参考:
https://zhuanlan.zhihu.com/p/27938792
做法
设,每个batch输入是 (其中每个
都是一个样本,
是batch size) 假如在第一层后加入Batch normalization layer后,
的计算就倍替换为下图所示的那样。
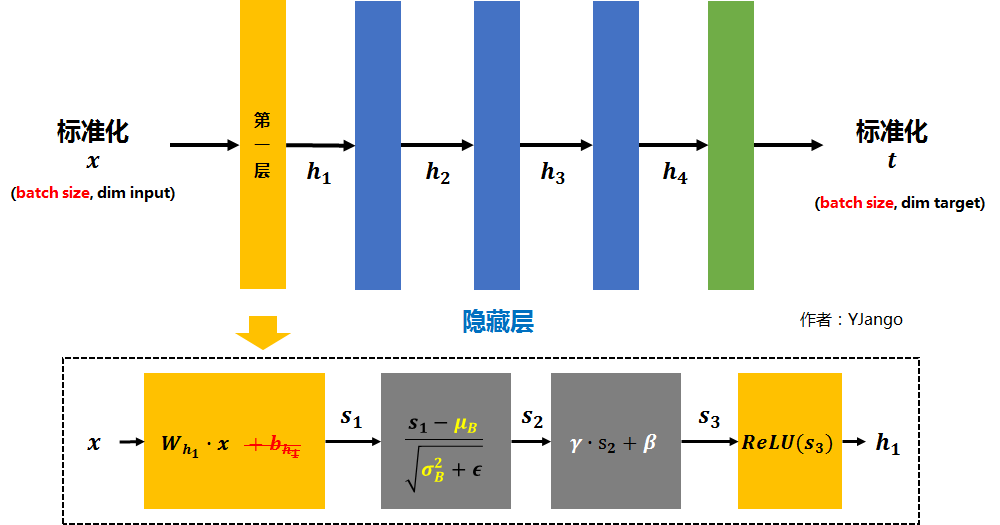
- 矩阵
先经过
的线性变换后得到
- 注:因为减去batch的平均值
后,
的作用会被抵消掉,所以没必要加入
- 将
再减去batch的平均值
得到
。
是为了避免除数为0的情况所使用的微小正数。
- 注:但
和
。
- 将
。
- 为加入非线性能力,
- 最终得到的
会被送到下一层作为输入。
需要注意的是,上述的计算方法用于在训练。因为测试时常会只预测一个新样本,也就是说batch size为1。若还用相同的方法计算 ,
就会是这个新样本自身,
就会成为0。
所以在测试时,所使用的 和
是整个训练集的均值
和方差
。
而整个训练集的均值和方差
的值通常也是在训练的同时用移动平均法来计算