本文写于 Amass v3.11.2,可能后续有过更多变更,但是应该整体逻辑不会有十分大的变动了
发展
首先铺垫下在 Amass 用到的两大设计模式:
- 发布订阅模式
- 流水线(pipeline)模式
在 4432dbd 该提交之前,即 v3.11.0 版本前,其实并没有流水线模式,并且采用的是 Golang 来写插件,在此之后,项目负责人 Jeff Foley 对该项目进行了一次大的重构,把他自己写的 eventbus 和 service 全部抽离了出来成为了独立的库,并且引入了他自己实现的 pipeline 库来实现整个子域名收集的流水线作业。同时,原本采用 Golang 编写的数据源插件,通过引入第三方库 gopher-lua 赋予了脚本编写插件的能力,实现了插件系统与主程序的剥离。
改版前
我这里把项目区分为 v3.11.0 前和后
在 v3.11.0 之前,整个项目运行,从入口函数进入后,经过简单处理后,开始经过所有的数据源服务插件,其中所有的数据源服务插件都需要实现 services.Service 接口,通过覆写结构体方法来进行调用。
经过所有的数据源服务插件前,有一个步骤是注册所有的消息订阅者,然后数据源服务插件发现新的子域后,发布消息到事件总线(或者说消息队列)中,然后消息订阅者获取到数据后进行后续处理,比如输出日志,入库,判断是否为泛解析,ip解析等等
其中的发布订阅模式是一个简易的消息队列实现,这里面有几个概念:
- 消息发布
- 消息订阅处理
- 消息频道(路由/topic)
首先需要把消息订阅者(处理函数)注册到系统中,采用的是 hash 表,即 golang 中的 map,不同的topic定义为不同的键,处理函数设置为值,然后发布者发布消息到对应的路由,封装好对应的路由和数据后塞进队列,另外有协程一直在从队列中取出元素,根据所得到的路由和数据参数调用不同的处理函数。
总体是一个树状发散的,即有可能处理的数据会继续发布到总线给其他的处理函数处理。
这样会导致两个问题:
- 因为发布消息的结束标识无法获知,订阅消息的结束标识也是无法获知,整体的树状发散更导致定义任务结束愈发困难
- 就像上面说的,有些处理函数是有一个处理流程的,比如先给谁处理,再给处理,全部移交到消息总线,再由各自的订阅处理,导致整体的数据流动极为晦涩,如果不通读所有处理函数的源码很难梳理明白处理函数之间的先后关系
针对问题1, Amass 采用的解决方案是使用一个协程来监控dns请求的速率,假如多少秒不活跃(即无新数据),并且每秒 dns 请求小于几个,即判断为结束,这个方案只能说是一个相对好用的解决手段,因为架构的问题导致本身就很难以去判断结束
针对问题2,可能开发者想让整个项目的数据流动更清晰一些,所以采用了 pipeline模式,然后使用扇入扇出加快整个处理流程
改版后
设置了一条消息总线,其中定义了两个路由:newname(子域名)和newaddr(ip地址),其他的路由比如日志我们暂时不用关心,这两个路由所对接的是数据源服务插件(包含小部分golang插件,大部分lua插件),通过数据源来产生新子域,发布到总线中,然后这两个路由所注册的订阅处理函数的功能是把数据重定向到 pipeline 的起点,pipeline的数据处理通过预先设置好的几个阶段,每个阶段可以根据个人的需求控制并发数
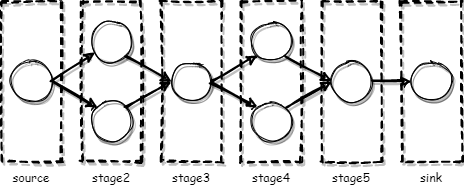
其中总线的所有的新数据会进入source,然后后面的stage都是可以动态扩容的,最后数据经过一个一个阶段的处理,最后到达sink。
通过 pipeline,把整个流程清晰化了起来。
一点猜想
目前还保有 golang 的插件,但是目前看起来 golang 的插件是可以用 lua 去实现的,所以目前来看应该是还没有迁移完毕。
目前所使用的 pipeline 库也是 Amass 项目负责人 Jeff Foley 写的,其中大致上有这么几个功能:
- 入口处理
- 出口处理
- 阶段处理
- 固定协程数量的协程池(单一任务)
- 动态协程数量并可设置上限的协程池(单一任务)
- 单管道(单一任务)
- 广播(多任务,不等待该阶段所有任务完成,有任务完成即进入下一阶段)
- 平行(多任务,等待该阶段所有任务完成再进入下一阶段)
目前来看的话,广播和平行都没有都没有用到,其实比较困惑的一点是,整个流水线模式是可以应对子域名收集的,但是目前还是保留有总线的概念,猜测可能后面会使用广播或平行对数据源的插件进行执行,因为每个插件可以看作一个 Task,恰好是满足他自己的设计的