Oracle数据库基础入门《二》Oracle内存结构
Oracle 的内存由系统全局区(System Global Area,简称 SGA)和程序全局区(Program Global Area,简称 PGA)组成。
(一)、系统全局区SGA
系统全局区(system global area,SGA)是一组包含了 Oracle 数据库数据及实例控制信息的共享的内存结构。当多个用户并发地连接到同一个实例后,这些用户将共享此实例SGA 中的数据。因此 SGA 也被称为共享全局区(shared global area)。
SGA 越大系统的性能越好,但 SGA 过大也会起到反作用。一般情况下,SGA 不应超过系统实际内存的 1/2。但从 Oracle 9i 开始支持动态 SGA 特性,即无需关闭实例就可以改变数据高速缓冲区、共享池和大池的大小。数据高速缓冲区、共享池的大小也可以根据工作负载自动调整,但 SGA 的总大小不能超过初始化参数 SGA_MAX_SIZE 的设置。
1.SGA 的构成
如图 2-1 所示,SGA 包括三个子缓冲区:保留缓冲区、循环缓冲区和非标准大小块缓冲区。SGA 包括以下结构:
● 数据高速缓冲区(Data Buffer Cache)
● 重做日志缓冲区(Redo Log Buffer)
● 共享池(Shared Pool)
● Java 池(Java Pool)
● 大池(Large Pool)
● 流池(Stream Pool)

>>> 1.1 数据库高速缓冲区(Database Buffer Cache)
在 Oracle 中无论是读取还是修改数据,都是由服务器进程在数据库高速缓冲区中完成的。数据库高速缓冲区的作用就是用来缓存最近从数据库中读出的数据块,并可供其他客户
进程共享。用户进程查看数据时,首先检查需要的信息是否在缓冲区内,如果在缓冲区中,就可以直接访问,否则访问物理文件并读取数据块到数据库缓冲区。我们知道内存的读写速
度要比物理设备的读写速度快很多,这样就可以大大提高 Oracle 数据库的性能。
>>> 数据库高速缓冲区的子缓冲区
根据缓冲数据块的状态,Oracle 将数据高速缓冲区可划分成:
脏缓冲区(Dirty Buffer):
当数据库发生 DML(Insert、Update、Delete)操作时,会对缓冲区内容进行修改,这样缓冲区的内容就会和相对应的数据文件不一致,这时,缓冲区标识为“脏缓冲区”。
自由缓冲区(Free Buffer):
当“脏缓冲区”的内容被写入数据文件后,因为该缓冲区与相应数据文件部分内容一致,所以将这些缓冲区称为“自由缓冲区”。
当执行 SELECT 语句时,会将对应数据文件部分数据读取到数据高速缓存的相应缓冲区,因为缓冲区与数据块内容完全一致,所以这些缓冲区也被称为“自由缓冲区”。
忙缓冲区(Pinned Buffer):
“忙缓冲区”是指服务器进程正在访问的缓冲区。
每个数据库的数据库高速缓冲区大小有限,所以一般不会把磁盘上的所有数据都可以存放在缓冲区中.
为了防止数据库高速缓冲区空间不够用,Oracle 会将脏缓冲区中的数据写入对应的数据文件中,以腾出空间给新的数据。
如果缓冲区不脏,即为“自由缓冲区”,它可以直接被读入新的数据块。)随后访问被写入磁盘导致额外的高速缓存未命中的数据。
“脏列表”的作用就是记录脏缓冲区的情况。如果某些缓冲区中的数据块被修改,就会加入该列表,只有脏列表中的缓冲区数据块需要写回数据库文件,一旦写回数据库文件,缓
冲区就会从脏列表中清除。
>>> 非标准块大小支持
数据库块是 Oracle 数据库 I/O 的最小单位。
每个数据库都可以通过参数 DB_BLOCK_SIZE 指定标准块大小(2k、4k、8k、16k、32k),默认为 8k。但是 Oracle 数据库同时支持多种块大小,我们称这些标准块以外的块为
“非标准大小块”。
非标准大小块的高速缓冲区大小指定以下参数(DB_nK_CACHE_SIZE):
DB_2K_CACHE_SIZE
DB_4K_CACHE_SIZE
DB_8K_CACHE_SIZE
DB_16K_CACHE_SIZE
DB_32K_CACHE_SIZE
DB_nK_CACHE_SIZE 参数不能用于设定标准大小块的高速缓存,标准大小块的缓存尺寸由参数 DB_CACHE_SIZE 的值决定。
>>> 使用多个缓冲区
数据库管理员(DBA )可以通过创建多个缓冲池来提高数据库缓冲区高速缓存的性能。
用户可以指定方案对象(schema object)(表,簇,索引,及分区)使用相应的缓冲池,以便控制数据被移出缓存区的时机。
>> 保留缓冲区(Keep Buffer Cache):用来保留在内存中最有可能重用的对象。保留这些对象将减少 I/O 操作,指定 DB_KEEP_CACHE_SIZE 参数的值配置。
>> 循环缓冲区(Recycle Buffer Cache):用来保留被重用机会不大的内存块。指定 DB_RECYCLE_CACHE_SIZE 参数的值配置该缓冲区的大小。
>> 默认缓冲区(Default Buffer Cache):此池始终存在。它相当于一个实例的数据库高速缓冲区中保留和循环区以外的部分。指定参数 DB_CACHE_SIZE。
注:保留缓冲区和循环缓冲区并非默认缓冲区的子集。可以使用 BUFFER_POOL 子句对对象定义默认的缓冲区。
EXAMPLE:
CREATE INDEX cust_idx …
STORAGE (BUFFER_POOL KEEP);
ALTER TABLE oe.customers
STORAGE (BUFFER_POOL RECYCLE);
>>> 数据库高速缓冲区空间管理
Oracle 用 LRU(Least Recently Used)算法来管理数据高速缓冲区。该算法将最近使用的数据块按照使用时间的早晚排成队列,当缓冲区占满后,调入新的数据块时,必须清除
已有的数据块,来获得空闲数据块空间,那么,最合理的选择就是清除最早没有使用数据块,因为使用该块的概率相对比较小。通过规划 SGA 时合理地设置数据高速缓存的尺寸,尽量
的避免缓冲区占满的情况发生,否则就会降低系统的效率。
Oracle 将队列分成两端,分别为热端和冷端。

假设新数据块 K 将要被读入,又没有空闲位置,则 Oracle 会对冷端头 J 块进行判断:
假设 J 被访问次数为 1,Oracle 将会认为 J 不是一个经常被访问的块(冷),则会将 J块踢出队列,将 K 插入至 F 的位置,F 和其他块右移:

假设新数据块 L 将要被读入,又没有空闲位置,则 Oracle 会对冷端头 I 块进行判断:
假设 I 被访问次数为 5,Oracle 将会认为 I 是一个经常被访问的块(热),则会将 I 块放入热端头,A 和其他快右移如下图所示:

这时,将对下一个冷端头块 H 进行判断:
假设 H 被访问次数为 1,Oracle 将会认为 H 不是一个经常被访问的块(冷),则会将 H块踢出队列,将 L 插入至 E 的位置,E 和其他块右移:

但是这时,我们会发现。I 块被放入热端头,经过漫长的时间,I 块最终会被放到冷端头进行判断;如果这段时间中,即使 I 没有再被访问过,I 的访问次数也仍然是 5,这样 I
将再次回到热端头,这样就造成了死循环,I 永远无法被踢出列表。
因此,当 I 被放到热端头的时候,访问次数将会被清零。如果这段时间 I 被访问多次,则有机会回到热端头,否则,可能被踢出列表。
>>> 数据库高速缓冲区的大小管理
>> 连接数据库
[oracle@oracle ~ ]$ sqlplus / as sysdba
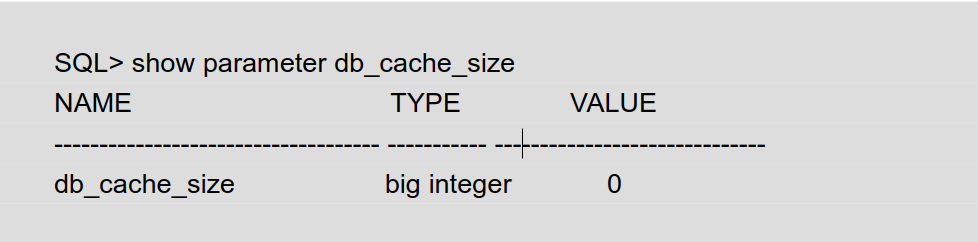
>> 显示数据库高速缓冲区的大小
SQL> show parameter db_cache_size
>> 显示保留缓冲区的大小
SQL> show parameter db_keep_cache_size

>> 显示循环缓冲区的大小
SQL> show parameter db_recycle_cache_size
>> 修改数据库高速缓冲区的大小
SQL> ALTER SYSTEM SET db_cache_size=500m;
>> 清空数据库高速缓冲区
SQL> ALTER SYSTEM FLUSH buffer_cache;

>>> 1.2 重做日志缓冲区(Redo Log Buffer)
当运行 Oracle 服务器的时候,如果突然断电或系统瘫痪,会不会造成数据的丢失?Oracle 提供了一套复杂的机制来维护数据完整性,并最终确保数据不会丢失。这就是重做日志文件的作用。
重做日志缓冲区用来记录对数据缓冲区数据进行的修改,可以循环使用。当用户运行DML(INSERT、UPDATE、DELETE)以及 DDL(CREATE、ALTER、DROP)语句时,会改变数据高速缓存中
的相应缓冲区。但是在修改这些缓冲区之前,Oracle 会自动生成重做项,首先要将这些缓冲区的变化记载到“重做日志缓冲区”中。重做日志缓冲区由一条一条的重做项构成,每条重做项记载了修改
的时间、被修改的块、修改位置以及新数据。缓冲区被循环使用,当重做日志缓冲区填满时,数据库系统将重做日志缓冲区的内容写入日志文件。在系统发生故障时,可以通过重做项重新执行对
数据库的修改,实现对实例的恢复。
重做日志缓冲区的大小由 LOG_BUFFER 初始化参数来决定。
>>> 1.3 共享池(Shared Pool)
SGA 的共享池(Shared Pool)内包含了库缓存(Library Cache),数据字典缓冲区(Dictionary Cache),并行执行消息缓冲区(Buffers for parallel execution messages),
以及用于系统控制的各种内存结构。
共享存储区的大小由 SHARED_POOL_SIZE 初始化参数来决定。同数据高速缓冲区一样,它的大小可以动态的修改。
如图 1-5 所示,共享池由库高速缓存和数据字典缓冲区组成。

>>> 数据字典缓冲区
数据字典是一系列保存了数据库参考信息(例如数据库结构,数据库用户等)的表和视图。Oracle 需要频繁地使用经过解析的 SQL 语句访问数据字典。数据字典信息对 Oracle
能否正常运行至关重要。
数据字典是用来描述数据库数据的组织方式的,由表和视图组成。
数据字典由脚本$oracle_home/rdbms/admin/catalog.sql 创建。
视图有三种实例:user_*(当前用户所拥有对象的有关信息),all_*(当前用户可访问对象的信息),dba_*(数据库中所有对象的信息)。
在 Oracle 数据库中,数据库的一些信息,包括账户、数据文件、表的描述、用户权限等信息,存储在数据字典表中,数据字典表被存放在 SYSTEM 表空间的数据文件中。
因为执行任何 SQL 语句都需要访问数据字典,所以为了提高数据字典的访问性能,Oracle 在共享池中专门为存放数据字典信息分配了内存空间,这些内存空间被称为数据字
典高速缓冲区。用来缓存来自于数据字典的定义。
例如,当用户执行"SELECT * FROM emp WHERE empno=7788"语句时,Oracle 需要查询数据字典 dba_tables 确定表 emp 是否存在;如果该表已经存在,还需要查询数据字典
dba_tab_columns 确定列 empno 在表 emp 中是否存在,然后才能生成执行语句的过程(执行计划)。这些定义在首次查询时存入数据字典高速缓冲区,在后续过程中用到就可以直接
使用,而不必重新查询数据字典。
>>> 库高速缓存
库高速缓冲区又可分为共享 SQL 区和共享 PL/SQL 区。
共享 SQL 区用来存放最近执行的 SQL 语句信息,包括语句文本、解析树及执行计划。执行计划就是 Oracle 为执行特定的 SQL 语句,产生的优化的执行步骤。
库高速缓冲区由许多上下文区(Context Area)组成,SQL 语句和执行计划存放在相应上下文区中,并且不同 SQL 语句分别对应于不同的上下文区。当客户端运行 SQL 语句时,服
务器进程首先检查是否存在对应于该 SQL 语句的上下文区,若存在,则按照其执行计划直接执行该 SQL 语句;否则生成 SQL 语句执行计划,并将执行计划、SQL 语句存放到相应
上下文区中,然后执行该 SQL 语句。
在开发应用程序时,必须要注意使用标准格式来编写 SQL 语句,使得 SQL 语句尽可能共享上下文区,以降低 SQL 语句解析次数,进而提高应用性能。
在解析 SQL 语句时,认为完全相同的 SQL 语句有以下特点:
● 语句文本相同。
● 大小写相同。
● 赋值变量相同。
共享 PL/SQL 区用来存放最近执行的PL/SQL 语句,解析和编译过的程序单元和过程(函数、包和触发器)也存放在此区域。
类似于数据高速缓冲区,Oracle 也是使用 LRU 算法来管理库高速缓存的。通过库高速缓存,可以最小化 SQL 语句解析次数,进而提高应用程序的性能。
>>> 1.3 大池(Large Pool)
数据库管理员可以配置一个称为大型池(Large Pool)的可选内存区域,供一次性大量的内存分配使用,例如:
● 共享服务器(shared server)及 Oracle XA 接口(当一个事务与多个数据库交互时使用的接口)使用的会话内存(session memory)
● I/O 服务进程
● Oracle 备份与恢复操作
如果从大型池内为共享服务器,Oracle XA,或并行查询缓冲区(parallel query buffer)分配会话内存,共享池(shared pool)就能够专注于为共享 SQL 区(shared SQL area)提供内存,
从而避免了共享池可用空间减小而带来的系统性能开销。
此外,Oracle 备份与恢复操作,I/O 服务进程,及并行执行缓存所需的存储空间通常为数百 KB。与共享池相比,大型池能够更好地满足此类大量内存分配的要求。
注:大型池不使用 LRU 列表管理其中内存的分配与回收。
>>> 1.4 JAVA 池(Java Pool)和流池(Stream Pool)
SGA 内的 Java 池(Java Pool)是供各会话内运行的 Java 代码及 JVM 内的数据使用的。Java 池是 SGA 的可选区域,用来为 Java 命令解析提供内存。只有在安装和使用 JAVA时才需要 JAVA 池。
Java 池的大小由 JAVA_POOL_SIZE 初始化参数来决定。
在数据库中,管理员可以在 SGA 内配置一个被称为数据流池(Streams Pool)的内存池供 Oracle 数据流(Stream)分配内存。管理员需要使用 STREAMS_POOL_SIZE 初始化参数设定
数据流池的容量(单位为字节)。如果 Oracle 数据流第一次使用时系统中没有定义数据流池,Oracle 将自动地创建一个。
>>> 查询 SGA 的大小
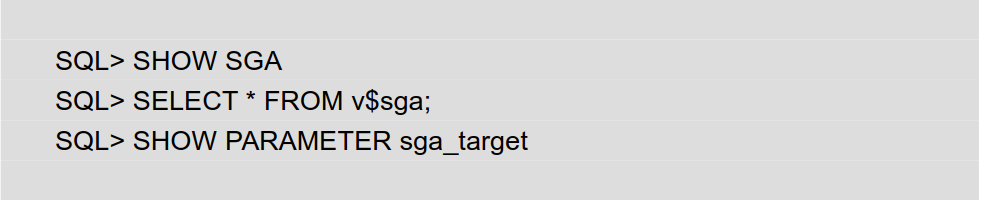
>> 显示 SGA 大小
SQL> SHOW SGA
SQL> SELECT * FROM v$sga;
SQL> SHOW PARAMETER sga_target
>> 显示 SGA 最大值
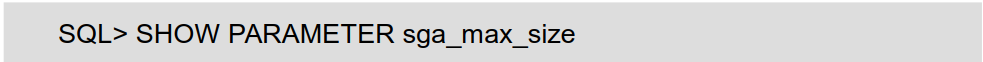
如有问题,欢迎纠正!!!
如有转载,请标明源处: