一个类的生命周期

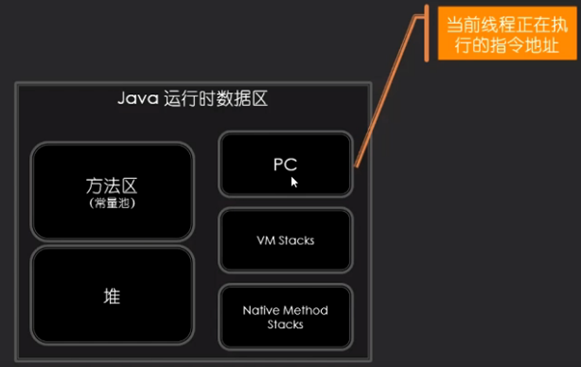
运行时数据区

ProgramCounter(程序计数器)
程序计数器:用于记录当前运行到哪一个指令
每个Java虚拟机线程都有自己的pc(程序计数器)寄存器(线程独享的)
在任何时刻,每个Java虚拟机线程都在执行单个方法的代码,即该线程的当前方法
如果该方法不是本机的,则pc寄存器包含当前正在执行的Java虚拟机指令的地址
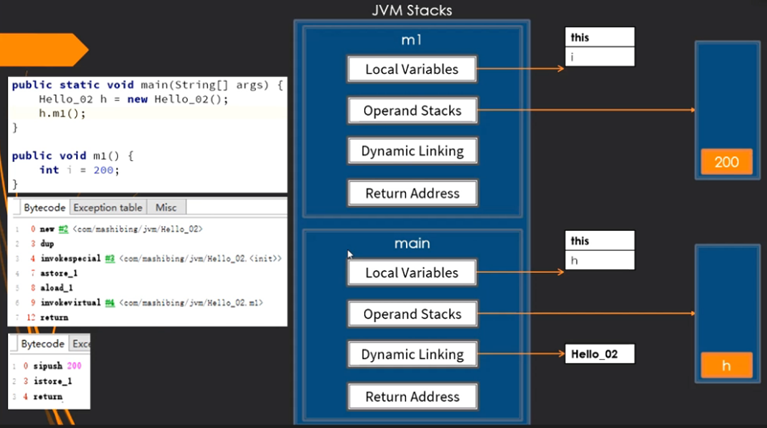
JVM Stacks(虚拟机栈)
每个Java虚拟机线程都有一个与线程同时创建的私有Java虚拟机堆栈(线程独享的)
Java虚拟机堆栈存储栈帧
Nativr Method Stacks(本地方法栈)
Java虚拟机的实现可以使用称为本机方法堆栈的传统堆栈(线程独享的)
只有访问本地方法(调用C C++实现的代码时)的时候才会被使用
Heap(堆)
每个Java虚拟机线程都有一个与线程同时创建的私有Java虚拟机堆栈(线程共享的)
Java虚拟Maoninelstack存储帧
用来存储创建的对象的
Method Area(方法区/永久区/元数据区)
Java虚拟机有一个在所有Java虚拟机线程之间共享的方法区域(线程共享的)
它存储每个类的结构
用来存储Class文件(Class模板)
Run-Time Constant Pool(运行时常量池)
运行时常量池是类文件中onstant池表的每个类或每个接口的运行时表示
JVM内存模型
堆从G1开始不再是连续的,是被分成一块一块的块内存
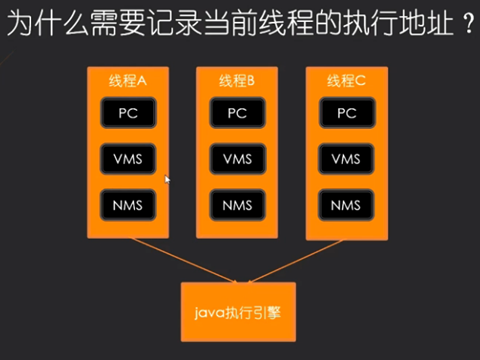
因为每个线程都是互相独立的,当运行其他线程是必须记录当前不被执行线程的执行位置
VMS(虚拟机栈),主要存储的是栈帧

Frame(栈帧)
框架用于存储数据和部分结果,以及执行动态链接、方法的返回值和分派异常
程序执行过程中使用的数据
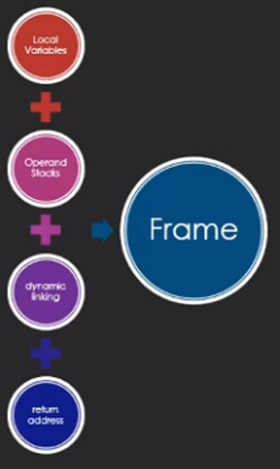
Local Variables Table(局部变量表)
存储局部变量
方法的参数等同于局部变量
静态方法中没有this
存储编译后的指令集
Operand Stack(操作数栈)
运行时的栈
Dynamic Linking(动态链接)
多态使用的
Return Address(方法返回地址)
一个方法对应一个栈帧
最简单的也会有一个main方法
方法结束时数据会从栈帧中弹出

IDEA安装插件

使用方法
光标要在Class文件的内部
点击按钮

展示的视图

方法对应的指令集


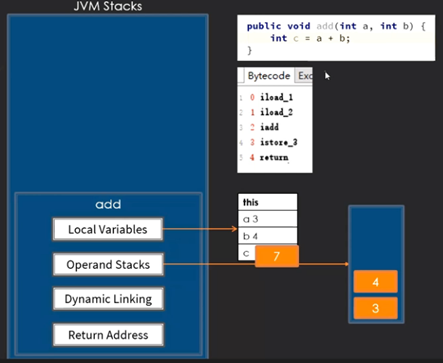
new对象时,会先从堆中分配一块内存,然后初始化该内存(int初始值为0)
然后使用对象的构造方法区设置该内存的值
所以当多个线程同时访问内存时,无法保证new的操作是线程安全的,(可能读到半初始化状态)
单例模式最好使用饿汉式,从虚拟机上保证是线程安全的

中间的
man方法调用m1方法,m1的返回值会被保存在main方法的操作数栈的头部
返回地址
位于EBP寄存器指向的内存地址中
堆
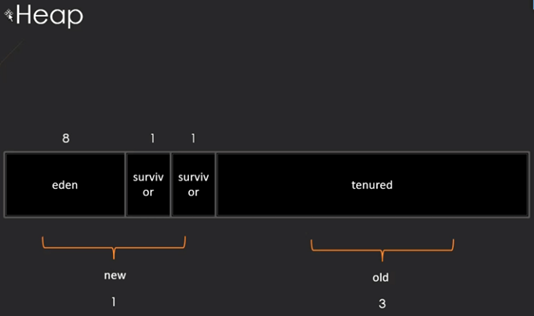
堆分为
new(新生代)
eden(伊甸) 8
surviv or 1
surviv or 1
old(老年代)
tenured(终身)
如果一个对象,诞生时占的空间就非常大,直接进入老年代(空间比较大)
如果一个对象,诞生时占的空间不是很大,会放到eden
在eden用完后,会经过一次GC的回收,如果还有被使用会被复制到
surviv区的一个中,如果第二次GC还存在,会复制到另一个sueviv区中
如果第三次GC还存在会再复制到第一次的surviv区中,
复制过程:一次GC后把eden区和surviv区有用的部分复制到另一个surviv区中,该
GC过的区域直接擦除掉,surviv区永远有一个空的
循环的复制,当GC过多次后(15次),会被复制到tenured中去
垃圾收集器(怎么计算什么是垃圾)
引用计数
根搜索,正向表达(根可达算法)
能找到的都是垃圾,找不到的都不是垃圾
根对象
JVM栈的对象,本地方法栈的对象,运行时常量池的对象,
方法区域的静态引用的对象,被引用的类的对象
垃圾收集器算法(如何处理标记的垃圾)
Mark-Sweep(标记清除)

三色标记(容易产生碎片化)
Copying(拷贝)
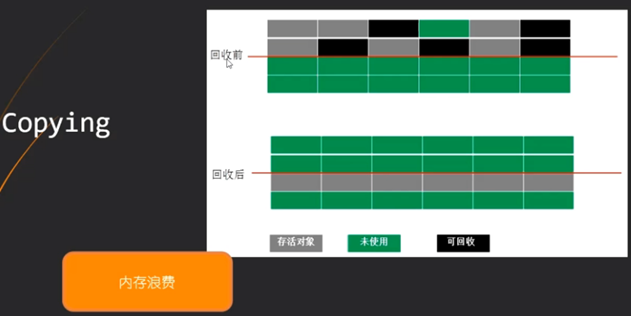
将内存一份为二,垃圾回收后将有用的直接拷贝(复制时压缩)到
另一半空的内存中,之后擦除原内存(容易内存浪费)
Mark-Compact(标记压缩)
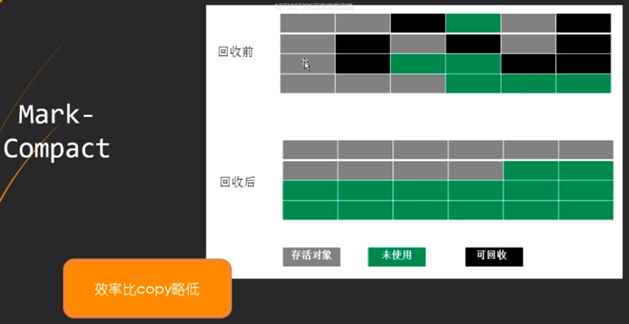
回收之前将垃圾标记出来,回收后将有用的数据复制到新内存并压缩
(效率比copy略低,避免碎片化)
分代使用不同的垃圾回收算法
fuGC应该尽量避免的
Hotspot中的垃圾收集器(一般使用G1,根据具体的需求选择使用不同的垃圾收集器)
Serial(串行的)
Parallel(并行的)
Concurrent Mark Sweep(并发的标记清除)(jdk1.8使用的,将内存分为块内存)
G1(jdk1.8使用的,推荐的)
ZGC(未来的)
Java对象分配(用来调优的)

对象不一定分配到堆中
栈(无需GC)
无逃逸(只有这个方法用到,其他方法没有用到,用完直接弹出)
无逃逸一定在栈上
小对象先栈上分配
堆(都需要GC)
不行分配到线程本地(eden中每个线程分配一小块内存)
看看是不是大对象,大对象直接老年代
不是大对象去eden