hadoop是什么?
hadoop是一个由Apache基金会所开发的分布式系统基础架构,hdfs分布式文件存储、MapReduce并行计算。主要是用来解决海量数据的存储和海量数据的分析计算问题,这是狭义上的hadoop。广义上来讲,hadoop通常指的是一个更广泛的概念--hadoop生态圈
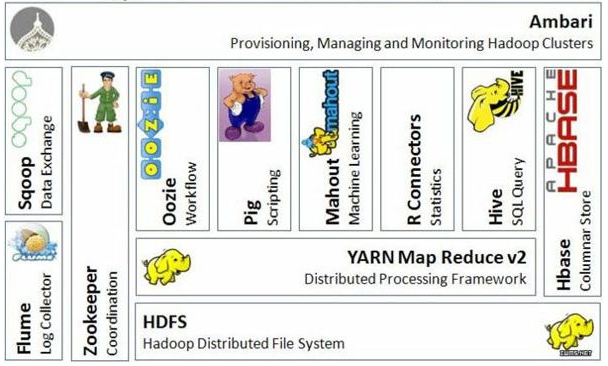
hadoop三大发行版本
hadoop三大发型版本:Apache、Cloudera、Hortonworks
Apache版本,也成为社区版,是最原始的版本,对入门学习较好Cloudera版本在大型互联网企业中用的较多,是对社区版进行了封装,主要是解决了和其它大数据组件(比如:hive)的兼容性问题。但是出了问题帮你解决要收费Hortonworks版本文档较好
公司一般更常用的是Cloudera版本的hadoop,另外Cloudera版本的hadoop也简称为CDH。
hadoop优势
1)高可靠性:hadoop底层维护多个数据副本,所以即使某个机器出现故障,也不会导致数据的丢失。
比如我现在有1G的数据,要存在5台机器上,hadoop默认会先将整个数据进行切割,默认是128M/块,当然这个数值也可以自己改。然后是以三副本进行存储,也就是说每个128M的块,都会被存储三份在不同的机器上。这样即使一台服务器宕机了,数据也不会丢失。

2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。很好理解,如果容量不够了,直接横向扩展,加机器就行。
3)高效性:在MapReduce的思想下,hadoop是并行工作的,以加快任务处理速度。实际上如果学了spark,会发现hadoop自己所描述的易用性、高效性实在是不敢恭维哈。但是hadoop作为大数据生态圈中非常重要的组件,我们是有必要学好的,而且学了hadoop之后,再学spark会轻松很多。而且学习了hadoop,再学spark也会明白为什么spark会比hadoop在效率上高出几十倍、甚至上百倍。
4)高容错性:能够自动将失败的任务重新分配,如果某台机器挂掉了,那么会自动将任务分配到其他的机器上执行
hadoop 1.x和hadoop 2.x的区别

hadoop组成
hadoop的组成上面已经说了,主要由四部分组成,但是哪个common,我们一般不用管。因此从下往上只需要关注,hdfs,yarn,MapReduce即可。
hdfs
hdfs:hadoop distributed file system,hadoop分布式文件系统,它由哪几部分组成呢?
1.NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等等。
2.DataNode(dn):真正用来存储文件块数据以及块数据的校验和,之前说了大文件是要分成多块的,每一块存在不同的DataNode节点(说白了就是服务器、或者电脑)上,每一个节点存储了哪些文件、以及文件被切分了几份都存在哪些DataNode上、文件名、属性等等,这些都叫做元数据,统一交给NameNode管理,而DataNode只负责真正的存储数据。
3. Secondary NameNode(2nn):用来监控hdfs状态的后台辅助程序,每个一段时间获取hdfs元数据的快照。
yarn
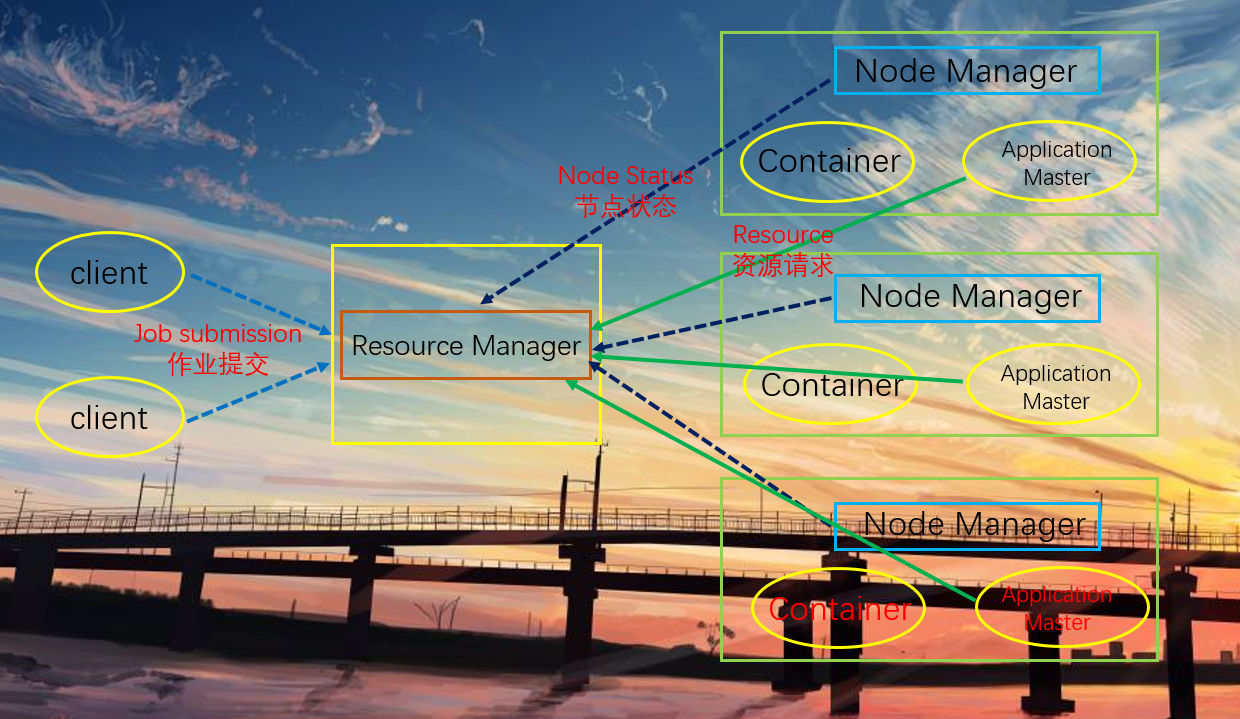
图中有一个Resource Manager和三个Node Manager,相当于有四个节点。
Resource Manager
1.处理客户端请求。客户端想访问集群,比如提交一个作业,要经过Resource Manager,它是整个资源的管理者,管理整个集群的CPU、内存、磁盘
2.监控Node Manager
3.启动或监控Application Master
4.资源的分配和调度
Node Manager
1.管理单个节点上的资源,Node Manager是当前节点资源的管理者,当然需要跟Resource Manager汇报
2.处理来自Resource Manager的命令
3.处理来自Application Master的命令
Application Master
1.某个任务的管理者。当任务在Node Manager上运行的时候,就是由Application Master负责管理
2.负责数据的切分
3.为应用程序申请资源并分配给内部的任务
4.任务的监控与容错
Container
Container是yarn中资源的抽象,它封装了节点上的多维度资源,如内存、CPU、磁盘、网络等等。
其实Container是为Application Master服务的,因为任务在运行的时候,是不是需要内存、cpu,这些资源都被虚拟化到Container里面了。
MapReduce
1. map阶段并行处理输入数据
2. reduce阶段对map结果进行汇总

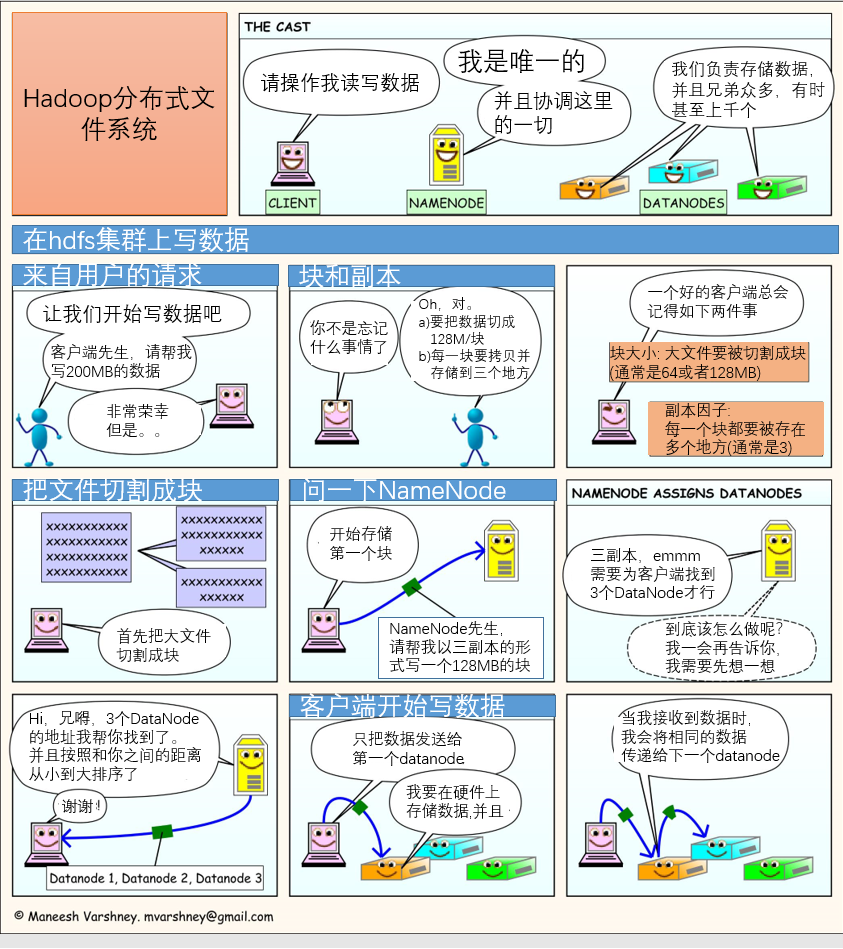
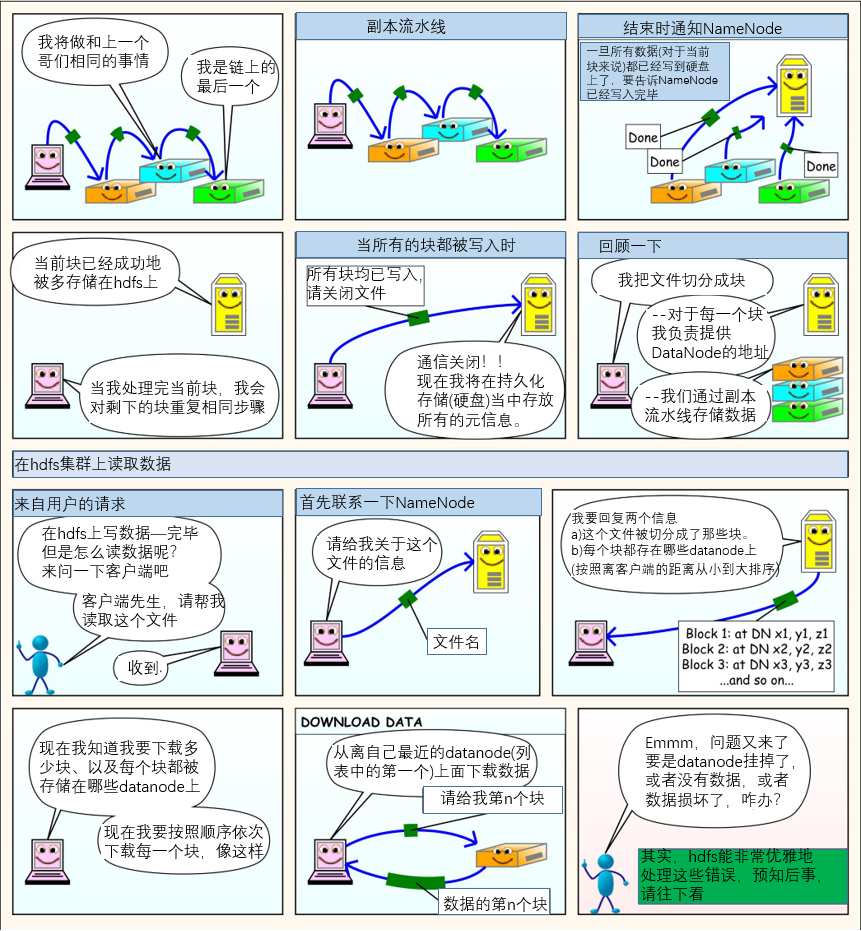
几张图让你理解hdfs工作原理(细节内容后面介绍,先看几张漫画感受一下)
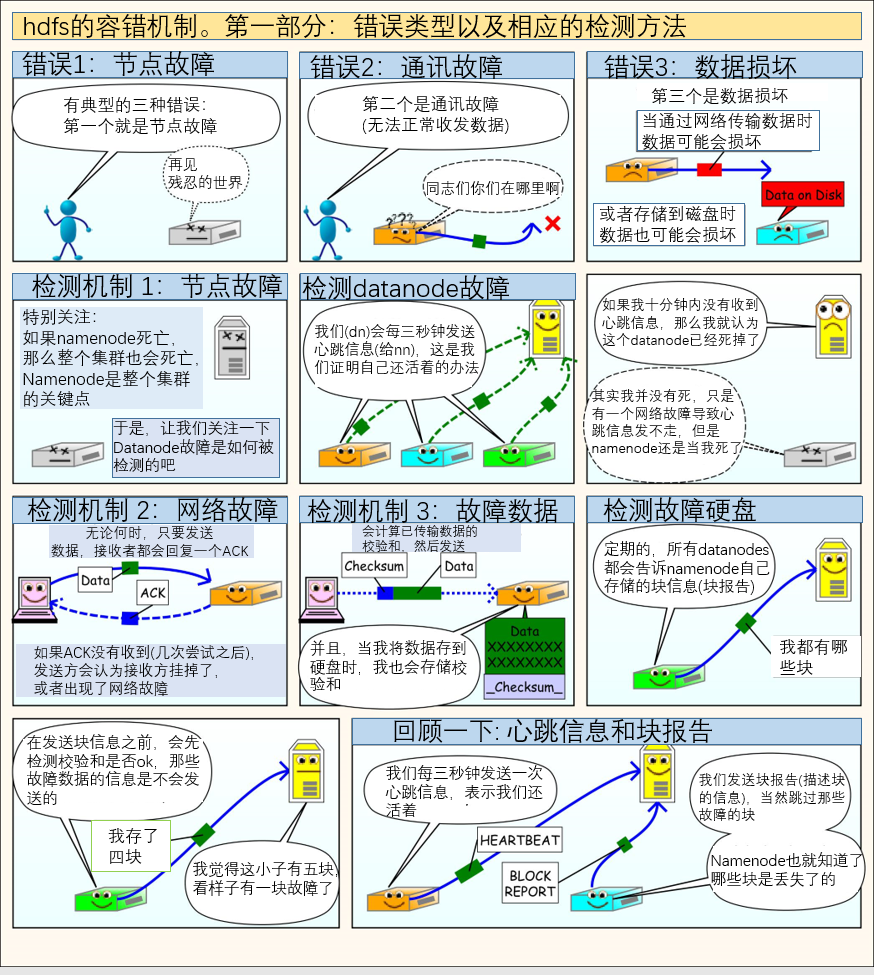
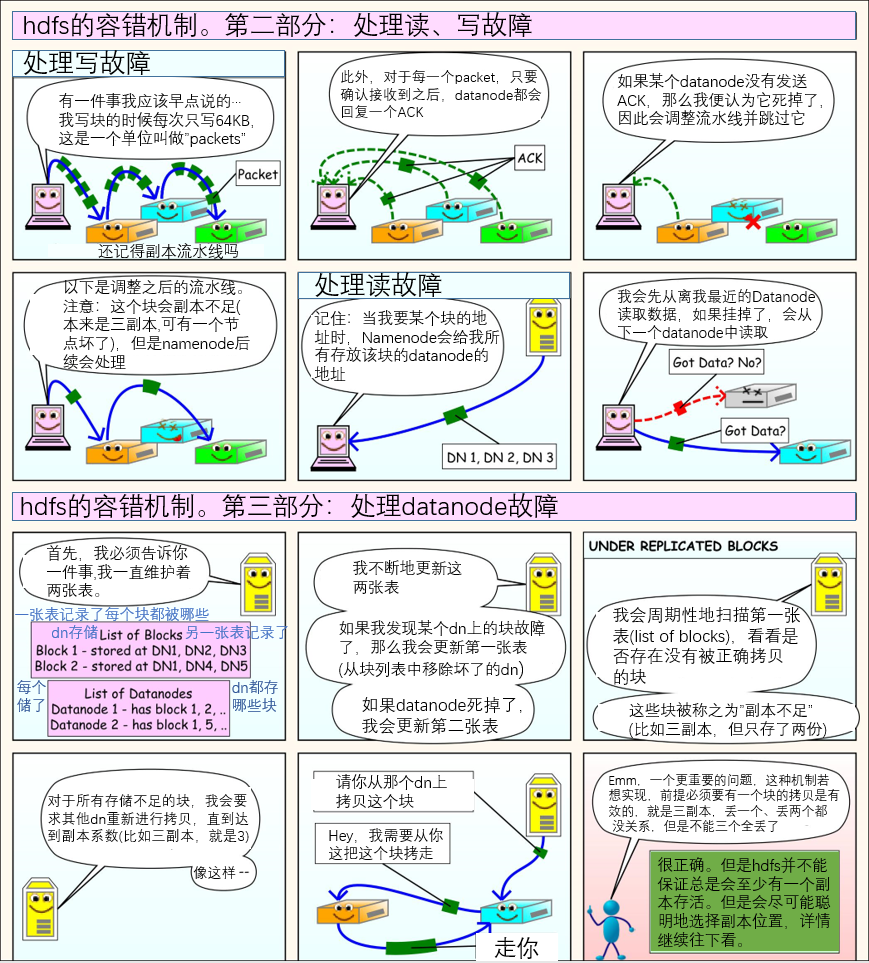
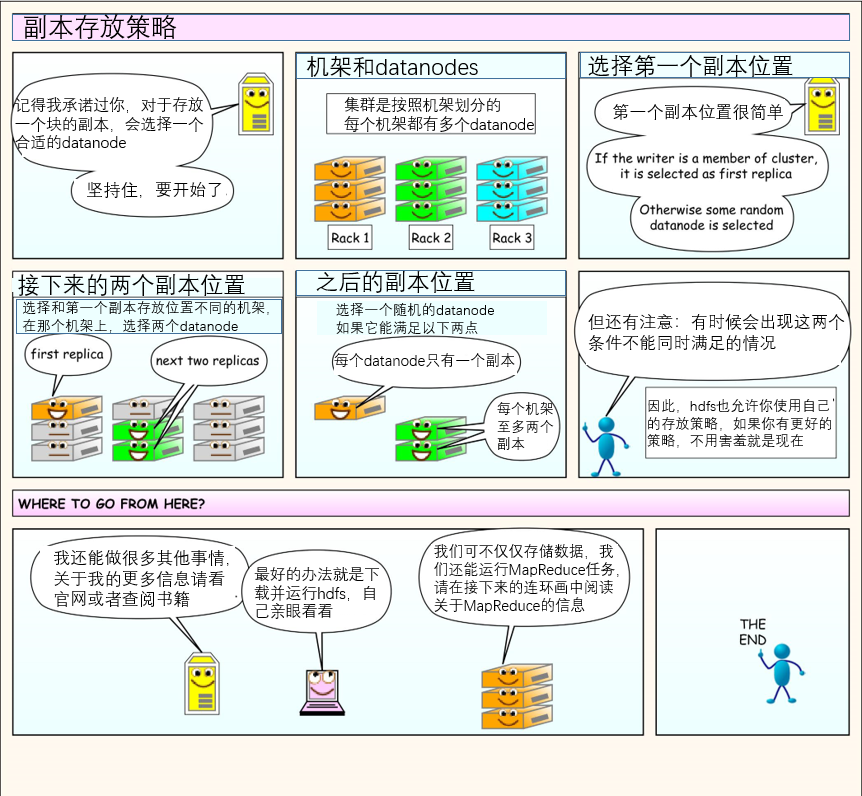
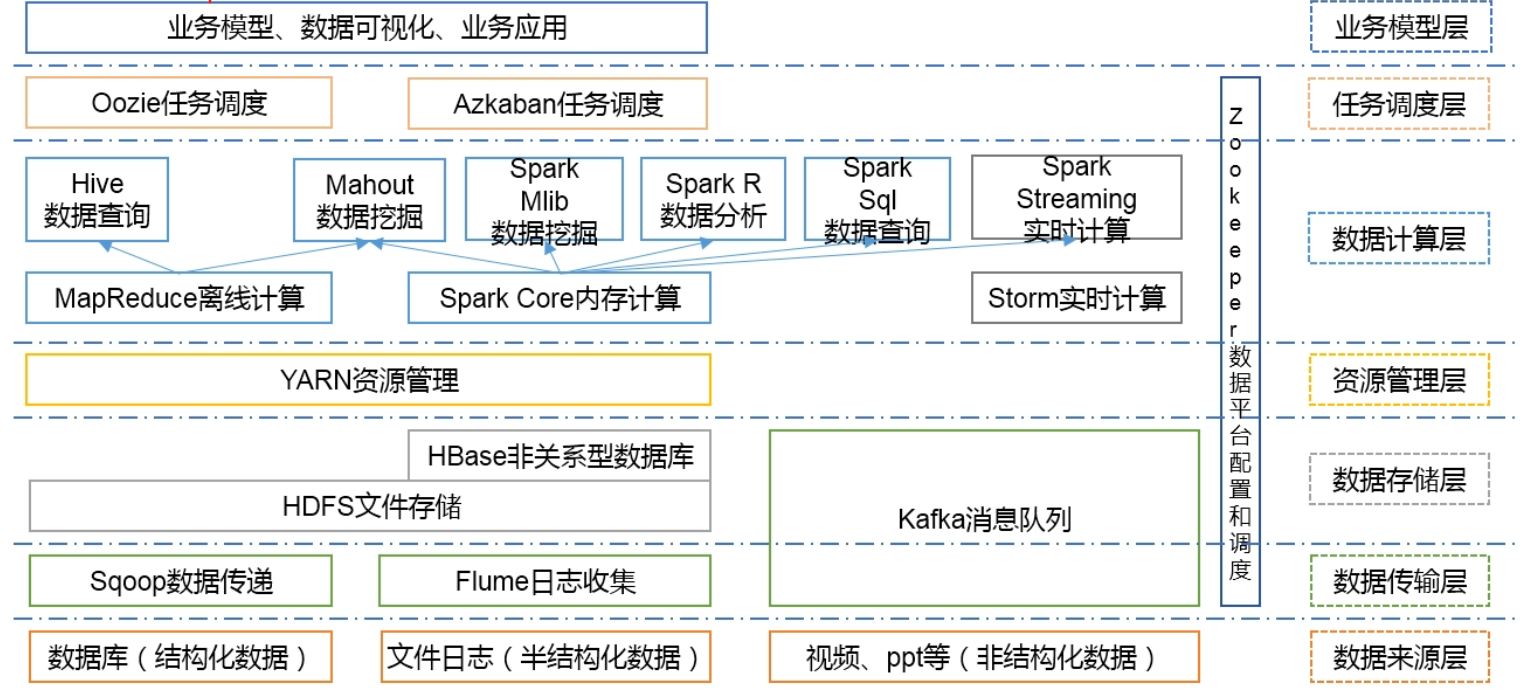
大数据技术生态体系
安装
下面我们来配置一下环境,我的所有大数据组件都安装在/opt目录下面

hadoop是java语言编写的,因此需要安装jdk,我这里已经安装了,安装jdk非常简单,可以自行查找方法,如果还不会的话,那么hadoop也可以不用学了。
下面安装hadoop,这个安装java一样简单。这里我们使用社区版,直接去hadoop.apache.org网站下载即可,然后拷贝到我的阿里云、解压、配置环境变量即可。
然后在家目录中输入hdfs dfs,如果出现如下内容,证明安装并且环境变量配置都没问题

hadoop目录结构
hadoop目录结构如下,我们依次来看。

bin目录
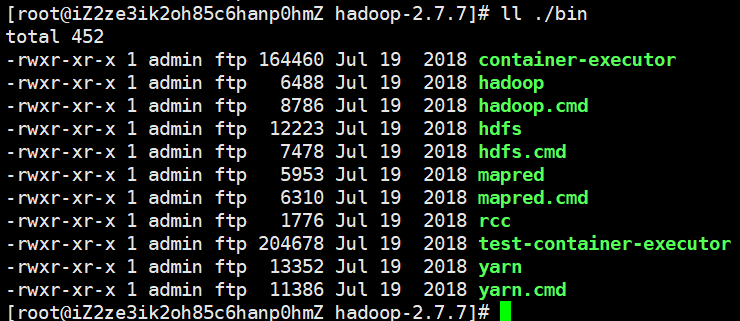
bin目录主要放一些有关服务的文件,比如hadoop、hdfs、yarn等等
etc目录

里面是有一个hadoop目录,但是hadoop目录里面有很多配置文件,未来我们会改大概七八个左右,当然不用怕
include目录
这是与C语言有关的一些头文件,我们不用管
lib目录
一些本地库,.so文件,相当于windows的.dll文件,这个不需要关注
libexec目录
和lib目录类似
sbin目录

非常重要的一个目录,存放了大量的启动文件,比如启动、关闭集群,启动、关闭yarn等等
share目录
存放了一些手册、案例等等
伪分布式环境搭建以及配置、启动hdfs
hadoop的运行模式有三种,单机模式、伪分布式、完全分布式。
单机模式:基本不用,不用管伪分布式:按照完全分布式来进行搭建、配置,但是机器只有一台完全分布式:真正意义上的多台机器
下面就来搭建伪分布式环境,首先要修改配置文件,之前我们说要修改七八个,但是目前先配三个就行,慢慢来,所有的配置文件都在hadoop安装目录/etc/hadoop下面
hadoop-env.sh

export JAVA_HOME=/opt/java/jdk1.8.0_221(默认是${JAVA_HOME},需要手动改成java的安装路径)
core-site.xml
<!--指定hdfs中NameNode的地址-->
<!--这里之所以是localhost,是因为我们只有一台机器,多台机器就要换成相应的主机名-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!--指定hadoop运行时产生文件的存储目录,如果不指定,那么重启之后就丢失了-->
<!--data目录会自动创建-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoop-2.7.7/data</value>
</property>
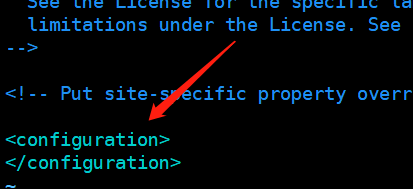
所有更改完的配置,都放在configuration标签里面
hdfs-site.xml
<!--指定hdfs副本的数量,默认是3,我们是伪分布式,所以改成1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
配置完毕,下面启动集群(伪)
格式化namenode(第一次启动时格式化,以后不需要总格式化)
hdfs namenode -format
查看之前的data目录,自动帮我们创建了,而且里面也有东西了

启动namenode
如果把sbin目录也配置了环境变量,那么sbin/也不需要加
sbin/hadoop-daemon.sh start namenode
启动datanode
sbin/hadoop-daemon.sh start datanode
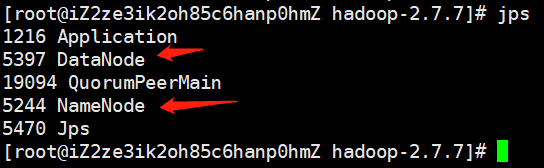
查看集群是否启动成功
输入jps
注意jps是java的一个命令,必须安装jdk之后才可使用,否则会提示命令未找到,出现如下内容表示安装成功
输入ip:50070

如果能访问,也表示安装成功
NameNode格式化注意事项
思考:为什么不能一直格式化NameNode,格式化NameNode需要注意什么?
格式化NameNode会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往的数据。所以格式化NameNode的时候,务必要先删除data数据和log日志,然后再格式化NameNode。因为两者需要有一个共同的id,这样才能交互。
配置、启动yarn
老规矩,先修改配置文件
yarn-env.sh
和hadoop-env.sh一样,配置java的路径
加上export JAVA_HOME=/opt/java/jdk1.8.0_221
yarn-site.xml
<!--reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定yarn的ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>主机名</value>
</property>
mapred-env.sh
老规矩,遇到env.sh都是配JAVA_HOME
mapred-site.xml
但是会发现没有这个文件,不过有一个mapred-site.xml.template
可以cp mapred-site.xml.template mapred-site.xml
<!--指定MR运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
修改完毕,下面启动集群
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager

通过网页查看一下,输入ip:8088,我们之前好像输入过50070,那个是查看hdfs的,8088是查看运行MapReduce程序的进程的。

配置运行历史服务
有时候我们想看一下程序的历史运行情况,那么我们可以配置一下。
插一句,目前一直在搭建、配置环境,当然后面会详细介绍hdfs、MapReduce的相关操作,目前先把环境打好。
当然如果对运行历史不感兴趣的话就跳过,当然最好还是关注一下。
mapred-site.xml
<!--还是这个配置文件,指定历史服务端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>主机名:10020</value>
</property>
<!--历史web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>主机名:19888</value>
</property>
启动历史服务器:sbin/mr-jobhistory-daemon.sh start historyserver
jps查看历史服务器,或者http://ip:19888/jobhistory
hdfs介绍
下面就开始着重讲解hadoop组件之一的hdfs,之前的几张漫画只是提前感受一下。还有目前我们搭建的都是伪分布式,至于完全分布式,由于我阿里云机器只有一台所以就不演示怎么搭建了。最主要的是笔者是python和golang系的,集群的搭建什么的应该用不到,环境什么的会有其他人负责,我只负责连接、计算什么的。后面也会介绍如何使用python和golang连接hdfs,所以完全分布式如何搭建,这里就不介绍了。
我们下面的演示都是基于伪分布式的

hdfs产生背景
随着数据量越来越大,在一台机器上无法存下所有的数据,那么就分配到更多的机器上,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。hdfs只是分布式文件管理系统中的一种
hdfs定义
hdfs(hadoop distributed file system),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色
hdfs的使用场景
适合一次写入,多次读出的场景,且不支持文件的修改。适合用来做数据分析,并不适合做网盘应用。
hdfs的优缺点
优点:
高容错性数据自动保存多个副本,它通过增加副本的形式,提高容错性某一个副本丢失后,它可以自动恢复
适合处理大数据数据规模:能够处理TB、甚至PB级别的数据文件规模:能够处理百万规模以上的文件数量,数量相当之大
可构建在廉价的机器之上,通过多副本机制,提高可靠性
缺点:
-
不适合低延时数据访问,如果你想做到毫秒级存储,别想了,做不到的 -
无法高效地对大量小文件进行存储,存一个1G的数据比存10个100MB加上一个24MB的数据要高效很多至于为什么,因为NameNode是不是唯一的啊,这就意味着空间是有限的,不可能像DataNode一样,容量不够了就加机器。而NameNode要记录文件的元数据,不管你是1KB,还是1GB,都需要150字节的空间进行记录,如果全是小文件的话,是不是很耗费NameNode所在机器的空间呢?
而且小文件存储的寻址时间会超过读取时间,它违反了hdfs的设计目标。
-
不支持并发写入、文件随机修改一个文件只能有一个写,不允许多个线程同时写
仅支持数据的append,不支持文件的随机修改
hdfs的架构
先看官网给的一张图

NameNode(nn):就是master,它是一个主管、管理者
管理hdfs的名称空间配置副本策略管理数据块(block)映射信息处理客户端读写请求
DataNode(nn):就是slave,NameNode下达命令,DataNode执行实际的操作
存储实际的数据块执行数据块的读/写操作
client:就是客户端
文件切分,文件上传到hdfs的时候,client将文件切分成一个个的block,然后上传与NameNode交互,获取文件的位置信息与DataNode交互,读取或者写入数据客户端提供一些命令来管理hdfs,比如NameNode的格式化客户端可以通过一些命令来访问hdfs,比如对hdfs的增删改查操作
secondary NameNode:它不是NameNode的替补,当NameNode挂掉时,并不能马上替换NameNode并提供服务。
辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode紧急情况下,可辅助恢复NameNode(可以恢复一部分)
强烈建议结合之前的漫画来理解,会有更好的体验
hdfs块的大小设置
hdfs中的文件在物理上是分块存储(block),块的大小可以通过配置参数(df.blocksize)指定,默认大小在hadoop 2.x版本中是128M,老版本中是64M
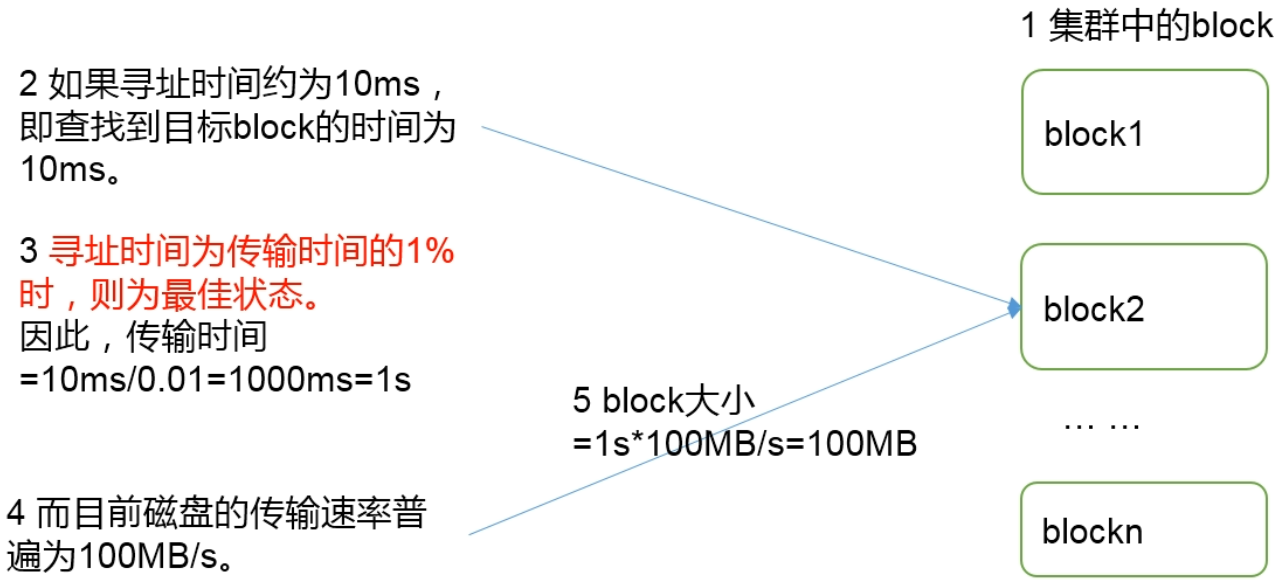
思考:为什么块不能设置太小,也不能设置太大?
1.hdfs块设置太小,会增加寻址时间,程序一直在找块的开始位置
2.hdfs块设置太大,从磁盘传输的时间会明显大于定位这个块的开始位置所需要的时间。导致程序在处理这块数据时,会非常慢。
总结:hdfs块的大小设置主要取决于磁盘的传输速率
hdfs shell命令(重点)
基本语法:hdfs dfs 命令 参数
这个hdfs的shell命令和linux是非常类似的,比如查看某个目录下的文件,linux中是ls,那么hdfs shell中就是hdfs dfs -ls,查看文件内容,hdfs dfs -cat filename,可以看到是非常相似的,只不过在hdfs shell中需要加上一个横杠。另外hdfs dfs还可以写成hadoop fs,对于shell操作来说两者区别不大
启动集群
sbin/start-dfs.sh sbin/start-yarn.sh
之前我们说过hadoop-daemon.sh和yarn-daemon.sh,那是对于伪分布式也就是单节点来说的,如果是启动集群需要使用sbin/start-dfs.sh sbin/start-yarn.sh
hdfs dfs -help 命令
从linux命令也能看出来,这是一个查看命令使用方法的命令
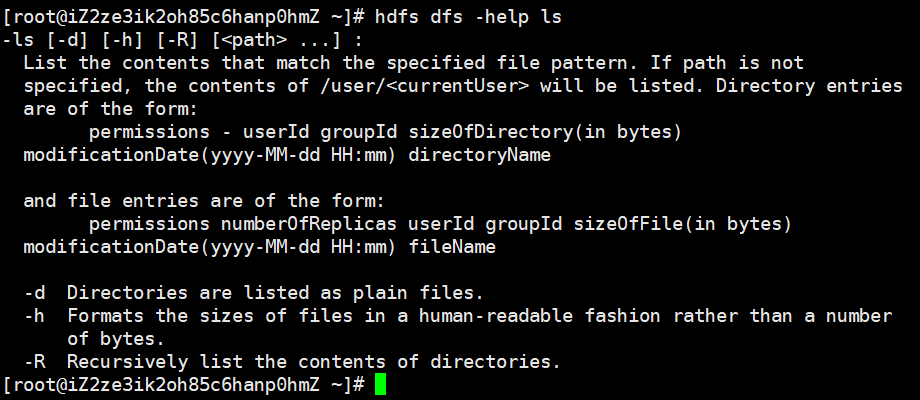
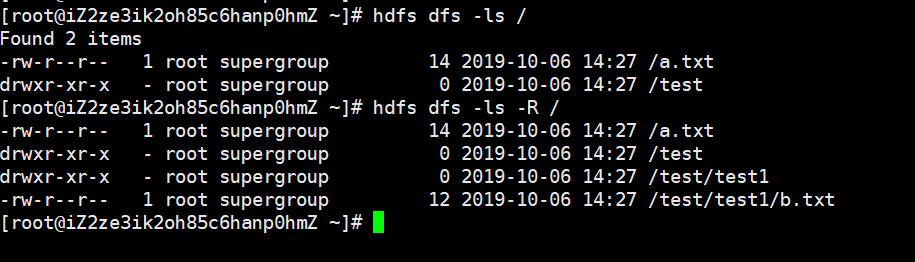
hdfs dfs -ls 目录路径
查看某个目录有哪些文件,加上-R表示递归显示
hdfs dfs -mkdir 目录
在hdfs上面创建目录,加上-p表示递归创建,和linux是一样的

hdfs dfs -moveFromLocal 本地路径 hdfs路径
将本地文件或目录移动到hdfs上面,注意是移动,移完之后本地就没了

hdfs dfs -cat 文件
查看一个文件的内容

hdfs dfs -appendToFile 追加的文件 追加到哪个文件
将一个文件的内容追加到另一个文件里面去,比如本地有一个file.txt,那么hdfs dfs -appendToFile file.txt /a.txt表示将本地的file.txt文件里面的内容追加到hdfs上的/a.txt文件里面去

-chgrp、-chmod、-chown
更改组、更改权限、更改所有者,这个和linux中用法一样
hdfs dfs -copyFromLocal 本地路径 hdfs路径
将文件从本地拷贝到hdfs上面去,这个和刚才moveFromLocal就类似于linux中cp和mv
hdfs dfs -copyToLocal hdfs路径 本地路径
将hdfs上的文件拷贝到本地,这个路径是hdfs路径在前、本地路径在后。

hdfs dfs -cp hdfs路径 hdfs路径
copyFromLocal是针对本地和hdfs来说了,cp是hdfs路径和hdfs路径之间的拷贝

hdfs dfs -mv hdfs路径 hdfs路径
不用说也能明白
hdfs dfs -get hdfs路径 本地路径
等同于copyToLocal
hdfs dfs -put 本地路径 hdfs路径
等同于copyFromLocal
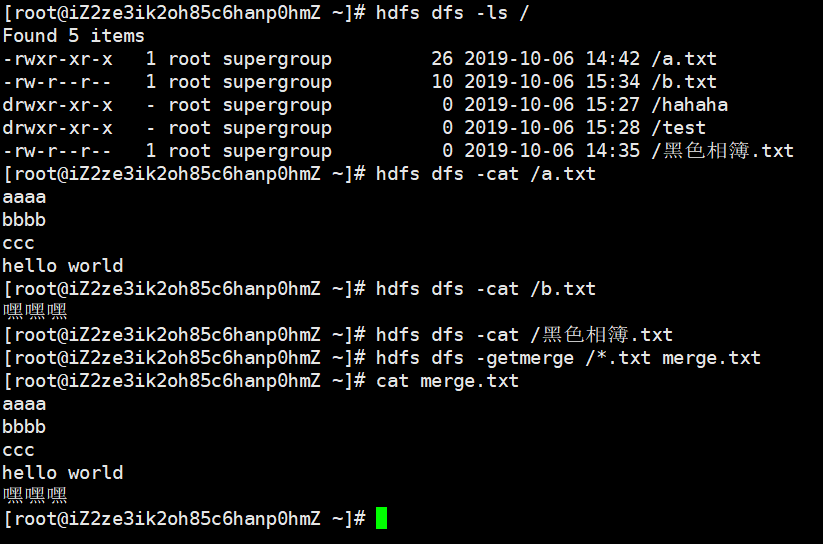
hdfs dfs -getmerge hdfs路径(通配符) 本地路径
将hdfs上面的多个文件合并下载到本地
hdfs dfs -tail 文件名
显示文件的结尾
hdfs dfs -rm 文件
删除文件,如果是文件夹需要加上-r
hdfs dfs -rmdir 空目录
删除一个空目录,不常用,一般使用-rm
hdfs dfs -du 目录
统计目录的大小信息

hdfs dfs -du -h /:加上-h人性化显示
hdfs dfs -du -h -s / :查看当前目录的总大小
hdfs dfs -setrep 数值 文件
设置文件的副本数量,hdfs dfs -setrep 5 /file.txt:表示将file.txt的副本设置成5
python连接hdfs进行相关操作
下面我们来介绍如何使用python操作hdfs,首先python若想操作hdfs,需要下载一个第三方库,也叫hdfs,直接pip install hdfs即可。
import hdfs
from pprint import pprint
# 导入相关模块,输入http://ip:50070,创建客户端
client = hdfs.Client("http://ip:50070")
client.list:查看当前目录的内容
print(client.list("/")) # ['黑色相簿.txt', 'a.txt', 'b.txt', 'test']
# status默认为False,表示是否显示文件的相关属性
# 返回数据的格式为:[("", {}), ("", {}), ("", {}), ...]
pprint(client.list("/", status=True))
"""
[('黑色相簿.txt',
{'accessTime': 1570347361399,
'blockSize': 134217728,
'childrenNum': 0,
'fileId': 16393,
'group': 'supergroup',
'length': 0,
'modificationTime': 1570343722271,
'owner': 'root',
'pathSuffix': '黑色相簿.txt',
'permission': '644',
'replication': 1,
'storagePolicy': 0,
'type': 'FILE'}),
('a.txt',
{'accessTime': 1570347222071,
'blockSize': 134217728,
'childrenNum': 0,
'fileId': 16386,
'group': 'supergroup',
'length': 26,
'modificationTime': 1570344172155,
'owner': 'root',
'pathSuffix': 'a.txt',
'permission': '755',
'replication': 1,
'storagePolicy': 0,
'type': 'FILE'}),
('b.txt',
{'accessTime': 1570347263315,
'blockSize': 134217728,
'childrenNum': 0,
'fileId': 16396,
'group': 'supergroup',
'length': 10,
'modificationTime': 1570347263628,
'owner': 'root',
'pathSuffix': 'b.txt',
'permission': '644',
'replication': 1,
'storagePolicy': 0,
'type': 'FILE'}),
('test',
{'accessTime': 0,
'blockSize': 0,
'childrenNum': 2,
'fileId': 16387,
'group': 'supergroup',
'length': 0,
'modificationTime': 1570346913737,
'owner': 'root',
'pathSuffix': 'test',
'permission': '755',
'replication': 0,
'storagePolicy': 0,
'type': 'DIRECTORY'})]
"""
client.status:获取指定路径的状态信息
pprint(client.status("/"))
"""
{'accessTime': 0,
'blockSize': 0,
'childrenNum': 4,
'fileId': 16385,
'group': 'supergroup',
'length': 0,
'modificationTime': 1570347630036,
'owner': 'root',
'pathSuffix': '',
'permission': '755',
'replication': 0,
'storagePolicy': 0,
'type': 'DIRECTORY'}
"""
# 里面还有一个strict=True,表示严格模式
# 如果改为False,那么如果输入的路径不存在就返回None
# 为True的话,路径不存在,报错
client.makedirs:创建目录
print(client.list("/")) # ['黑色相簿.txt', 'a.txt', 'b.txt', 'test']
# 会自动递归创建,如果想创建的时候给目录赋予权限,可以使用permission参数,默认为None
client.makedirs("/a/b/c", permission=777)
print(client.list("/")) # ['黑色相簿.txt', 'a', 'a.txt', 'b.txt', 'test']
print(client.list("/a")) # ['b']
print(client.list("/a/b")) # ['c']
client.rename:重命名
print(client.list("/")) # ['黑色相簿.txt', 'a', 'a.txt', 'b.txt', 'test']
client.rename("/黑色相簿.txt", "/白色相簿")
print(client.list("/")) # ['白色相簿', 'a', 'a.txt', 'b.txt', 'test']
client.write:往文件里面写内容
client.read:往文件里面读内容
关于写、读、上传、下载,如果报错,出现了requests.exceptions.ConnectionError:xxxxx,那么解决办法就是在你当前使用python的Windows机器上的hosts文件中增加如下内容:部署hadoop的服务器ip 部署hadoop的服务器主机名
如果出现了hdfs.util.HdfsError: Permission denied: user=dr.who, access=WRITE,······异常,那么需要在hdfs-site.xml中加入如下内容
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
下面就开始写数据、读数据
with client.write("/这是一个不存在的文件.txt") as writer:
# 需要传入字节
writer.write(bytes("this file not exists", encoding="utf-8"))
with client.read("/这是一个不存在的文件.txt") as reader:
# 读取出来也是字节类型
print(reader.read()) # b'this file not exists'
write方法,如果不指定额外的参数,那么需要文件不能存在,否则会报错,提示文件已经存在。如果要对已存在的文件进行操作,那么需要显式的指定参数:overwrite(重写)或者append(追加)
with client.write("/白色相簿", append=True) as writer:
writer.write(bytes("令人讨厌的冬天又来了,", encoding="utf-8"))
with client.read("/白色相簿") as reader:
print(str(reader.read(), encoding="utf-8")) # 令人讨厌的冬天又来了,
with client.write("/白色相簿", append=True) as writer:
writer.write(bytes("冬天的街道,恋人们的微笑,让人想一把火全烧了", encoding="utf-8"))
with client.read("/白色相簿") as reader:
# 由于是追加,之前的内容也读取出来了
print(str(reader.read(), encoding="utf-8")) # 令人讨厌的冬天又来了,冬天的街道,恋人们的微笑,让人想一把火全烧了
with client.write("/白色相簿", overwrite=True) as writer:
writer.write(bytes("暖かい日差しが降り注いできて、眩しすぎ、目が見えない", encoding="utf-8"))
with client.read("/白色相簿") as reader:
# 如果是overwrite,那么之前的内容就全没了
print(str(reader.read(), encoding="utf-8")) # 暖かい日差しが降り注いできて、眩しすぎ、目が見えない
注意:overwrite和append不能同时出现,否则报错
# 如果write里面传入了encoding参数,那么writer.write则需要写入str,因为会自动按照传入的encoding进行编码
with client.write("/白色相簿", overwrite=True, encoding="utf-8") as writer:
girls = ["古明地觉", "古明地恋", "八重樱"]
writer.write(str(girls))
# 同理如果传入了encoding参数,reader.read会读出str,因为会自动按照传入的encoding进行解码
with client.read("/白色相簿", encoding="utf-8") as reader:
print(reader.read()) # ['古明地觉', '古明地恋', '八重樱']
client.content:查看目录的汇总情况
比如:当前目录下有多少个子目录、多少文件等等
print(client.content("/", strict=True))
# {'directoryCount': 6, 'fileCount': 6, 'length': 95, 'quota': 9223372036854775807, 'spaceConsumed': 95, 'spaceQuota': -1}
client.set_owner:设置所有者
client.set_permission:设置权限
client.set_replication:设置副本系数
client.set_times:设置时间
"""
def set_owner(self, hdfs_path, owner=None, group=None):
def set_permission(self, hdfs_path, permission):
def set_replication(self, hdfs_path, replication):
def set_times(self, hdfs_path, access_time=None, modification_time=None):
"""
client.resolve: 将带有符号的路径,转换成绝对、规范化路径
# 当然并不要求路径真实存在
print(client.resolve("/白色相簿/白色相簿/..")) # /白色相簿
client.walk:递归遍历目录
# 递归遍历文件,类似于os.walk,会返回一个生成器,可以进行迭代
# 每一步迭代的内容是一个三元组,("路径", ["目录1", "目录2"], ["文件1", "文件2", "文件3"])
for file in client.walk("/"):
print(file)
"""
('/', ['a', 'test'], ['白色相簿', '这是一个不存在的文件.txt', 'a.txt', 'b.txt'])
('/a', ['b'], [])
('/a/b', ['c'], [])
('/a/b/c', [], [])
('/test', ['test1'], ['黑色相簿.txt'])
('/test/test1', [], ['b.txt'])
"""
client.upload:上传文件
print("2.py" in client.list("/")) # False
client.upload(hdfs_path="/", local_path="2.py")
print("2.py" in client.list("/")) # True
client.download:下载文件
client.download(hdfs_path="/白色相簿", local_path="白色相簿")
print(open("白色相簿", "r", encoding="utf-8").read()) # ['古明地觉', '古明地恋', '八重樱']
client.checksum:获取文件的校验和
# 获取文件的校验和
print(client.checksum("/白色相簿"))
# {'algorithm': 'MD5-of-0MD5-of-512CRC32C', 'bytes': '00000200000000000000000095b1c9929656ce2b779093c67c95b76000000000', 'length': 28}
client.delete:删除文件或目录
# recursive表示是否递归删除,默认为False
try:
client.delete("/test")
except Exception as e:
print(e) # `/test is non empty': Directory is not empty
print("test" in client.list("/")) # True
client.delete("/test", recursive=True)
print("test" in client.list("/")) # False
golang操作hdfs
golang连接hdfs同样需要一个第三方驱动,golang连接hdfs的驱动推荐两个,一个也叫hdfs,另一个叫gowfs。先来看看怎么安装。
安装hdfs稍微有点费劲,首先可以通过go get github.com/colinmarc/hdfs下载,因为总所周知的原因,不出意外会失败,报出如下错误

那么我们需要先在gopath(第三方包安装的位置,一般是进入C盘,点击用户,再点击你的用户名对应的目录,然后就会看到一个go目录,我这里是C:Userssatorigo)的src目录下新建golang.org/x目录,然后进入到golang.org/x下,在此处打开命令窗口,然后执行git clone https://github.com/golang/crypto
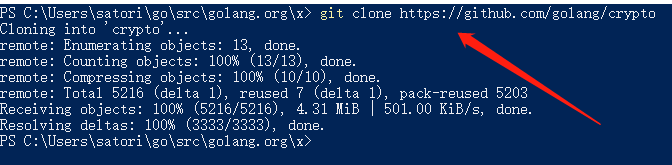
然后再执行go get github.com/colinmarc/hdfs就没问题了
至于安装gowfs就简单多了,直接go get github.com/vladimirvivien/gowfs就没问题了
但是我们使用哪一个呢?个人推荐使用gowfs,下面我们就来看看怎么用。
读取文件
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
"io/ioutil"
)
func main() {
//这是配置,传入Addr: "ip: 50070", User: "随便写一个英文名就行"
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
//返回一个客户端(这里面叫文件系统)和error
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:",err))
}
//这里不能直接传入文件名,而是需要作为gowfs.Path结构体的Name参数的值
//然后将Path传进去,我们后面的api都是这样做的
path := gowfs.Path{Name:"/whitealbum.txt"}
//接收如下参数:gowfs.Path,offset(偏移量),长度(显然是字节的长度), 容量(自己的cap)
//返回一个io.ReadCloser,这是需要实现io.Reader和io.Closer的接口
reader, _ := client.Open(path, 0, 512, 2048)
//可以使用reader.Read(buf)的方式循环读取,也可以丢给ioutil。ReadAll,一次性全部读取
data, _ := ioutil.ReadAll(reader)
fmt.Println(string(data))
/*
白色相簿什么的,已经无所谓了。
因为已经不再有歌,值得去唱了。
传达不了的恋情,已经不需要了。
因为已经不再有人,值得去爱了。
*/
}
查看目录有哪些内容
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
path := gowfs.Path{Name: "/"}
// 返回[]FileStatus和error
//这个FileStatus是什么?我们看一下源码
/*
type FileStatus struct {
AccesTime int64 访问时间
BlockSize int64 块大小,只针对文件(134217728 Bytes,128 MB),目录的话为0
Group string 所属组
Length int64 文件的字节数(目录为0)
ModificationTime int64 修改时间
Owner string 所有者
PathSuffix string 文件后缀,说白了就是文件名
Permission string 权限
Replication int64 副本数
Type string 类型,文本的话是FILE,目录的话是DIRECTORY
}
*/
fs_arr, _ := client.ListStatus(path)
fmt.Println(fs_arr)
// [{0 0 supergroup 0 1570359570447 dr.who tkinter 755 0 DIRECTORY} {0 134217728 supergroup 184 1570359155457 root whitealbum.txt 644 1 FILE}]
for _, fs := range fs_arr {
fmt.Println("文件名:", fs.PathSuffix)
/*
文件名: tkinter
文件名: whitealbum.txt
*/
}
//FileStatus里面包含了文件的详细信息,如果想查看某个文件的详细信息
//可以使用fs, err := client.GetFileStatus(path)
}
创建文件
package main
import (
"bytes"
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
path := gowfs.Path{Name: "/黑色相簿.txt"}
/*
Create函数接收如下参数。
data:io.Reader,一个实现了io.Reader接口的struct
Path:很简单,就是我们这里的path
overwrite:是否覆盖,如果为false表示不覆盖,那么要求文件不能存在,否则报错
blocksize:块大小
replication:副本
permission:权限
buffersize:缓存大小
contenttype:内容类型
返回一个bool和error
*/
if flag, err :=client.Create(
bytes.NewBufferString("这是黑色相簿,不是白色相簿"), //如果不指定内容,就直接bytes.NewBufferString()即可
path, //路径
false,//不覆盖
0,
0,
0666,
0,
"text/html", //纯文本格式
); err != nil {
fmt.Println("创建文件出错,错误为:", err)
} else {
fmt.Println("创建文件成功, flag =", flag) //创建文件成功, flag = true
}
}
查看一下
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
"io/ioutil"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
path := gowfs.Path{Name: "/黑色相簿.txt"}
reader , _ := client.Open(path, 0, 512, 2048)
data, _ := ioutil.ReadAll(reader)
fmt.Println(string(data)) // 这是黑色相簿,不是白色相簿
}
创建目录
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
path := gowfs.Path{Name: "/a/b/c"}
//递归创建
flag, err := client.MkDirs(path, 0666)
fmt.Println(flag) // true
fs_arr, _ := client.ListStatus(gowfs.Path{Name:"/"})
for _, fs := range fs_arr{
fmt.Println(fs.PathSuffix)
/*
黑色相簿.txt
a
tkinter
whitealbum.txt
*/
}
}
重命名
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
fs_arr, _ := client.ListStatus(gowfs.Path{Name:"/"})
for _, fs := range fs_arr{
fmt.Println(fs.PathSuffix)
/*
黑色相簿.txt
a
tkinter
whitealbum.txt
*/
}
flag, err := client.Rename(gowfs.Path{Name:"/黑色相簿.txt"}, gowfs.Path{Name:"/blackalbum.txt"})
fmt.Println(flag) // true
fs_arr, _ = client.ListStatus(gowfs.Path{Name:"/"})
for _, fs := range fs_arr{
fmt.Println(fs.PathSuffix)
/*
a
blackalbum.txt
tkinter
whitealbum.txt
*/
}
}
向已经存在的文件追加内容
package main
import (
"bytes"
"fmt"
"github.com/vladimirvivien/gowfs"
"io/ioutil"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
path := gowfs.Path{Name: "/whitealbum.txt"}
reader, _ := client.Open(path, 0, 512, 2048)
data, _ := ioutil.ReadAll(reader)
fmt.Println(string(data))
/*
白色相簿什么的,已经无所谓了。
因为已经不再有歌,值得去唱了。
传达不了的恋情,已经不需要了。
因为已经不再有人,值得去爱了。
*/
//参数1:内容,必须是实现了io.Reader接口
//参数2:路径
//参数3:缓存大小
flag, err := client.Append(bytes.NewBufferString("
让人讨厌的冬天又来了"), path, 2048)
fmt.Println(flag) // true
reader, _ = client.Open(path, 0, 512, 2048)
data, _ = ioutil.ReadAll(reader)
fmt.Println(string(data))
/*
白色相簿什么的,已经无所谓了。
因为已经不再有歌,值得去唱了。
传达不了的恋情,已经不需要了。
因为已经不再有人,值得去爱了。
让人讨厌的冬天又来了。
*/
}
设置文件或目录的所有者
func (fs *FileSystem) SetOwner(path Path, owner string, group string) (bool, error)
设置文件或目录的权限
func (fs *FileSystem) SetPermission(path Path, permission os.FileMode) (bool, error)
设置文件或目录的副本系数
func (fs *FileSystem) SetReplication(path Path, replication uint16) (bool, error)
设置文件或目录的访问时间和修改时间
func (fs *FileSystem) SetTimes(path Path, accesstime int64, modificationtime int64) (bool, error)
获取文件的校验和
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
path := gowfs.Path{Name: "/whitealbum.txt"}
f, _ := client.GetFileChecksum(path)
fmt.Println(f) // {MD5-of-0MD5-of-512CRC32C 0000020000000000000000001255073187d3e801940eee180acebe4e00000000 28}
fmt.Println(f.Algorithm, f.Length, f.Bytes) // MD5-of-0MD5-of-512CRC32C 28 0000020000000000000000001255073187d3e801940eee180acebe4e00000000
}
删除文件
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
path := gowfs.Path{Name:"/blackalbum.txt"}
//路径,是否递归
flag, _ := client.Delete(path, true)
fmt.Println(flag) // true
}
判断文件是否存在
为什么这里用蓝色了,因为之后的用法就不一样了
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, err := gowfs.NewFileSystem(config)
if err != nil {
panic(fmt.Sprintln("出现异常,异常信息为:", err))
}
//创建一个shell,可以使用下面shell进行操作
shell := gowfs.FsShell{FileSystem: client}
//直接传字符串即可,不需要传Path了
flag, _ := shell.Exists("/whitealbum.txt")
fmt.Println(flag) // true
flag, _ = shell.Exists("/whitealbum.txt1")
fmt.Println(flag) // false
}
改变所有者
flag, _ := shell.Chown([]string{"/file1", "/file2", "/file3"}, "owner")
改变所属组
flag, _ := shell.Chgrp([]string{"/file1", "/file2", "/file3"}, "groupName")
改变权限
flag, _ := shell.Chmod([]string{"/file1", "/file2", "/file3"}, 0666)
查看文件内容
package main
import (
"bytes"
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, _ := gowfs.NewFileSystem(config)
shell := gowfs.FsShell{FileSystem: client}
buf := bytes.Buffer{}
if err := shell.Cat([]string{"/whitealbum.txt"}, &buf); err != nil {
fmt.Println("err =", err)
} else {
fmt.Println(buf.String())
/*
白色相簿什么的,已经无所谓了。
因为已经不再有歌,值得去唱了。
传达不了的恋情,已经不需要了。
因为已经不再有人,值得去爱了。
让人讨厌的冬天又来了
*/
}
}
追加文件内容
package main
import (
"bytes"
"fmt"
"github.com/vladimirvivien/gowfs"
"io/ioutil"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, _ := gowfs.NewFileSystem(config)
shell := gowfs.FsShell{FileSystem: client}
_ = ioutil.WriteFile("aaa.txt", []byte("
冬马小三
"), 0666)
_ = ioutil.WriteFile("bbb.txt", []byte("雪菜碧池
"), 0666)
_ = ioutil.WriteFile("ccc.txt", []byte("打死春哥
"), 0666)
_ = ioutil.WriteFile("ddd.txt", []byte("抱走冬马雪菜"), 0666)
_, _ = shell.AppendToFile([]string{"aaa.txt", "bbb.txt", "ccc.txt", "ddd.txt"}, "/whitealbum.txt")
buf := bytes.Buffer{}
_ = shell.Cat([]string{"/whitealbum.txt"}, &buf)
fmt.Println(buf.String())
/*
白色相簿什么的,已经无所谓了。
因为已经不再有歌,值得去唱了。
传达不了的恋情,已经不需要了。
因为已经不再有人,值得去爱了。
让人讨厌的冬天又来了
冬马小三
雪菜碧池
打死春哥
抱走冬马雪菜
*/
}
上传文件
package main
import (
"fmt"
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, _ := gowfs.NewFileSystem(config)
shell := gowfs.FsShell{FileSystem: client}
//本地路径,hdfs路径,是否重写
_, _ = shell.Put("aaa.txt", "/aaa.txt", false)
path := gowfs.Path{Name: "/"}
fs_arr, _ := client.ListStatus(path)
for _, fs := range fs_arr {
fmt.Println(fs.PathSuffix)
/*
黑色相簿.txt
a
aaa.txt
tkinter
whitealbum.txt
*/
}
}
下载文件
package main
import (
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, _ := gowfs.NewFileSystem(config)
shell := gowfs.FsShell{FileSystem: client}
_, _ = shell.Get("/whitealbum.txt", "白色album.txt")
}
删除文件
package main
import (
"github.com/vladimirvivien/gowfs"
)
func main() {
config := gowfs.Configuration{Addr: "xx.xx.xx.xx:50070", User: "satori"}
client, _ := gowfs.NewFileSystem(config)
shell := gowfs.FsShell{FileSystem: client}
_, _ = shell.Rm("/whitealbum.txt")
}
MapReduce定义
MapReduce是一个分布式运算程序的编程框架,是用户开发"基于hadoop的数据分析应用"的核心框架
MapReduce的核心功能是将用户编写的业务逻辑代码和自带默认组件组合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。
MapReduce优缺点
优点
-
MapReduce易于编程它简单地实现一些接口,就可以完成一个分布式应用程序,这个分布式应用程序可以分布到大量廉价的pc机器上运行。也就是说,你写一个分布式应用程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点,使得MapReduce编程非常流行 -
良好的扩展性当你的计算资源不足时,你可以通过
简单的增加机器来扩展计算能力 -
高容错性MapReduce设计的初衷就是使程序能够运行在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另一个节点上运行,不至于这个任务完全失败。而且这个过程不需要人工参与,是由hadoop内部完成的。
-
适合PB级以上海量数据的离线处理可以实现上千台服务器集群并发工作,提高数据处理能力
缺点
-
不擅长实时计算MapReduce无法像mysql一样,可以在毫秒级或者秒级内返回结果
-
不擅长流式计算流式计算输入的数据是动态的,而MapReduce的数据数据必须是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的
-
不支持DAG(有向无环图)计算多个程序之间存在依赖,后一个应用程序的输入依赖于上一个程序的输出。在这种情况,MapReduce不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,然后再从磁盘中读取,进行下一个操作,这样做会造成大量的磁盘IO,导致性能非常的低下。