定义
- warm_up是针对学习率优化的一种策略
- 在warm_up期间,学习率从0开始,线性增加到优化器中初始预设的学习率,随后将学习率从优化器的初始预设学习率(线性\非线性)降低到0.
为什么使用warm up
- 有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳
- 刚开始训练时,模型的权重是随机初始化得到的,若选择一个较大的学习率,可能会使模型不稳定(振荡),选择warm up的方式,使得模型在最初的epoch或step内学习率较小,模型慢慢趋于稳定。模型相对稳定后再选择预先设置的学习率进行训练,使模型收敛速度更快,模型效果更佳。
- 有助于保持模型深层的稳定性
代码
transformers.get_linear_schedule_with_warmup:learning rate 线性增加和线性衰减
参数
optimizer: 优化器
num_warmup_steps: 初始warm up步数
num_training_steps: 整个训练过程总步数
- 当
num_warmup_steps=0时,learning rate没有warm up的过程,只有从初始设定的learning rate衰减到0的过程
不同类型的warm up策略
非线性衰减:
def _get_scheduler(self, optimizer, scheduler: str, warmup_steps: int, t_total: int):
"""
Returns the correct learning rate scheduler
"""
scheduler = scheduler.lower()
if scheduler == 'constantlr':
return transformers.get_constant_schedule(optimizer)
elif scheduler == 'warmupconstant':
return transformers.get_constant_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps)
elif scheduler == 'warmuplinear':
return transformers.get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
elif scheduler == 'warmupcosine':
return transformers.get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
elif scheduler == 'warmupcosinewithhardrestarts':
return transformers.get_cosine_with_hard_restarts_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=t_total)
else:
raise ValueError("Unknown scheduler {}".format(scheduler))
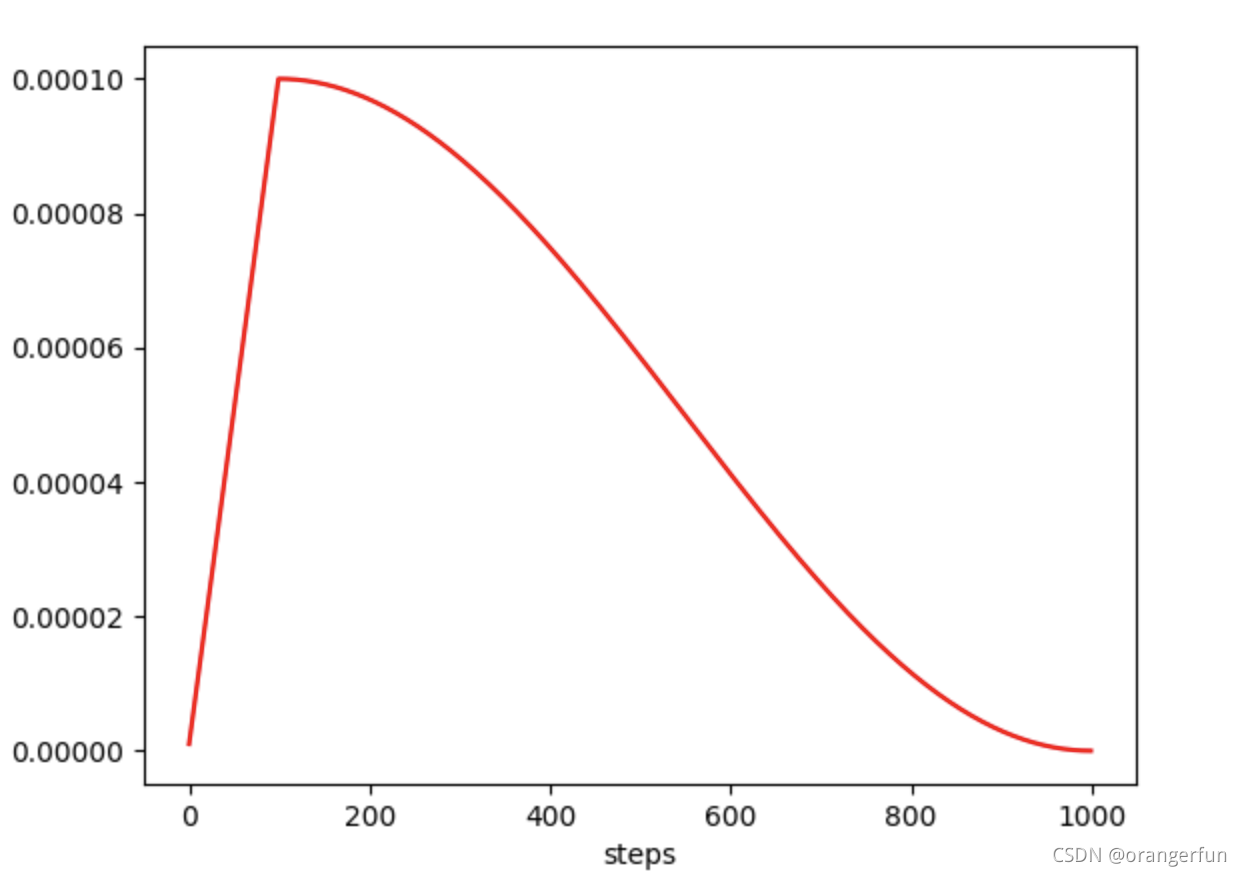
- warmupcosine:
Example:
import torch
import torch.nn as nn
from torch.optim.lr_scheduler import LambdaLR
class model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3)
def forward(self, x):
pass
# 实例化
net_1 = model()
len_dataset = 3821 # 可以根据pytorch中的len(Dataset)计算
epoch = 30
batch_size = 32
# 每一个epoch中有多少个step可以根据len(DataLoader)计算:total_steps = len(DataLoader) * epoch
# total_steps: 3600 i.e., warm up 到衰减的全过程step=3600
total_steps = (len_dataset // batch_size) * epoch if len_dataset % batch_size == 0 else (len_dataset // batch_size + 1) * epoch
# 定义要预热的step
warm_up_ratio = 0.1
# 定义初始学习率,线性增加至0.1后衰减至0
initial_lr = 0.1
# 实例化一个Adam优化器
optimizer_1 = AdamW(net_1.parameters(), lr=initial_lr)
# 实例化LambdaLR对象,lr_lambda是更新函数
scheduler_1 = get_linear_schedule_with_warmup(optimizer_1, num_warmup_steps = warm_up_ratio * total_steps, num_training_steps = total_steps)
# 初始lr。optimizer_1.defaults保存了初始参数
# print("初始化的学习率:", optimizer_1.defaults['lr'])
lr_list = []
for epoch in range(1, 4001):
# train
optimizer_1.zero_grad()
optimizer_1.step()
# 由于只给optimizer传了一个网络,所以optimizer_1.param_groups长度为1
# print("第%d个epoch的学习率:%f" % (epoch, optimizer_1.param_groups[0]['lr']))
lr_list.append(optimizer_1.param_groups[0]['lr'])
# 更新学习率
scheduler_1.step()
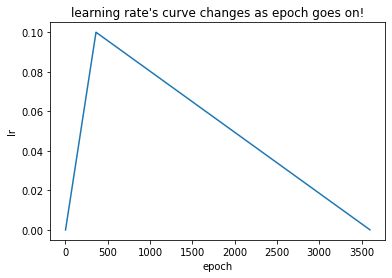
# 画出lr的变化
plt.plot(list(range(1, 4001)), lr_list)
plt.xlabel("epoch")
plt.ylabel("lr")
plt.title("learning rate's curve changes as epoch goes on!")
plt.show()
参考:
https://www.cnblogs.com/xiximayou/p/14836577.html
https://blog.csdn.net/orangerfun/article/details/120400247