2.0 序
在所有的python内建对象中,整数对象是最简单的对象。从对python对象机制的剖析来看,整数对象是一个非常好的切入点。那么下面就开始剖析整数对象的实现机制
2.1 初识PyLongObject
python中整数这个概念的实现是通过PyLongObject结构体来完成的,之前说过python中的对象本质上就是c语言中的malloc为结构体在堆上申请的一块内存,那么python中整数对象就是一个PyLongObject结构体实例。在上一章初探python对象体系的时候,我们看到了定长对象和变长对象,这是一种对象的二分法。然鹅实际上,还存在着另一种对象的二分法,这种分类法是根据对象维护的数据的可变性将数据分为可变对象(mutable)和不可变对象(immutable)。这章将要剖析的PyLongObject就属于不可变对象,我们先来看看什么是可变对象,什么是不可变对象吧。
不可变对象:python中的不可变对象,一旦被创建就不可以再改变了,换句话说就是PyLongObject对象所维护的值不能变了。比如int实例对象,a=123,一旦创建不能更改。想更改的话,只能创建一个新的对象,然后让变量重新指向它,这样的话变量的id会发生变化。可变对象:创建之后,是可以动态改变的,前后id不会改变
integer = 123
print(id(integer)) # 140703693373520
integer += 1
print(id(integer)) # 140703693373552
"""
integer += 1
表示将integer的值和1的值进行相加,然后根据这个新的值创建一个PyLongObject对象
然后让integer这个变量重新指向新的PyLongObject对象
因此对于python中的int实例来说,不可变性,指的就是PyLongObject对象中所维护的值是不可以改变的。
"""
l = [1, 2, 3]
print(id(l)) # 2167904358984
l.append(4)
print(id(l)) # 2167904358984
"""
list是可变对象,可以动态添加、删除、修改元素
因此操作前后的地址是不变的
因此对于list实例来说,可变性,指的就是PyListObject对象中维护的值是可变的
"""
string = "喜欢本大爷的居然只有你一个"
"""
str是一个变长对象,但是它不可变对象
里面的值一旦创建,实际不允许修改的。
"""
try:
string[0] = "xxx"
except TypeError as e:
print(e) # 'str' object does not support item assignment
python有很多的可变对象和不可变对象
在python的应用程序中,整数的访问可以说是非常广泛了,因此会不停地被创建和销毁,考虑python的引用计数机制,这是否意味着要不断地向系统堆申请内存?如果真是这样,那么效率必然会大打折扣。因此必须要设计一个高效的机制,使得整数对象的使用不会成为python的瓶颈,于是就有了整数对象池。
整数对象池,是一个优雅而又巧妙的整数对象的缓冲池机制。在此基础上,运行时的整数对象并非一个个独立的对象,而是如同自然界的蚂蚁一般,已经通过一定的结构联结在一起构成了庞大的整数对象系统了。而这种面向特定对象的缓冲池机制也是python语言实现时的核心设计策略之一,在后续的剖析中,我们会看到几乎所有的内建对象都有自己所特有的对象池机制。
言归正传,在深入整数对象的运行时行为之前,我们再来看看整数对象在C语言中的实现--PyLongObject,整数对象就是一个PyLongObject实例。首先在python3中,数值型只有两种,一种是int存储整型、另一种是float存储浮点型
//longintrepr.h
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
//longobject.h
typedef struct _longobject PyLongObject; /* Revealed in longintrepr.h */
//合起来可以看成
typedef struct {
PyObject_VAR_HEAD
digit ob_digit[1];
} PyLongObject;
/*
还记得这个PyObject_VAR_HEAD吗?
是一个宏,相当于PyVarObject ob_base
这个PyVarObject则是在PyObject的基础上添加了一个ob_size
*/
//因此如果把这个PyLongObject更细致的展开一下就是
typedef struct {
Py_ssize_t ob_refcnt; //引用计数
struct _typeobject *ob_type; //类型
Py_ssize_t ob_size; //维护的元素个数
digit ob_digit[1];
} PyLongObject;
首先Py_ssize_t ob_refcnt;、struct _typeobject *ob_type;、Py_ssize_t ob_size;无需解释,至于最后一个digit ob_digit[1];显然是真正用来存储整数对象的值的,只是这个digit是什么类型,我们还不知道。
#if PYLONG_BITS_IN_DIGIT == 30 //只使用30位
typedef uint32_t digit; //unsigned int
typedef int32_t sdigit;
typedef uint64_t twodigits;
typedef int64_t stwodigits;
#define PyLong_SHIFT 30
#define _PyLong_DECIMAL_SHIFT 9
#define _PyLong_DECIMAL_BASE ((digit)1000000000)
#elif PYLONG_BITS_IN_DIGIT == 15 //只使用15位
typedef unsigned short digit; //unsigned short
typedef short sdigit;
typedef unsigned long twodigits;
typedef long stwodigits;
#define PyLong_SHIFT 15
#define _PyLong_DECIMAL_SHIFT 4
#define _PyLong_DECIMAL_BASE ((digit)10000)
#else
#error "PYLONG_BITS_IN_DIGIT should be 15 or 30"
#endif
#define PyLong_BASE ((digit)1 << PyLong_SHIFT)
#define PyLong_MASK ((digit)(PyLong_BASE - 1))
#if PyLong_SHIFT % 5 != 0
#error "longobject.c requires that PyLong_SHIFT be divisible by 5"
#endif
//所以digit要么是uint32_t(unsigned int),要么是unsigned short。具体取决于操作系统是多少位的
//但是以现在的机器,基本上都是64位的,所以digit基本上都是uint32_t
//但是这个PYLONG_BITS_IN_DIGIT是啥?显然是一个宏,要么是30要么是15
//这个表示的意思是在64位的机器上,digit是4字节、32位,但是存储只用30位。
//如果在32为机器上,digit是2字节、16位,但是存储只用15位
搞清楚了digit,那么这个ob_digit[1]又是啥?看样子好像是一个数组ε=(´ο`*)))唉,但是为啥用一个数组表示呢?另外,我们知道python中可以存储任意长度的整型,可是底层确是一个unsigned int,那么python是如何做到存储任意长度的整型的呢?带着这个疑问,我们来看一看PyLongObject内部元素是如何存储的。
整数0
注意,当要表示的整数为0时,ob_digit这个数组为空,不存储任何值,ob_size为0,表示这个整数的值为0,这是一种特殊情况。

整数1

当存储的值为1的时候,可以看到ob_size变成了1,表示ob_digit这个数组里面只有一个元素。
整数-1
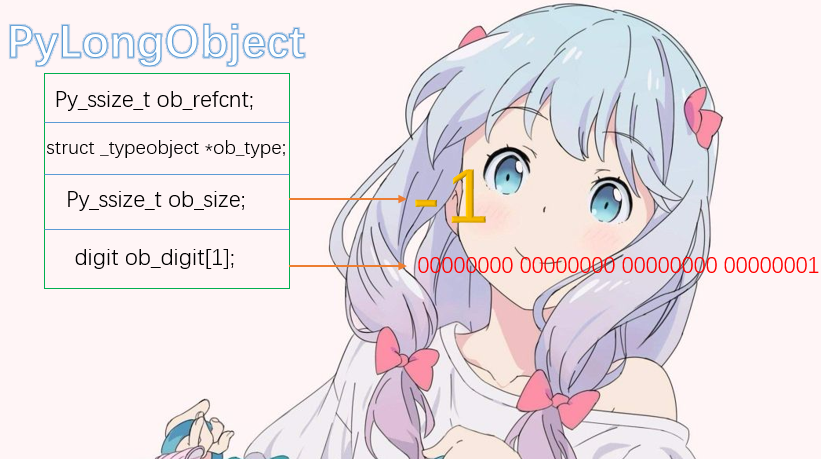
当存储的值为负数的时候,ob_size为-1,说明ob_size除了能表示对象的个数,对于PyLongObject来说,还可以表示值的正负。
整数(1<<30) - 1

30位,表示可以存储的最大数字是(1<<30)-1
整数(1<<30)
这时候问题来了,我们之前说了。对于64位的机器,digit是32位,但是存储只用30位(至于为什么这么设计,我们之后再谈),说明能够存储的最大值的上限是(1<<30)-1,但是现在要存储的是1<<30,怎么办呢?还记得,ob_digit吗?这是一个数组,对,你没有猜错,再往数组里面放一个元素不就可以了。
再继续往下剖析源码之前,我们先来做个测试,看看一个整数在python中占了多少内存。对于python中的整数占了多少内存,显然就是PyLongObject实例化之后占了多少内存。
typedef struct {
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
Py_ssize_t ob_size;
digit ob_digit[1];
} PyLongObject;
//Py_ssize_t,我们上两章说过了,直接把它当成long来看待即可,8字节
#ifdef HAVE_SSIZE_T
typedef ssize_t Py_ssize_t;
#elif SIZEOF_VOID_P == SIZEOF_LONG
typedef long Py_ssize_t;
#else
typedef int Py_ssize_t;
#endif
//以上在configuration文件中
//至于ob_type显然是一个结构体指针,在64位机器上,存储指针也是8字节
/*
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
Py_ssize_t ob_size;
*/
//由于以上3者,对于任何一个整型变量,都是必须要有的,所以python中任意一个整型大小都会超过24字节
//具体是多少就取决于ob_digit到底有多少个元素了
import sys
a = 1
b = (1 << 30) - 1
print(sys.getsizeof(a)) # 28
print(sys.getsizeof(b)) # 28
"""
相信为什么是28,很好理解,因为ob_digit数组只需要一个元素就能存下,digit是4个字节,24 + 4 = 28
"""
c = 1 << 30
print(sys.getsizeof(c)) # 32
"""
由于一个字节只用30位,现在的值是1 << 30,存不下,因此数组里面还需要第二个元素,所以总共是8字节,加上24=32
"""
"""
相信下面的不需要解释了
"""
print(sys.getsizeof((1 << 60) - 1)) # 32
print(sys.getsizeof(1 << 60)) # 36
print(sys.getsizeof((1 << 90) - 1)) # 36
print(sys.getsizeof(1 << 90)) # 40
那么言归正传,我们看看1 << 30,PyLongObject是如何存储的。首先(1 << 30) - 1转化为二进制应该是00111111 11111111 11111111 11111111,那么(1 << 30)转为二进制显然是01000000 00000000 00000000 00000000,但是这里用了31位,而python里面最多只用30位,所以是这样存储的。

可以看到此时的ob_size是2,因为ob_digit里面有两个元素。所以说整数在python3里面是一个变长对象。现在我们知道python3是使用数组的方式来解决了可以存储任意长度的数(只要你的内存足够大),但是还遗留了一个问题,为什么32位的unsigned int,只用30位,32位全用完它不香么?很多时候,明明可以少用一个字节的。是的,这么做确实可以只用一个字节就存储更多的数,但是计算会很不方便,大位数相乘会出现溢出问题。至于python是如何对数值进行比较和运算的,我们后续会介绍。
目前我们知道了python中的整数,在C语言的层面上是什么了,那么我们再来看看类型。我们知道,与实例对象相关的元信息都是保存在与实例对象相对应的类型对象中的。对于PyLongObject来说,这个类型就是PyLong_Type,介绍一些常用的。
PyTypeObject PyLong_Type = {
PyVarObject_HEAD_INIT(&PyType_Type, 0)
"int", /* tp_name:对象名,就是python里面的int */
offsetof(PyLongObject, ob_digit), /* tp_basicsize:创建该类型对象时分配内存空间大小的信息 */
sizeof(digit), /* tp_itemsize:同上 */
long_dealloc, /* tp_dealloc:PyLongObject对象的析构操作 */
0, /* tp_print:打印PyLongObject对象 */
0, /* tp_getattr:对象的反射之getattr */
0, /* tp_setattr:对象的反射之setattr */
0, /* tp_reserved:对象的翻转 */
long_to_decimal_string, /* tp_repr:转换成PyUnicodeObject,就是__repr__ */
&long_as_number, /* tp_as_number:数值操作集合 */
0, /* tp_as_sequence:序列操作集合,但由于是整型,所以不存在的,因此为0 */
0, /* tp_as_mapping:map,关联对象(映射),同样不存在 */
(hashfunc)long_hash, /* tp_hash:获取hash值 */
0, /* tp_call:__call__方法,这里显然为0不支持。在python中则是a=123,不能a() */
long_to_decimal_string, /* tp_str:转换成PyUnicodeObject,就是__str__ */
PyObject_GenericGetAttr, /* tp_getattro */
0, /* tp_setattro */
0, /* tp_as_buffer */
Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE |
Py_TPFLAGS_LONG_SUBCLASS, /* tp_flags */
long_doc, /* tp_doc:注释 */
0, /* tp_traverse */
0, /* tp_clear */
long_richcompare, /* tp_richcompare:比较操作 */
0, /* tp_weaklistoffset */
0, /* tp_iter */
0, /* tp_iternext */
long_methods, /* tp_methods:成员函数集合 */
0, /* tp_members */
long_getset, /* tp_getset */
0, /* tp_base */
0, /* tp_dict */
0, /* tp_descr_get */
0, /* tp_descr_set */
0, /* tp_dictoffset */
0, /* tp_init:__init__方法 */
0, /* tp_alloc */
long_new, /* tp_new:__new__方法 */
PyObject_Del, /* tp_free:PyLongObject的释放操作 */
};
下面我们来看一下,python底层是如何比较两个数的大小。
static int
long_compare(PyLongObject *a, PyLongObject *b) //接收两个PyLongObject对象的指针
{
Py_ssize_t sign; //8字节的long
//#define Py_SIZE(ob) (((PyVarObject*)(ob))->ob_size)
//Py_SIZE:获取对象的ob_size
if (Py_SIZE(a) != Py_SIZE(b)) {
//比较ob_size的个数,数值越大,ob_digit的元素个数就越多
//多的那一方的数值的绝对值肯定大
//当然由于对于PyLongObject来说,ob_digit数组里面的元素都是大于0的,正负号的问题是由ob_size负责考虑的。
//所以毫无疑问,如果ob_size不相等,是可以直接比较出两者的大小的
sign = Py_SIZE(a) - Py_SIZE(b);
}
else {
//如果相等,说明a和b符号相同,那么不管正负,直接取ob_size的绝对值
//相当于把两者都变成正的。
Py_ssize_t i = Py_ABS(Py_SIZE(a));
//我们之前说了,数组里面一个元素存储不下,就需要第二个元素
//而比较元素显然是从高位开始比,位数越高,对应的元素的索引越大,所以从数组索引大的元素开始比
//而对于c来说,直接比较对应数组元素的大小即可
/*
a = 011111111 00000000 11111111 00000000 00000000 00000000 00000000 00000001
b = 011111111 00000000 11111111 00000000 00000000 00000000 00000000 00000011
比如这里的a和b,直接比较a->ob_digit[1]和b->ob_digit[1]的大小即可。
a->ob_digit[1]是1, b->ob_digit[1]是2,所以很容易判断b > a
如果a->ob_digit[1]和b->ob_digit[1]一样,那么就比较两者的ob_digit[0]
*/
//所以这里循环进行--i(会先将i减1),然后比较对应数组的元素大小
while (--i >= 0 && a->ob_digit[i] == b->ob_digit[i])
;
//如果对应元素都相等,那么最终i=-1
if (i < 0)
sign = 0; //sign等于0,表示两者相等
else {
//否则的话,必然会存在一个index,使得对应的数组的元素不一样
//直接做差,注意此时的差是a和b的绝对值之差
sign = (sdigit)a->ob_digit[i] - (sdigit)b->ob_digit[i];
//继续判断ob_size是否小于0,如果小于0说明a和b都是负数
//负数的绝对值越大, 那么其实对应的值反而越小
if (Py_SIZE(a) < 0)
//所以是负数的话,还要把符号加进去
sign = -sign;
}
}
//最终判断sign小于0就是-1,否则的话,看它是否大于0,是的话就是1,不是就是0
return sign < 0 ? -1 : sign > 0 ? 1 : 0;
}
显然,PyLongObject对象的比较操作,就是将维护ob_digit里面的数组的元素按照索引从大到小的顺序挨个进行比较。但是在PyLong_Type这个元信息的集合中,需要特别的是long_as_numbers这个域
static PyNumberMethods long_as_number = {
(binaryfunc)long_add, /*nb_add*/
(binaryfunc)long_sub, /*nb_subtract*/
(binaryfunc)long_mul, /*nb_multiply*/
long_mod, /*nb_remainder*/
long_divmod, /*nb_divmod*/
long_pow, /*nb_power*/
(unaryfunc)long_neg, /*nb_negative*/
(unaryfunc)long_long, /*tp_positive*/
(unaryfunc)long_abs, /*tp_absolute*/
(inquiry)long_bool, /*tp_bool*/
(unaryfunc)long_invert, /*nb_invert*/
long_lshift, /*nb_lshift*/
(binaryfunc)long_rshift, /*nb_rshift*/
long_and, /*nb_and*/
long_xor, /*nb_xor*/
long_or, /*nb_or*/
long_long, /*nb_int*/
0, /*nb_reserved*/
long_float, /*nb_float*/
0, /* nb_inplace_add */
0, /* nb_inplace_subtract */
0, /* nb_inplace_multiply */
0, /* nb_inplace_remainder */
0, /* nb_inplace_power */
0, /* nb_inplace_lshift */
0, /* nb_inplace_rshift */
0, /* nb_inplace_and */
0, /* nb_inplace_xor */
0, /* nb_inplace_or */
long_div, /* nb_floor_divide */
long_true_divide, /* nb_true_divide */
0, /* nb_inplace_floor_divide */
0, /* nb_inplace_true_divide */
long_long, /* nb_index */
};
之前提到过,这个PyNumberMethods中定义了当一个对象为数值对象时所拥有的可选操作信息,每一个都是一个函数指针,包括乘法的四则运算、取模、左移、右移等操作。
在long_as_number中,确定了一个对象为数值对象,这些操作该如何进行。
我们来看看加法操作是如何实现的。
static PyObject *
long_add(PyLongObject *a, PyLongObject *b)
{
PyLongObject *z;
CHECK_BINOP(a, b);
if (Py_ABS(Py_SIZE(a)) <= 1 && Py_ABS(Py_SIZE(b)) <= 1) {
return PyLong_FromLong(MEDIUM_VALUE(a) + MEDIUM_VALUE(b));
}
if (Py_SIZE(a) < 0) {
if (Py_SIZE(b) < 0) {
z = x_add(a, b);
if (z != NULL) {
/* x_add received at least one multiple-digit int,
and thus z must be a multiple-digit int.
That also means z is not an element of
small_ints, so negating it in-place is safe. */
assert(Py_REFCNT(z) == 1);
Py_SIZE(z) = -(Py_SIZE(z));
}
}
else
z = x_sub(b, a);
}
else {
if (Py_SIZE(b) < 0)
z = x_sub(a, b);
else
z = x_add(a, b);
}
return (PyObject *)z;
}
可以看到,实现的机制不是很简单。在python2中,PyLongObject(PyIntObject)维护的不再是一个数组,而只是一个普通long,所以实现起来比较简单。但是在python3中,由于是数组,并且数组的每一个元素用于表示位数,而且一个元素只用30位,因此这些因素导致了,整数的运算会比较复杂一些。我们通过画图来实现,不过实现之前,我们先来看几个概念。
#define PyLong_SHIFT 30
#define PyLong_BASE ((digit)1 << PyLong_SHIFT)
#define PyLong_MASK ((digit)(PyLong_BASE - 1))
假设我们现在让a和b进行相加,a=1<<30,b=1

因此可以看到,python底层中的整数相加,其实没有那么简单。至少python3,底层并不是简单的两个数相加。实质上python2当中,也考虑了溢出的情况,但是比较的话,底层真的只是两个数直接比较一下。至于减法的话,也是类似的,有兴趣的话可以自己看源码。
乘法操作
乘法操作,会创建一个临时变量保存当前的结果,然后不断累加,具体实现可以看源码。只是要提一点的是,python中的乘法采用了更高效的karatsuba乘法,时间复杂度是O(3n^log3),而普通的竖式乘法时间复杂度是O(n^2)
//longobject.c
/* Karatsuba multiplication. Ignores the input signs, and returns the
* absolute value of the product (or NULL if error).
* See Knuth Vol. 2 Chapter 4.3.3 (Pp. 294-295).
*/
static PyLongObject *
k_mul(PyLongObject *a, PyLongObject *b)
{
Py_ssize_t asize = Py_ABS(Py_SIZE(a));
Py_ssize_t bsize = Py_ABS(Py_SIZE(b));
PyLongObject *ah = NULL;
PyLongObject *al = NULL;
PyLongObject *bh = NULL;
PyLongObject *bl = NULL;
PyLongObject *ret = NULL;
PyLongObject *t1, *t2, *t3;
Py_ssize_t shift; /* the number of digits we split off */
Py_ssize_t i;
/* (ah*X+al)(bh*X+bl) = ah*bh*X*X + (ah*bl + al*bh)*X + al*bl
* Let k = (ah+al)*(bh+bl) = ah*bl + al*bh + ah*bh + al*bl
* Then the original product is
* ah*bh*X*X + (k - ah*bh - al*bl)*X + al*bl
* By picking X to be a power of 2, "*X" is just shifting, and it's
* been reduced to 3 multiplies on numbers half the size.
*/
/* We want to split based on the larger number; fiddle so that b
* is largest.
*/
...
...
...
...
}
2.2 PyLongObject的创建与维护
2.2.1 对象创建的途径
在上一章我们已经提到,python中创建一个实例对象是可以通过python暴露的c api,也可以通过类型对象完成创建动作。但无论使用哪种方式创建内建对象的实例对象,我们得出的结论都是正确的。
PyAPI_FUNC(PyObject *) PyLong_FromLong(long);
PyAPI_FUNC(PyObject *) PyLong_FromUnsignedLong(unsigned long);
PyAPI_FUNC(PyObject *) PyLong_FromSize_t(size_t);
PyAPI_FUNC(PyObject *) PyLong_FromSsize_t(Py_ssize_t);
PyAPI_FUNC(PyObject *) PyLong_FromDouble(double);
PyAPI_FUNC(PyObject *) PyLong_FromString(const char *, char **, int);
#ifndef Py_LIMITED_API
PyAPI_FUNC(PyObject *) PyLong_FromUnicode(Py_UNICODE*, Py_ssize_t, int) Py_DEPRECATED(3.3);
PyAPI_FUNC(PyObject *) PyLong_FromUnicodeObject(PyObject *u, int base);
PyAPI_FUNC(PyObject *) _PyLong_FromBytes(const char *, Py_ssize_t, int);
#endif
可以看到python提供了以上途径来创建PyLongObject对象,比如long、Unicode。对于Unicode,是不能直接转的,而是先转化成浮点,然后调用PyLong_FromFloat转换。所以类似于Unicode、String,相当于是利用了设计模式中的Adaptor Pattern的思想对整数创建的函数PyLong_FromFloat进行了接口转换罢了。
//longobject.c
PyObject *
PyLong_FromString(const char *str, char **pend, int base)
{
int sign = 1, error_if_nonzero = 0;
const char *start, *orig_str = str;
PyLongObject *z = NULL;
PyObject *strobj;
Py_ssize_t slen;
...
...
//将字符串转为long
if (str[0] == '0' &&
((base == 16 && (str[1] == 'x' || str[1] == 'X')) ||
(base == 8 && (str[1] == 'o' || str[1] == 'O')) ||
(base == 2 && (str[1] == 'b' || str[1] == 'B')))) {
str += 2;
/* One underscore allowed here. */
if (*str == '_') {
++str;
}
}
if (str[0] == '_') {
/* May not start with underscores. */
goto onError;
}
start = str;
if ((base & (base - 1)) == 0) {
int res = long_from_binary_base(&str, base, &z);
if (res < 0) {
/* Syntax error. */
goto onError;
}
}
else {
...
...
PyErr_Format(PyExc_ValueError,
"invalid literal for int() with base %d: %.200R",
base, strobj);
Py_DECREF(strobj);
return NULL;
}
2.2.2 小整数对象
在实际的编程中,数值比较小的数,比如,1、2、29等,可能会在程序中使用的非常频繁。在python中,所有的对象都存活在堆上(想想python中对象的本质)。也就是说,如果没有特殊的机制,对于这些频繁使用的小整数对象,python将一次又一次的使用malloc在堆上申请空间,并且不厌烦的一次次的free。这样的操作不仅大大的降低了整体效率,还会在系统堆产生大量的内存碎片,严重影响python的整体性能。因此在python中使用了小整数对象池的机制。并且由于PyLongObject维护的值是不可变的,这意味着小整数对象池里面任何一个PyLongObject对象都是可以共享的。
//longobject.c
#ifndef NSMALLPOSINTS
#define NSMALLPOSINTS 257
#endif
#ifndef NSMALLNEGINTS
#define NSMALLNEGINTS 5
#endif
python定义的小整数对象池的范围是[-5, 257),当然你可以动态修改,重新编译。对于这些小整数对象,python一开始就已经创建好了,并缓存在内存中,将其指针存放在small_ints里面,使用的时候直接拿来用即可。
def foo():
a = 1
b = 1 << 20
return id(a), id(b)
def bar():
a = 1
b = 1 << 20
return id(a), id(b)
print(foo()) # (140711479960208, 1990044806128)
print(bar()) # (140711479960208, 1989631792592)
"""
由于1是小整数对象池里面的对象,只有一份,是共享的
而1 << 20显然是大整数,一开始并没有初始化在内存里面,而是临时创建的,所以id是不一样的
"""
不过这里还有一个问题,就是不一定只有小整数被频繁使用啊,[-5, 257)之外的数也可能是经常被使用的。但是如果提前把很多很多的整数对应的PyLongObject对象都缓存在内存中,不就好了吗?这么做显然只是理想的,因为这种方法无疑是对内存的巨大浪费,那么python是怎么做的呢?
2.2.3 大整数对象
首先对于小整数,完全在执行程序之前就已经被缓存到内存中了,并且只有一份。而对其他整数,python运行环境将提供一块内存空间,这些内存空间有这些大整数轮流使用,也就是说,谁需要就谁就使用。这样就免去了不断地malloc之苦,又在一定程度上考虑了效率问题。就像我们之前说的,python会申请一大片内存,用于变量的创建和销毁,这样就避免了频繁地向操作系统申请空间。