
反卷积、上采样、上池化图示理解,如上所示。
目前使用得最多的deconvolution有2种。
方法1:full卷积, 完整的卷积可以使得原来的定义域变大
上图中蓝色为原图像,白色为对应卷积所增加的padding,通常全部为0,绿色是卷积后图片。卷积的滑动是从卷积核右下角与图片左上角重叠开始进行卷积,滑动步长为1,卷积核的中心元素对应卷积后图像的像素点。可以看到卷积后的图像是4X4,比原图2X2大了,我们还记1维卷积大小是n1+n2-1,这里原图是2X2,卷积核3X3,卷积后结果是4X4,与一维完全对应起来了。其实这才是完整的卷积计算,其他比它小的卷积结果都是省去了部分像素的卷积。
方法2:记录pooling index,然后扩大空间,再用卷积填充

假设原图是3X3,首先使用上采样让图像变成7X7,可以看到图像多了很多空白的像素点。使用一个3X3的卷积核对图像进行滑动步长为1的valid卷积,得到一个5X5的图像,我们知道的是使用上采样扩大图片,使用反卷积填充图像内容,使得图像内容变得丰富,这也是CNN输出end to end结果的一种方法
图像的deconvolution过程如下,
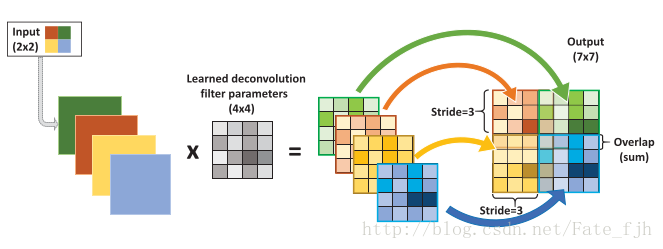
输入:2x2, 卷积核:4x4, 滑动步长:3, 输出:7x7
即输入为2x2的图片经过4x4的卷积核进行步长为3的反卷积的过程
1.输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为 1+4-1=4, 即4x4大小的特征图,输入有4个像素所以4个4x4的特征图
2.将4个特征图进行步长为3的fusion(即相加); 例如红色的特征图仍然是在原来输入位置(左上角),绿色还是在原来的位置(右上角),步长为3是指每隔3个像素进行fusion,重叠部分进行相加,即输出的第1行第4列是由红色特阵图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
可以看出反卷积的大小是由卷积核大小与滑动步长决定, in是输入大小, k是卷积核大小, s是滑动步长, out是输出大小
得到 out = (in - 1) * s + k
上图过程就是, (2 - 1) * 3 + 4 = 7
转自:
https://blog.csdn.net/A_a_ron/article/details/79181108
https://blog.csdn.net/qq_38906523/article/details/80520950