1. 下载安装:
下载地址:wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-5.0.1-Linux-x86_64.sh --no-check-certificate
(最新版本:wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.11-Linux-x86_64.sh --no-check-certificate)
下载完后,执行Anaconda3-5.0.1-Linux-x86_64.sh脚本就可以安装。
安装提示:
提示一:
Do you accept the license terms? [yes|no]
[no] >>> yes
提示二:
Anaconda3 will now be installed into this location: /home/hadoop//anaconda3 - Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location below
这时候可以自己输入指定的安装目录,比如我输入/home/hadoop/bigdata/anaconda3/
提示三:确认是否自动加安装路径添加到环境变量中,选择yes
Do you wish the installer to prepend the Anaconda3 install location to PATH in your /home/hadoop//.bashrc ? [yes|no] [no] >>> yes
2. 配置jupyter notebook服务
2.1 生成配置文件
cd /home/hadoop/bigdata/anaconda3/bin/
./jupyter notebook --generate-config
2.2 生成密码
./ipython In [1]: from notebook.auth import passwd In [2]: passwd() Enter password: Verify password: Out[2]: 'sha1:297308f26ac6:bc524d2e1afafdbb798456a9161254962968b113' In [3]: quit()
----------------------新版本-----------------------------------
In [1]: from notebook.auth import passwd
In [2]: passwd()
Enter password:
Verify password:
Out[2]: 'argon2:$argon2id$v=19$m=10240,t=10,p=8$qprVWqc29AMaxanqkCjs1g$AQv2lP0mb05cVRUSjIVMZA'
In [3]: quit()
这时候把Out[2] 上显示的密码记录下来。
2.3 修改jupyter_notebook_config.py文件
vim jupyter_notebook_config.py
#c.NotebookApp.password_required=True c.NotebookApp.notebook_dir='/home/hadoop/jupyter_notebook' #c.NotebookApp.allow_root=True c.NotebookApp.ip='*' c.NotebookApp.open_browser=False #c.NotebookApp.password='刚才生成的sha1' c.NotebookApp.port=7070 #此端口为不使用pyspark的端口
3. 配置环境变量
vim /etc/profile
export ANACONDA_HOME=/home/hadoop/bigdata/anaconda3 export PATH=$PATH:$ANACONDA_HOME/bin export PYSPARK_DRIVER_PYTHON=jupyter-notebook export PYSPARK_DRIVER_PYTHON_OPTS="--ip=0.0.0.0 --port=8888"
或者,也可以只在/etc/profile中配置anaconda3的PATH路径如下:
# added by Anaconda3 installer
export PATH=/home/hadoop/bigdata/anaconda3/bin:$PATH
然后在spark的spark-env.sh配置如下
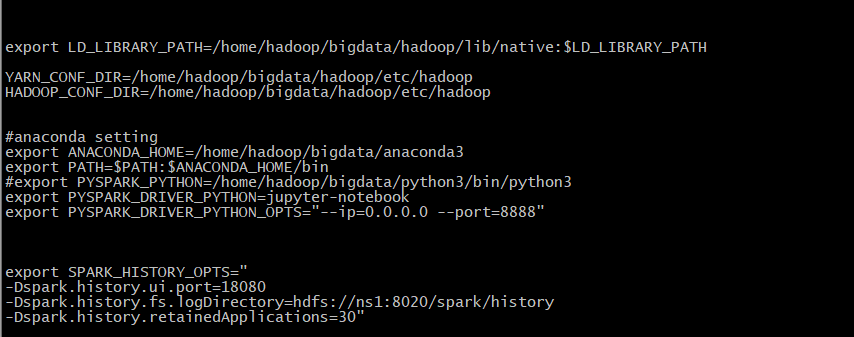
4. 创建虚拟环境,并激活
conda create -n pyspark-env python=3.6
source activate pyspark-env
5. 在虚拟环境中安装依赖包
conda install -n pyspark-env pyarrow=0.9.0 conda install -n pyspark-env numpy=1.16.6 conda install -n pyspark-env mkl=2021.4.0
6.启动
pyspark

7. 在浏览器中输入 ip地址:8888
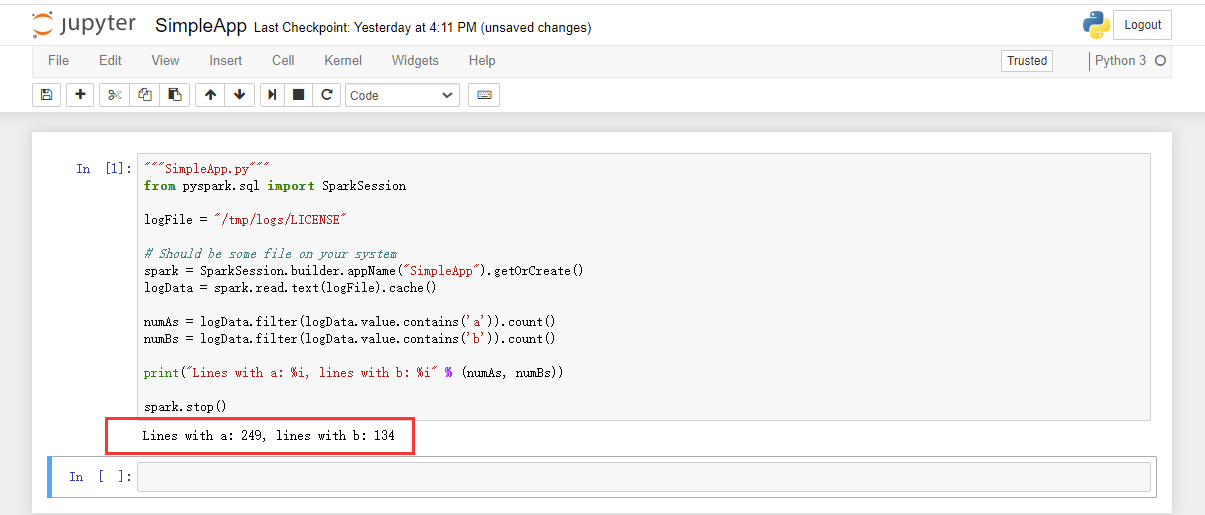
建立文件夹,建立python3测试文件。


"""SimpleApp.py""" from pyspark.sql import SparkSession logFile = "/tmp/logs/LICENSE" # Should be some file on your system spark = SparkSession.builder.appName("SimpleApp").getOrCreate() logData = spark.read.text(logFile).cache() numAs = logData.filter(logData.value.contains('a')).count() numBs = logData.filter(logData.value.contains('b')).count() print("Lines with a: %i, lines with b: %i" % (numAs, numBs)) spark.stop()
上面是测试代码,logFile是存在于hdfs上的文件,自己找个文本文件上传即可。
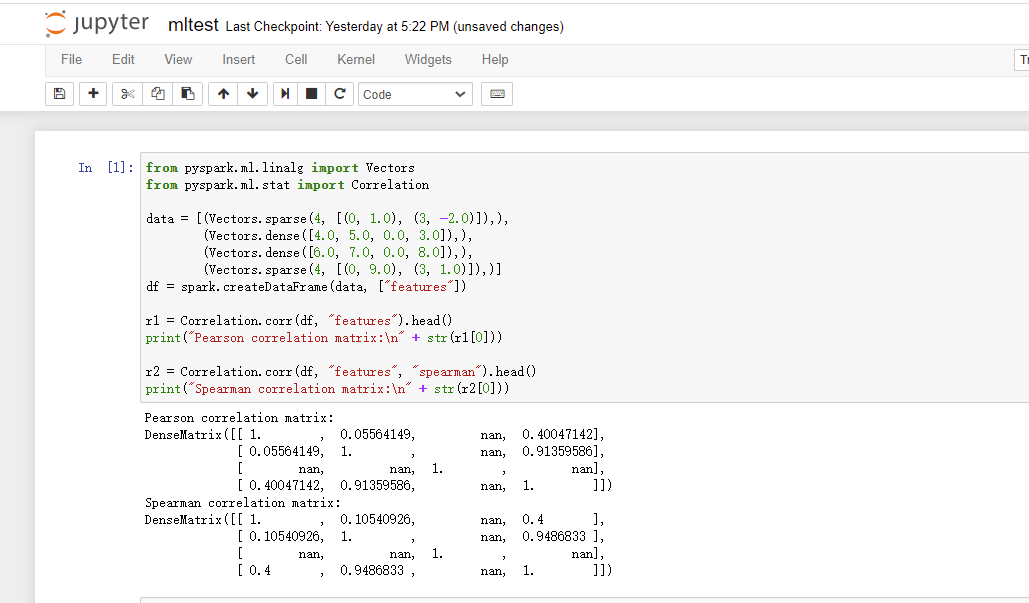
执行机器学习样例
8. 指定jupyter虚拟环境配置
注意:此时在jupyter notebook中运行环境并不是我们指定的虚拟环境,而只是默认的环境。
所以需要参考 https://www.cnblogs.com/30go/p/16028840.html 来完成指定虚拟环境在jupyter中的配置。
9. 通过打包不同环境解决不同的版本问题
使用conda可以解决不同的脚本需要不同版本的python或者其他环境。
通过将环境打包,在执行任务时指定环境包即可。
zip -r -9 -q py36spark.zip py36spark
或者
conda pack -n py36spark
建议使用conda pack,压缩比高,生成的文件较小。
安装conda pack 建议直接用pip install conda-pack
10. 后台启动脚本
新建脚本文件名 start_pyspark_backend.sh,放到spark的目录中/home/hadoop/bigdata/spark。
命令如下:
#!/bin/sh nohup pyspark > ./logs/pyspark.log 2>&1 & echo $! > pyspark.pid
这样执行该脚本,就在后台启动。