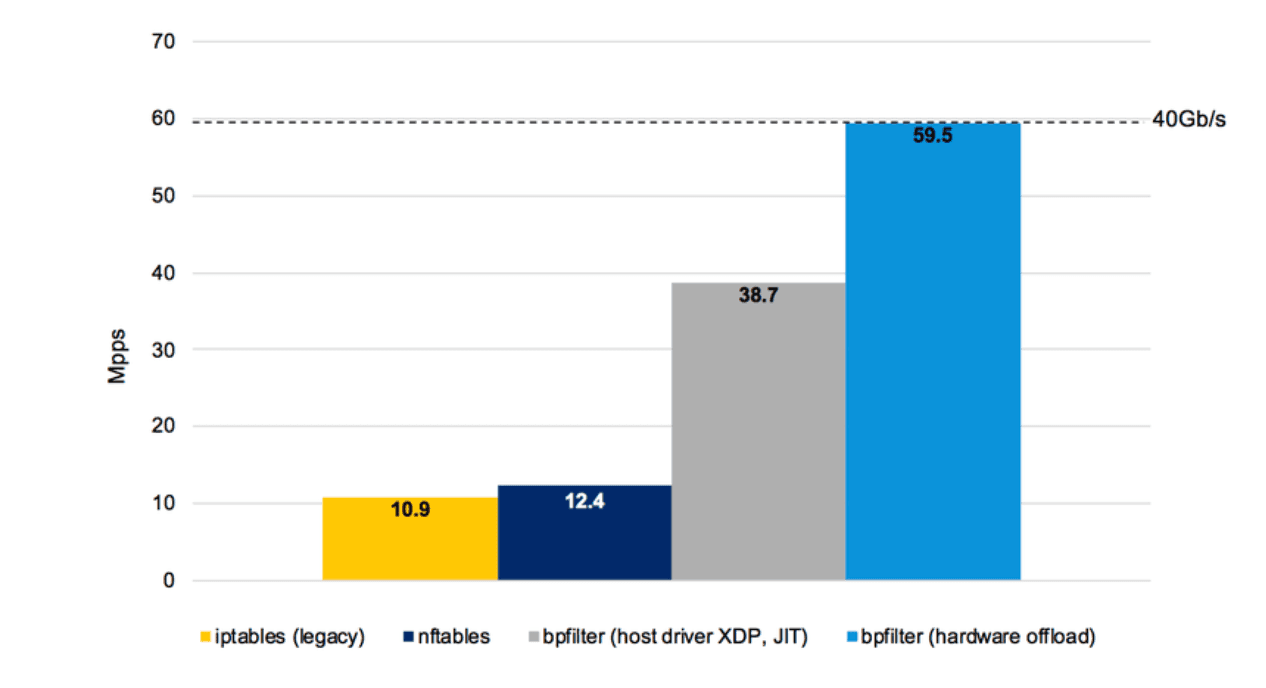
用 Cilium/BPF 替换 kube-proxy
Cilium 里基于 BPF 实现了一个连接跟踪器,完全替换了 nf_conntrack。基于 BPF 的 SNAT 实现中,用一个 LRU BPF map 存放 Service 和 backend pods 的映射信息。SNAT 会替换 src_ip和src_port,由于不同客户端的 src_port 可能是相同的,如果只替换 src_ip,不同客户端的应答包在反向转换时就会失败。因此这种情况下需要做 src_port 转换。目前做法是先进行 hash,如果 hash 失败则调用 prandom() 随机选择一个端口。
重复利用
通过过期 NAT entry 的快速重复利用(fast recycling)技术。如果一个连接断开时,不会直接删除对应的 entry,而是进行标记为过期;如果有新的连接刚好命中了这个 entry,会将其标记为正常,以达到重复利用这个 entry 的目的。
DSR 模式
之前跨宿主机转发是 SNAT 模式,Cilium 1.8+ 开始支持 DSR 模式。DSR 的好处是 backend pods 直接将包回给客户端,回包不再经过当前节点转发。
3、构建大型容器网络
3.1、VxLAN 隧道模式
构建大型容器网络最经典的方式是用 VxLAN 方式构建大型 overlay 网络,从 Google 到阿里云底层皆使用 VxLAN 方式构建数据中心网络,使用MAC in UDP的方法进行封装,对端进行解封。
基于 VxLAN 的高度可扩展性,可以绕过物理网络进行大规模网络扩展,cilium 基于 bpf 实现了多云 VxLAN 网络(clustermesh),简单部署即可实现多云互联互通的容器网络。
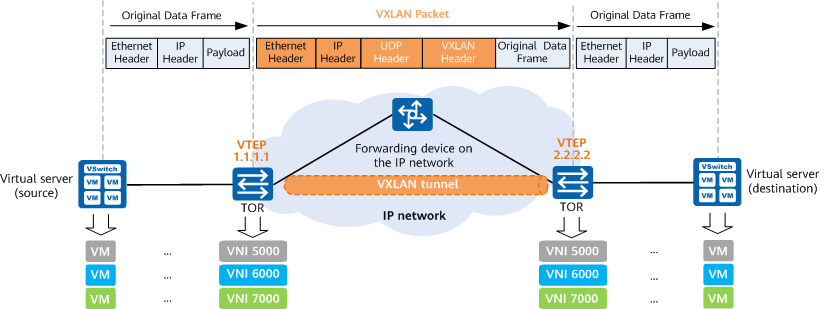
VxLAN 报文: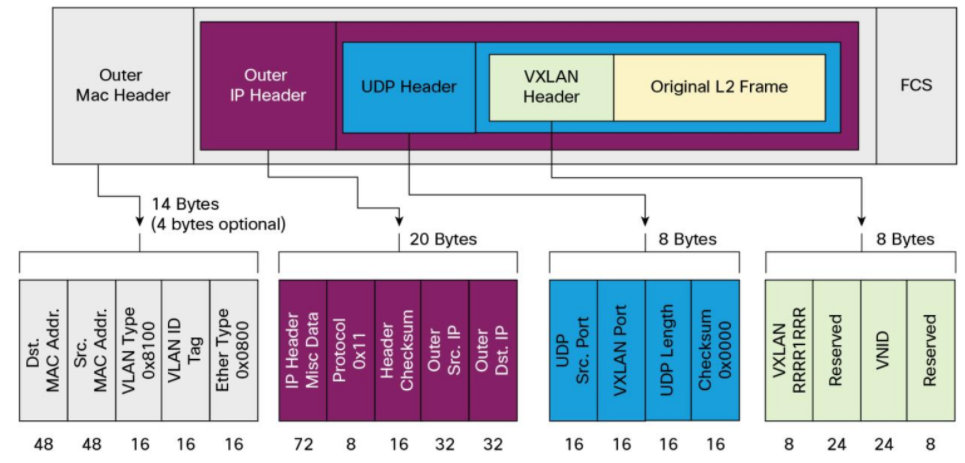
由于 VxLAN 报文包体较大,封解包过程性能折损较大。适合需要突破 vlan 4096 规模限制的超大规模数据中心并且 VxLAN 有一定性能优化能力。显然大部分业务场景并没有这种超大规模的扩展性需求,而性能在大多数场景下显得至关重要,需要寻求其他轻量级方案。
3.2、BGP Router 模式
Facebook 选择了 BGP 用于构建大型数据中心,BGP 是 自治系统 间的路由协议,BGP 分为 eBGP 和 iBGP 自治系统间,边界路由器之间使用 eBGP 广播路由。边界路由器通过 iBGP 将学习到的路由信息导入到内部网络,BGP 协议的其中一个缺点是收敛过程慢。
如果不考虑具体的 BGP 方案,很难讨论容器网络的 bgp 配置。然而 BGP 方案设计超出的本文章的讨论范围。如果您对此主题感兴趣,请参阅 BGP in the Data Center (O’Reilly,2017)。
下面将讨论容器网络实施 bgp 路由模式的几种通用方案,适用于从单集群小规模节点到数个中型集群的网络互联互通再到与物理网络 bgp 融合的逐步演进方案,可根据不同应用规模和场景选择对应方案。
全网格 Full-mesh
Full-mesh (全网格) 对于小于 100 个节点的小型部署非常有效。Full-mesh 模式的代表 kuberouter 和 calico,把每个 node 都当成 router。启用 BGP 时 Calico 的默认行为是创建一个完整的内部 BGP(iBGP)连接网格,其中每个节点彼此对等路由信息,直接路由的方式性能相当不错。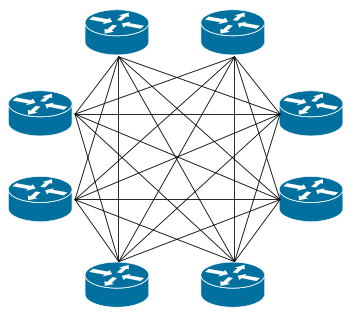
路由反射器 Route reflectors
在更大的规模下,Full-mesh 的效率会降低,所以建议使用 Route reflectors(路由反射器),来减少每个节点上使用的 BGP 对等体的数量。
在这个模型中,一些节点充当 Route reflectors(路由反射器),并被配置为在它们之间建立一个完整的网格。其他节点随后被配置为对应 Route reflectors(路由反射器)的子集进行对等(通常为 2 个用于冗余),与全网相比减少了 BGP 对等连接的总数。该模式适用于多个容器集群的互联互通,利用 bgp 路由协议构建 3 层容器网络。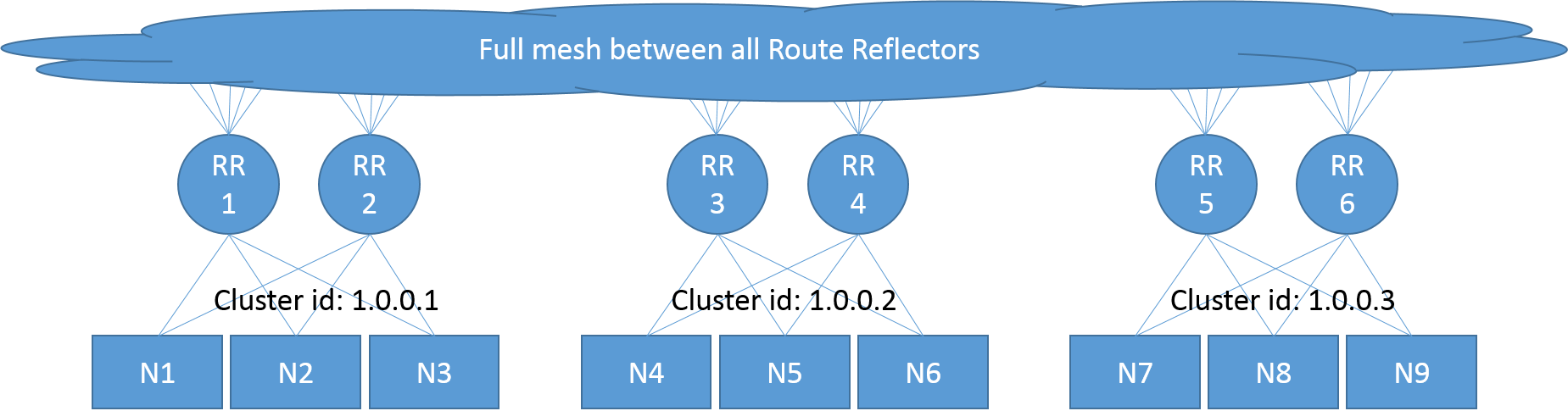
RR 模式的注意事项:
- BGP 只允许在任何 L2 网络上运行,RR 模式不可以与 VxLan 共用
- 跨 VLAN 网络情况则需要配置 IPIP 隧道,有一定性能折损
- 在大规模应用下,RR 所在节点将可能成为性能瓶颈点
顶架式 Top of Rack (ToR)
Cilium 的 BGP 顶架式方案,纯物理网络,适用于约 2k nodes 单集群规模。该模式需要与数据中心网络工程师进行大量测试,我们目前使用该方案推进容器网络升级。
三层分层体系结构
- 节点通过第 2 层交换机连接到物理网络
- 通过 bird 软件向物理网络宣布每个节点的 PodCIDR
- 对于每个 node,不要从物理网络导入路由宣告
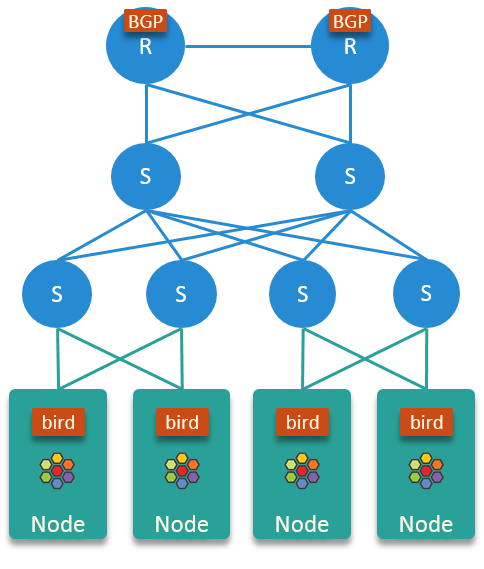
在这个设计里,BGP 连接如下所示: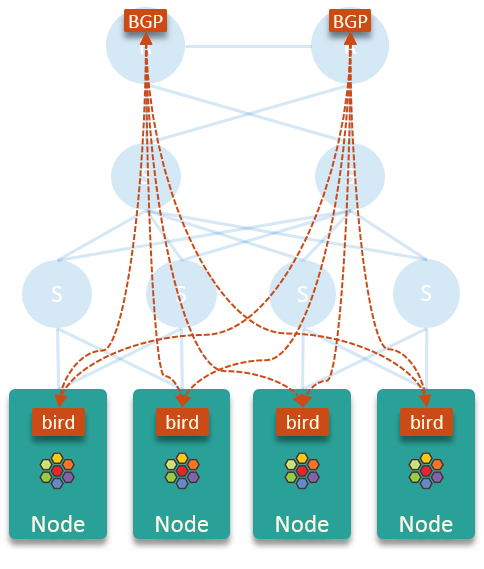
注:这里 node 上使用 host-local 的 IPAM 地址管理方式,每个节点分配个/24 子网的 PodCIDR
核心路由器从 bird 那里学习 PodCIDR 的路由,Pod IP 地址就可以在整个网络中路由。bird 不向核心路由器学习路由信息,这让每个节点上路由表非常干净简洁。每个节点只需向节点的默认网关(核心路由器)发送 pod 出口流量,并让核心路由器进行路由。
BGP 邻居规模上限问题
- 通过 bird 上报路由的方式,规模受限于物理网络设备的 bgp 邻居数量上限和 IP 地址分配策略
- 也可通过 gobgp 开源库, 开发 ibgp 路由上报程序,由上报程序向核心路由器统一上报所有的 PodCIDR,从而减少 ibgp 邻居数量
3.3、IPVlan L2 直通模式
IPVlan L2 模式 和 macvlan 类似,都是从一个主机接口虚拟出多个虚拟网络接口。一个重要的区别就是所有的虚拟接口都有相同的 mac 地址和不同的 IP 地址,而macvlan则是不同的 IP 同时不同的 mac 地址。需要注意的是地方是IPVlan L2同网络子接口的生成的IP, mac 地址是一样的。
Linux kernel 3.19 首次支持 IPVlan,各大厂商推荐使用的版本是 >= 4.19 内核代码目录:/drivers/net/ipvlan/
IPVlan 网络的应用
阿里云基于 cilium cni channing 的扩展能力(aws 也是使用该方式),使得阿里云的容器网络插件 terway 能和 cilium 集成从而支持 bpf。因为 IPVlan L2 模式具备独立的网络 namespace,并不共享 host 的网络 namespace,利用 tc 将 Service 流量劫持重定向到 host 网络 namespace 下达到兼容节点侧的 Service 负载均衡的目的,有兴趣的可以阅读阿里云的( Kubernetes网络的IPVlan方案 )。
IPVlan L2 模式数据路径非常简洁,Pod 网络通信不从 host 网络 namespace 下通过,直通物理子网卡。由于网络堆栈不从节点的 iptables 或路由表通过,因此可以绕过 kubernets conntrack竞争 问题,令人头疼的 DNS 超时问题大部分是由 conntrack 引起的。
(来源于阿里云容器团队)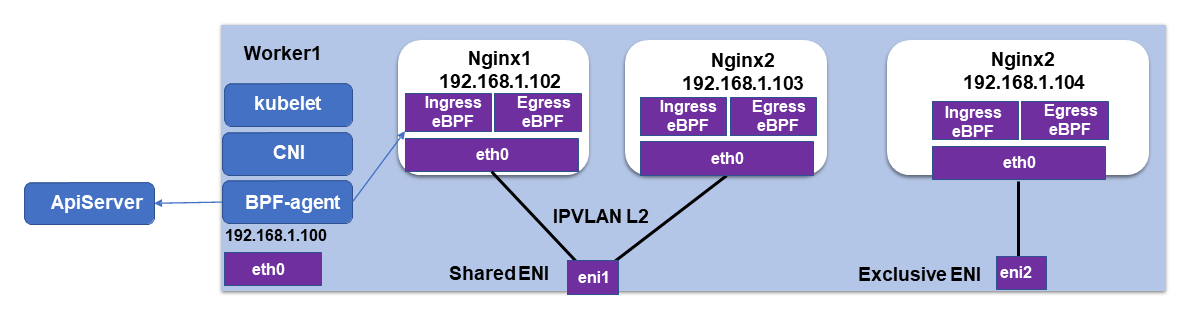
TC 劫持重定向 Service 流量的命令
tc filter add dev $ENIA egress proto ip u32
match ip dst $SERVICE_CIDR
action tunnel_key unset pipe
action tc_mirred ingress redirect dev ipvl_a0
由于阿里云 terway 的方案使用的是 Cilium1.8 系列版本,未持续跟进升级 Cilium 版本,实现方式绑定阿里云配套的网络产品,故目前只适合在阿里云上时候。但该方案数据路径简洁,与 Cilium 兼容的方式打通数据路径,有较大的架构优势,未来将向该方案靠拢。
3.4、NodeLocal DNS
NodeLocal DNSCache 通过在集群节点上作为 DaemonSet 运行 dns 缓存代理来提高集群 DNS 性能。 集群优先 DNS 模式的 Pod 可以连接到 CoreDNS 的 ClusterIP 进行 DNS 查询。
通过 kube-proxy 添加的 iptables 规则将其转换为 CoreDNS 端点。 借助这种新架构,Pods 将可以访问在同一节点上运行的 dns 缓存代理,从而避免了 iptables DNAT 规则和连接跟踪。
主要动机
- 拥有本地缓存将有助于改善延迟,降低 CoreDNS 服务的查询数量
- 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争 并避免 UDP DNS 条目填满 conntrack 表
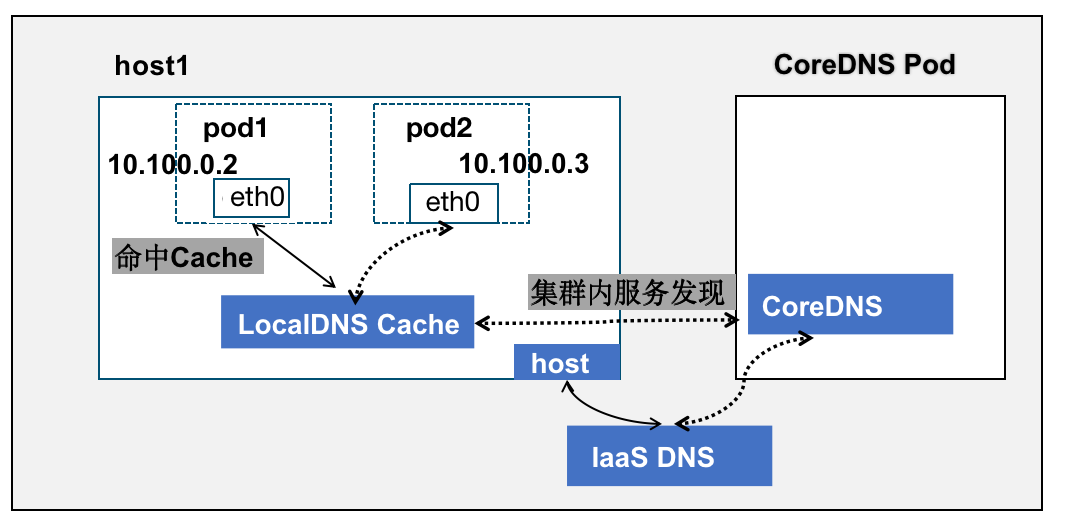
值得注意的是 NodeLocal DNS 与 MacVlan、IPVlan L2 等独立的网络 namespace 并不兼容,上文有提到阿里云使用 TC 劫持重定向 Service 流量达到兼容目的。
参考附录
- (2017) BGP in the Data Center https://www.oreilly.com/library/view/bgp-in-the/9781491983416/
- (2018) 华为云在 K8S 大规模场景下的 Service 性能优化实践 https://zhuanlan.zhihu.com/p/37230013
- (2018) 为什么内核使用 BPF 替换 iptables https://cilium.io/blog/2018/04/17/why-is-the-kernel-community-replacing-iptables
- (2019) 利用 eBPF 支撑大规模 Kubernetes Service https://arthurchiao.art/blog/cilium-scale-k8s-service-with-bpf-zh
- (2019) Kubernetes 网络的 IPVlan 方案 https://kernel.taobao.org/2019/11/ipvlan-for-kubernete-net/
- (2020) 阿里云如何在生产环境中构建高性能云原生 Pod 网络 https://www.alibabacloud.com/blog/how-does-alibaba-cloud-build-high-performance-cloud-native-pod-networks-in-production-environments_596590
- (2020) 腾讯云绕过 conntrack,使用 eBPF 增强 IPVS 优化 K8s 网络性能 https://cloud.tencent.com/developer/article/1687922