一 什么是并发编程
并发指的是多个任务同时被执行即并发编程指的是编写代码令我的程序能够同时处理多个任务。
二 进程
进程即正在执行的一个程序。进程是对正在运行的程序的一个抽象。进程的概念起源于操作系统,是操作系统最核心的概念,也是操作系统提供的最古老也是最重要的抽象概念之一。操作系统的其他所有内容都是围绕进程的概念展开的。那么便要来介绍一下操作系统。
pid 和ppid
pid :系统会给每一个进程分配一个进程编号即ID
# 在python中可以使用os模块来获取pid import os print(os.getpid())
ppid : 在python中可以通过os模块来获取父进程的pid
# 在python中可以使用os模块来获取ppid import os print("self",os.getpid()) # 当前进程自己的pid print("parent",os.getppid()) # 当前进程的父进程的pid
操作系统
精简的说的话,操作系统是一个协调、管理和控制计算机硬件资源和软件资源的控制程序。
#操作系统位于计算机硬件与应用软件之间,本质也是一个软件。操作系统由操作系统的内核#(运行于内核态,管理硬件资源)以及系统调用(运行于用户态,为程序员写的应用程序提供#系统调用接口)两部分组成,所以,单纯的说是操作系统是运行于内核态的,是不准确的。
下图是操作系统在整个计算机中所在的位置:
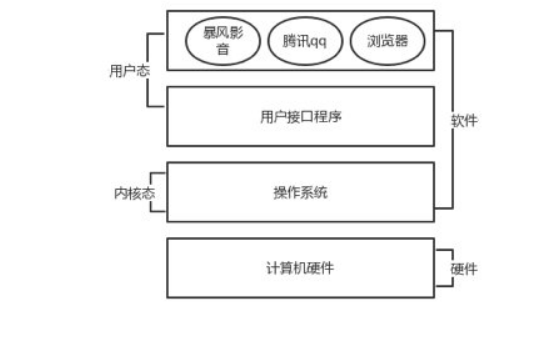
操作系统的两个核心作用:
1.为用户屏蔽了复杂繁琐的硬件接口,为了应用程序提供 了清晰易用的接口,有了这些接口以后程序员不用再直接与硬件打交道了。
#例子:有了操作系统后我们就可以使用资源管理器来操作硬盘上的数据,而不用操心,磁头的#移动啊,数据的读写等等
2.操作系统将应用程序对硬件资源的竞争变成有序的使用
#例子:所有软件 qq啊 微信啊 吃鸡啊都共用一套硬件设备 假设现有三个程序都在使用打印 #机,如果不能妥善管理竞争问题,可能一个程序打印了一半图片后,另一个程序抢到了打印机#执行权于是打印了一半文本,导致两个程序的任务都没能完成,操作系统的任务就是将这些无#序的操作变得有序
操作系统与应用软件的区别:
二者的区别不在于地位,他们都是软件,而操作系统可以看做是一款特殊的软件。
1.操作系统是受保护的,无法被用户修改(应用软件如qq等不属于操作系统,可以被随时卸载)
2.大型:linux或windows源代码都在五百万行以上,这仅仅是内核,不包括用户程序,如GUI、库以及基本应用软件,很容易就能达到这个数量的10倍或者20倍之多。
3.长寿:由于操作系统源码量巨大,编写是非常耗时耗力的,一旦完成,操作系统所有者便不会轻易的放弃重写,二是在原有基础上改进,基本上可以把windows95/98/ME看做一个操作系统。
多道技术
多道技术中的多道指的是多个程序,多道技术的实现是为了解决多个程序竞争或者说共享同一个资源(比如cpu)的有序调度问题,解决方式即多路复用,多路复用分为时间上的复用和空间上的复用。
空间上的复用:将内存分为几个部分,每个部分放入一个程序,这样同一时间内存中就有了多道程序。

时间上的复用:当一个程序在等待I/O操作时,另一个程序可以使用cpu,如果内存中可以同时存放足够多的程序,则cpu的利用率可以接近100%,类似我们小学数学所学的统筹方法。(操作系统采用了多道技术后,可以控制进程的切换,或者说进程之间去争抢cpu的执行权限。这种切换不仅会在一个进程遇到io时进行,一个进程占用cpu时间过长也会切换,或者说被操作系统夺走cpu的执行权限)
空间上的复用的最大问题是:程序之间的内存必须分割,这种分割需要在硬件层面实现,由操作系统控制。如果内存彼此不分割,则一个程序可以访问另外一个程序的内存。这样的话首先丧失的是安全性,比如你的qq程序可以直接访问操作系统的内存,这意味着你的qq可以拿到操作系统的所有权限。其次丧失的稳定性,某个程序奔溃时有可能把别的程序的内存也给回收了,比如说把操作系统的内存给回收了,那么你的操作系统就崩溃了,这样一点也不好玩。
三 并发与并行
1.并发:指的是多个事情同时发生了,是伪并行即看起来是同时运行的,其实是以任务之间切换的形式,给人感觉同时进行。(单个cpu+多道技术可以实现并发,并行也属于并发)


身为良好青年的我,在平常都会有很多的事情要做,比如:学习Python、写博客啊、和小姐姐一起玩耍、影响联盟5杀之类的,但是我同一时刻只能做一个事情(cpu同一时间只能干一个活),那么我如何才能玩多个任务并发执行的效果?
那么我急先学习一会python,然后再写一会博客,再去陪小姐姐玩耍一会、最后再去当会召唤师,这样就保证了每个任务都在进行。
2.并行:指的是多个事情都是进行着的,只有多个cpu才能实现并行,在计算机中单核CPU是无法真正实现并行,之所以单核CPU能同时运行多个程序,其实是并发。例如一个人在写代码另一个人看出,这两件事情是同时进行的,一个人是无法真正的同时进行这两件事情的,只能利用并发来伪并行。
四 阻塞与非阻塞
阻塞状态是因为程序遇到了IO操作,就是sleep,导致后续的代码不能被CPU执行,非阻塞与之相反,表示程序正在正常被CPU执行。
进程有三种状态:就绪态、运行态和阻塞态
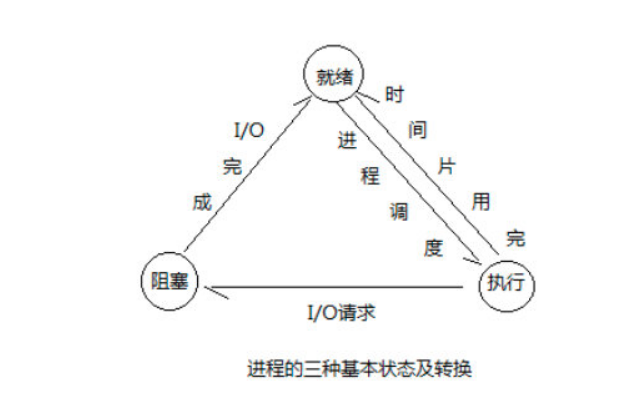
多道技术会在进程执行时间过长或遇到IO自动切换至其他进程,意味着IO操作与进程被剥夺CPU执行权都会造成进程阻塞。
四 Python中实现并发
python中开启子进程的两种方式
from multiprocessing import Process import time def task(name): print('%s is running' %name) time.sleep(3) print('%s is done' %name) if __name__ == '__main__': # 在windows系统之上,开启子进程的操作一定要放到这下面 # Process(target=task,kwargs={'name':'egon'}) p=Process(target=task,args=('jack',)) p.start() # 向操作系统发送请求,操作系统会申请内存空间,然后把父进程的数据拷贝给子进程,作为子进程的初始状态 print('======主')
from multiprocessing import Process import time class MyProcess(Process): def __init__(self,name): super(MyProcess,self).__init__() self.name=name def run(self): print('%s is running' %self.name) time.sleep(3) print('%s is done' %self.name) if __name__ == '__main__': p=MyProcess('jack') p.start() print('主')
from multiprocessing import Process import time a=10000 def task(name): print("%s is run"%name) global a print("子进程中a的内存地址 = ",id(a)) time.sleep(3) print("%s is done"%name) if __name__ == '__main__': p = Process(target=task,args=('小怪兽',)) p.start() print("父进程中a的内存地址 = ",id(a)) >>>: 父进程中a的内存地址 = 2657540746960 小怪兽 is run 子进程中a的内存地址 = 1937943583344 小怪兽 is done
join函数
调用start函数后的操作就由操作系统来玩了,至于何时开启子进程,子进程何时执行,何时结束都与应用程序无关,所以当前进程会继续往下执行。
join函数的作用:使父进程等待子进程结束后才能继续执行下去
from multiprocessing import Process import time def task(num): print("我是%s号进程"%num) time.sleep(2) if __name__ == '__main__': start_time = time.time() ps = [] for i in range(10): p = Process(target=task,args=(i,)) p.start() ps.append(p) for p in ps: p.join() print(time.time()-start_time) 案例二
from multiprocessing import Process import time def task(name): print("%s is run"%name) time.sleep(3) print("%s is done"%name) if __name__ == '__main__': p = Process(target=task,args=('小怪兽',)) p.start() p.join() #父进程停止在此处 print("父进程运行结束")
五 守护进程
主进程创建守护进程
其一:守护进程会在进程代码执行结束后就终止。
其二:守护进程内无法开启子进程,否则会异常抛出,异常信息为:AssertionError: daemonic processes are not allowed to have children。
应用场景:之所以开进程,是为了帮主进程完成某个任务,然而如果主进程认为自己的事情一旦做完,就没必要在执行子进程了即主进程结束时子进程也要结束,此时可以将子进程设置为守护进程。例如:运行qq时,我们开启了一个下载文件的子进程,当我们退出qq时,下载任务也结束了。
from multiprocessing import Process import time def beauty(): print("美人陪伴皇帝") time.sleep(5) #美人正常寿命5秒 print("美人正常死亡") #当皇帝死了后,美人会殉葬,直接死亡,所以无法正常死亡,这一句不会被执行 if __name__ == '__main__': p = Process(target=beauty) p.daemon = True print("皇帝开始了他美滋滋的一生,与美人风流快活") p.start() time.sleep(3) #皇帝活的短一点,谁让他快活呢,他就活3秒 print("皇帝死了,美人陪葬吧")
六 互斥锁
当多个进程共享一个数据时,多个进程竞争一个数据会在成数据的错乱,解决数据错乱的方法有两种。 1.使用join是多个进程串行,但是这将导致无法并发,并且进程执行任务的顺序就固定了。
2.使用锁,将需要共享的数据加锁,是其他进程在访问数据时,就必须等待当前进程执行完毕才能使用数据。
join和锁的区别:
1.join中的顺序是固定的,不公平的
2.join是完全串行,而锁可以使用部分代码串行,其他代码还是并发
#场景:多个人买票,但是票的个数有限,我们将票数存储在json文件中,利用锁还实现抢票的过程 import json from multiprocessing import Process,Lock import time def check_ticket(num): with open("ticket.json",'rt',encoding='utf-8')as f: ticket_count = json.load(f).get("count") print("%s用户查看了票数,剩余%s张票"%(num,ticket_count)) def buy_ticket(num): with open("ticket.json",'rt',encoding='utf-8')as f: ticket_dic = json.load(f) ticket_count = ticket_dic.get("count") if ticket_count >0: time.sleep(2) ticket_count -=1 ticket_dic['count'] = ticket_count with open("ticket.json", 'wt', encoding='utf-8')as f: json.dump(ticket_dic,f) print("%s用户购票成功,剩余票为%s张"%(num,ticket_count)) else: print("%s用户购票失败,已经没有票了"%num) def task(num,lock): check_ticket(num) #查看票数过程是并发的,每个人都可以查询 lock.acquire() buy_ticket(num) #买票是需要抢的,并不是每个人都能买到,因此是串行的 lock.release() if __name__ == '__main__': lock = Lock() for i in range(1,11): p = Process(target=task,args=(i,lock)) p.start() print("春节到了,抢票开始了,冲啊!!!")
#加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。 虽然可以用文件共享数据实现进程间通信,但问题是: 1.效率低(共享数据基于文件,而文件是硬盘上的数据) 2.需要自己加锁处理 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 1 队列和管道都是将数据存放于内存中 2 队列又是基于(管道+锁)实现的,可以让我们从复杂的锁问题中解脱出来, 我们应该尽量避免使用共享数据,尽可能使用消息传递和队列,避免处理复杂的同步和锁问题,而且在进程数目增多时,往往可以获得更好的可获展性。
如果一个进程中需要多把锁,那么可以导入Rlock,创建锁的时候使用Rlock(),但是需要注意的一点是开了几把锁,就要关闭几把锁。
死锁
多个进程,互相等待。
from multiprocessing import Process,Lock import time def task1(l1,l2,i): l1.acquire() print("盘子被%s抢走了" % i) time.sleep(1) l2.acquire() print("筷子被%s抢走了" % i) print("吃饭..") l1.release() l2.release() pass def task2(l1,l2,i): l2.acquire() print("筷子被%s抢走了" % i) l1.acquire() print("盘子被%s抢走了" % i) print("吃饭..") l1.release() l2.release() if __name__ == '__main__': l1 = Lock() l2 = Lock() Process(target=task1,args=(l1,l2,1)).start() Process(target=task2,args=(l1,l2,2)).start()
七IPC(进程间通讯)
由于进程之间内存是相互独立的,所以需要对应的解决方案,能够使进程之间可以相互传递数据,这个方案便是IPC。
进程彼此之间相互隔离,要实现进程间的通信(IPC),multiprocrssing模块支持两种形式:队列和管道,这两种方式都是使用消息传递。另外还有一种利用共享文件的方法,即多个进程同时读写一个文件,上述中的互斥锁模拟春节抢票就是利用文件共享的办法实现进程通讯。
八 队列
队列不只用于进程间的通讯,也是一种常见的数据容器。
特点:先进先出
优点:可以保证数据不错乱。原理为多个进程访问同一个数据时,将数据依次放入队列中,队列中数据满了时,再往队列中加数据会造成阻塞,同样当队列中无数据时,再从队列中取数据也会遭遇阻塞。
''' multiprocessing模块支持进程间通信的两种主要形式:管道和队列 都是基于消息传递实现的,但是队列接口 ''' from multiprocessing import Process,Queue import time q=Queue(3) #put ,get ,put_nowait,get_nowait,full,empty q.put(3) q.put(3) q.put(3) print(q.full()) #满了 print(q.get()) print(q.get()) print(q.get()) print(q.empty()) #空了
九 生产者消费者模型
生成者消费者模式模型是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生成者产生完数据后不等待消费者处理,直接将数据扔到阻塞队列中,消费者也不找生产者要数据,而是直接从阻塞队列中取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
数据爬虫分为数据爬取和数据解析两个步骤,由于爬取数据和解析数据都是很耗时的操作,如果按照正常的顺序来编写代码,将造成数据解析需要等待数据爬取后才能进行数据解析,数据爬取也要等数据解析之后在进行爬取,这样做就会导致程序的效率非常的低。因此如何提高效率,便可以遵循一个原则:让生产者和消费者解开耦合,自己干自己的事情。在这个场景中爬取数据时生产者,数据解析是消费者。 实现步骤: 1.将两个任务分配给不同的进程 2.提供一个进程共享的数据容器。 #============================================ from multiprocessing import Process,Queue import time import random def get_data(q): for i in range(1,6): print("正在爬取第%s条数据..."%i) time.sleep(random.randint(1,2)) #爬取不同数据的时间不同 print("爬取成功!") q.put("第%s条数据"%i) #爬取成功加入到阻塞队列中 def analysis_data(q): for i in range(1,6): data = q.get() print("正在解析%s"%data) time.sleep(random.randint(1,2)) #解析不同的数据所需的时间不同 print("数据解析成功!") if __name__ == '__main__': q = Queue(5) #假设爬取5条数据 p = Process(target=get_data,args=(q,)) p.start() a = Process(target=analysis_data,args=(q,)) a.start()