SE模块(Squeeze-and-Excitation)
SENet:
SENet网络的创新点在于关注channel之间的关系,希望模型可以自动学习到不同channel特征的重要程度。为此,SENet提出了Squeeze-and-Excitation (SE)模块。
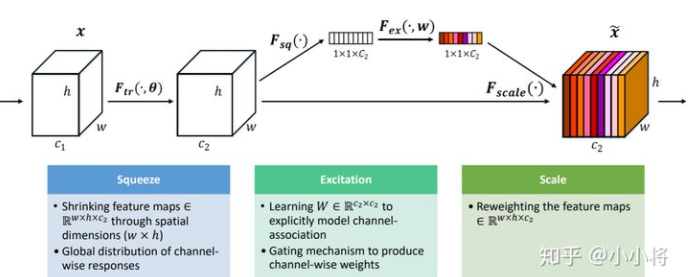
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
Squeeze操作
由于卷积只是在一个局部空间内进行操作, 很难获得足够的信息来提取channel之间的关系,对于网络中前面的层这更严重,因为感受野比较小。为了,SENet提出Squeeze操作,将一个channel上整个空间特征编码为一个全局特征,采用global average pooling来实现(原则上也可以采用更复杂的聚合策略):
Excitation操作
Sequeeze操作得到了全局描述特征,我们接下来需要另外一种运算来抓取channel之间的关系。这个操作需要满足两个准则:首先要灵活,它要可以学习到各个channel之间的非线性关系;第二点是学习的关系不是互斥的,因为这里允许多channel特征,而不是one-hot形式。基于此,这里采用sigmoid形式的gating机制:
其中 。为了降低模型复杂度以及提升泛化能力,这里采用包含两个全连接层的bottleneck结构,其中第一个FC层起到降维的作用,降维系数为r是个超参数,然后采用ReLU激活。最后的FC层恢复原始的维度。
最后将学习到的各个channel的激活值(sigmoid激活,值0~1)乘以U上的原始特征:
其实整个操作可以看成学习到了各个channel的权重系数,从而使得模型对各个channel的特征更有辨别能力,这应该也算一种attention机制。
SE模块在Inception和ResNet上的应用
SE模块的灵活性在于它可以直接应用现有的网络结构中。这里以Inception和ResNet为例。对于Inception网络,没有残差结构,这里对整个Inception模块应用SE模块。对于ResNet,SE模块嵌入到残差结构中的残差学习分支中。

同样地,SE模块也可以应用在其它网络结构,如ResNetXt,Inception-ResNet,MobileNet和ShuffleNet中。
CBAM模块(Convolutional Block Attention Module)
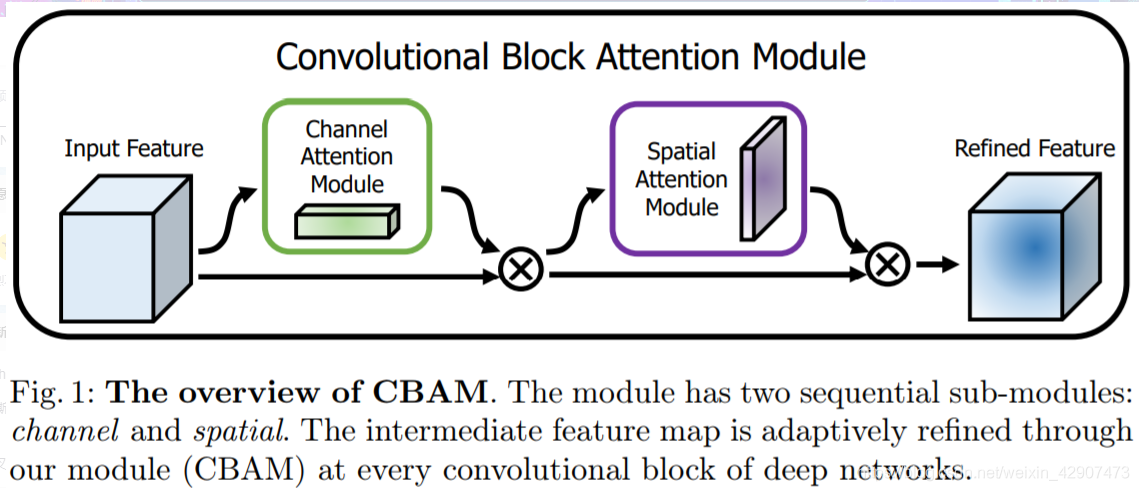
该注意力模块( CBAM ),可以在通道和空间维度上进行 Attention 。其包含两个子模块 Channel Attention Module(CAM) 和 Spartial Attention Module(SAM)。
1、CAM的结构是怎样的?与SE有何区别?
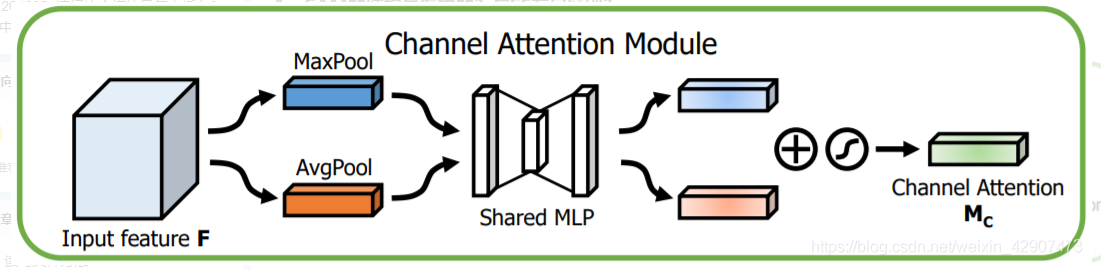
相比SE,只是多了一个并行的Max Pooling层。那为什么加个并行的呢?结果导向,作者通过实验说明这样的效果好一些,我感觉其好一些的原因应该是多一种信息编码方式,使得获得的信息更加全面了。
2、SAM的结构
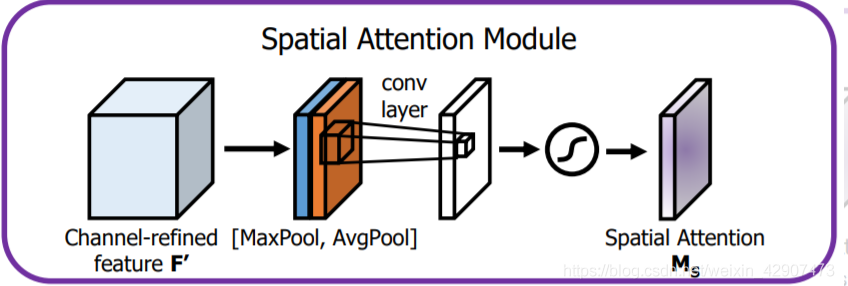
将CAM模块输出的特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
3、组合方式
通道注意力和空间注意力这两个模块可以以并行或者顺序的方式组合在一起,但是作者发现顺序组合并且将通道注意力放在前面可以取得更好的效果。而且是先CAM再SAM效果会更好。对比发现添加了 CBAM 后,模型会更加关注识别物体:

注:残差结构中的残差学习分支:
残差结构简介
神经网络的每一层分别对应于提取不同层次的特征信息,有低层,中层和高层,而网络越深的时候,提取到的不同层次的信息会越多,而不同层次间的层次信息的组合也会越多。
深度学习对于网络深度遇到的主要问题是梯度消失和梯度爆炸,传统对应的解决方案则是数据的初始化(normlized initializatiton)和(batch normlization)正则化,但是这样虽然解决了梯度的问题,深度加深了,却带来了另外的问题,就是网络性能的退化问题,深度加深了,错误率却上升了,而残差用来设计解决退化问题,其同时也解决了梯度问题,更使得网络的性能也提升了。
普通网络(Plain network),类似VGG,没有残差,凭经验会发现随着网络深度的加深,训练错误会先减少,然后增多(并证明的错误的增加并不是由于过拟合产生,而是由于网络变深导致难以训练)。从理论上分析,网络深度越深越好。但实际上,如果没有残差网络,对于一个普通网络来说,深度越深意味着用优化算法越难训练。实际上,随着网络深度的增加,训练误差会越来越多,这被描述为网络退化。
(ResNets的提出,可以解决上述问题,即使网络再深吗,训练的表现仍表现很好。它有助于解决梯度消失和梯度爆炸问题,让我们在训练更深网络的同时,又能保证良好的信息。)
残差结构示意图
残差网络的设计思想
残差元的主要设计有两个,快捷连接和恒等映射。
快捷连接使得残差变得可能,而恒等映射使得网络变深,
恒等映射主要有两个:跳跃连接和激活函数。
34层的深度残差结构

除了上面提到的两层残差学习单元,还有三层的残差学习单元,如下图所示:
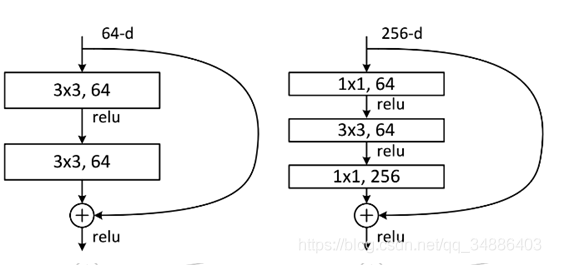
两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),其目的主要就是为了降低参数的数目。左图是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,右图是第一个1x1的卷积把256维通道降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,右图的参数数量比左图减少了16.94倍,因此,右图的主要目的就是为了减少参数量,从而减少计算量。