1.学习大数据集
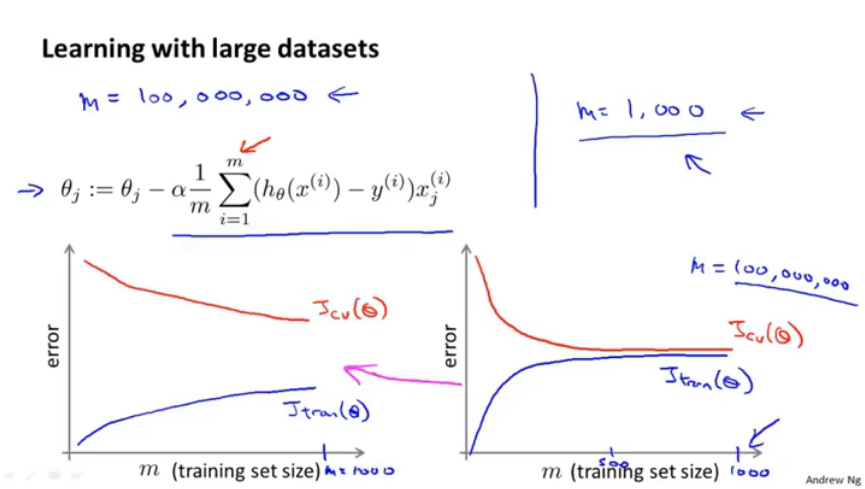
图1.学习大数据集
当数据集量为m=1亿时,进行梯度下降将会花费较大时间。
可以使用小量数据集进行训练,然后得出学习曲线。
左图是高方差,右图是高偏差。
总之是要通过高效的学习算法来进行大数据学习。
2.随机梯度下降
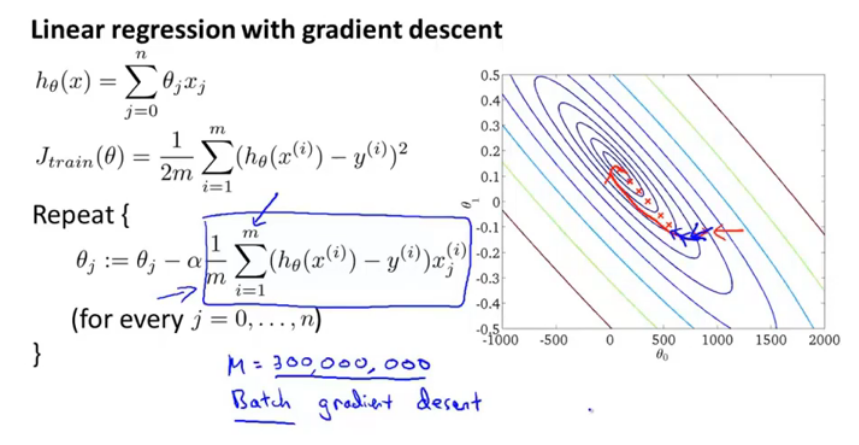
图2.批梯度下降
假设是美国人口普查的数据,m=3亿,如果需要每次读入,并且计算(for every j=0,....n),对每一个参数θ都有这么一个计算,就非常复杂了。

图3.批与随机梯度下降
批梯度下降中,θ_j的更新是代价函数J(θ)对θ_j的偏导数。
随机梯度下降中,将平方项单独作为一个cost函数,对样本1~m遍历,每个样本都更新θ_j,此处的梯度更新是对cost函数来说,不用求和。
那么重要的就是对训练样本需要进行随机化,这样可以加快收敛速度。
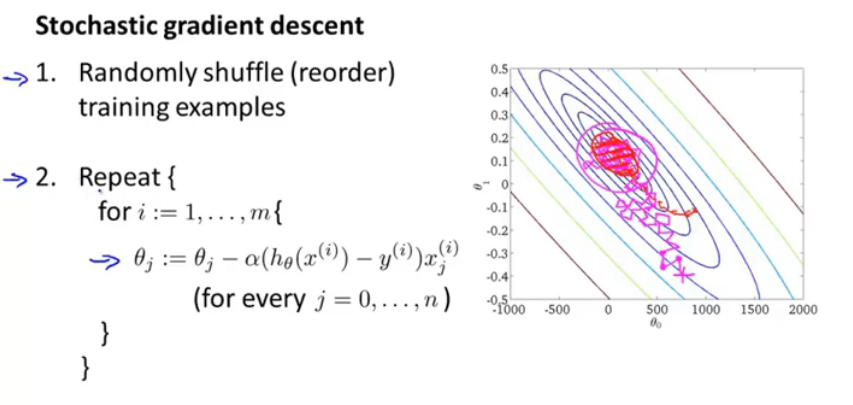
图4.随机梯度下降
随机梯度下降中,首先需要随机化初始数据;
由于没有求和项,回避批梯度下降快很多。
图中红线表示批梯度下降,洋红线表示随机梯度下降,中间可能方向会发生偏差,但最终会落到一个范围内。
那么最终的内层循环for多少次呢? 平常1~10次就很合理了(取决于数据及大小)。
那么对于数据集人口普查3亿数据来说,1-3亿,只遍历一次数据集即可得到最优结果。
3.Mini-Batch梯度下降

图5.三种梯度下降对比
批梯度下降:每次迭代都使用全部m个样本;
随机梯度下降:每次迭代使用1个样本;
Mini-batch梯度下降:每次迭代使用b个样本。
即每次迭代对b各样本求和,它的运行速度是在批梯度下降和随机梯度下降之间的。

图6.Mini-Batch梯度下降
假设b=10,m=1000,那么MB梯度下降即每次使用10个数据进行一次更新;
相较于批梯度下降,它不需要一个循环遍历所有的,只需要遍历b个即可。
如果对更新式找到合适的向量化方法及参数b就可以实现并行计算,将比随机梯度下降更快。
4.随机梯度下降收敛

图7.检查收敛
对批量梯度下降检测收敛,通常是画出J(θ)曲线,横轴时迭代次数。
对随机梯度下降,在进行更新θ之前计算出cost值,可以对每1000次迭代(对1000条样本)得出一个cost均值,并且以此曲线。

图8.cost曲线出现情况分析
1.蓝色曲线表示cost随迭代次数增加缓慢下降,有波动地下降,红色曲线最终下降平衡点较蓝线小,可能原因是学习率更小。
2.蓝线表示每遍历1000个数据求cost均值得出的曲线,波动较大,红色曲线表示增大每次取点的数据量。
3.当波动较大,且cost不下降时,则需要调整算法,调整特征或者学习率。
4.当cost程上升趋势时,很可能是学习率过大,需要使用较小的α。
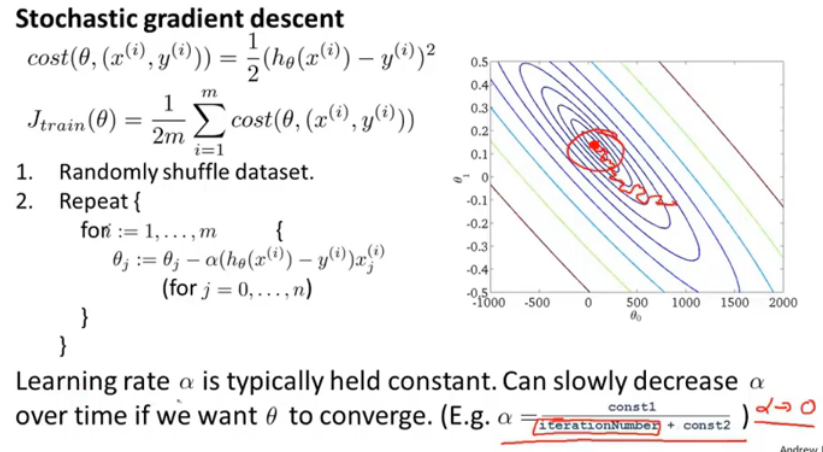
图9.随机梯度下降
对于学习率α的选择,通常是将其设置为一个固定的常数。
但有时,如果想让θ收敛,那么可以随着迭代次数增加减小α,这样在接近最优值时,波动会变小。
但是公式中的两个常数的选择需要花费时间,所以通常是将其设置为常数。
5.在线学习

图10.在线学习
现在有一个网站,需要根据用户的起点终点给出运费报价,并根据用户是否最终选择了本网站作为y;
那么此时x可以有多个特征,比如起点、终点、运费等,想要学习最优的参数θ。
算法的运算过程是,获取到用户的(x,y),并且使用它更新θ。
此处更新式中,并没有y(i)这样的上标,也就是不是对一个固定的训练集来说的,它是从 网站的角度采取数据,是开放的。
这样能更好的捕获用户的偏好。

图11.产品搜索例子
比如用户搜索关键词,安卓手机 1080像素 这样的关键词,假设有100部手机,将会返回10部手机作为结果;
那么可以将x设置为[与用户搜索匹配的特征数,产品描述符合词数,,,,]这样作为特征向量,那么如果用户点击了就是y=1,否则y=0,目标是要学习y=1的情况下,θ最优。
那么每次用户搜索都会产生10个样本,进行在线学习。
重点就是,不会有一个固定的训练集, 而是去获取用户样本,从用户样本中学习,然后丢弃使用下一个。
6.减少映射与数据并行

图12.减少映射进行并行计算
比如对一个数据集进行梯度下降的时候,很有可能数据量很大,在一个机器上计算的速度比较慢;
那么可以将数据放到不同的机器上,进行并行计算,提高运算速度,最终将计算结果进行合并发送给中心服务器。
也适用于同一台机器上的多核并行运算。