2017-2018-2 《密码与安全新技术》第6周作业
课程:《密码与安全新技术》
班级:2017级92班
学号:20179225
上课教师:谢四江
主讲教师:赵绪营
上课日期:2018年5月24日
必修/选修: 必修
主要内容学习
1. 模式识别的概念
1.1 模式识别的定义
模式或者模式类:
可以是研究对象的组成成分或影响因素之间存在的规律性关系,因素之间存在确定性或随机性规律的对象、过程或者事件的集合
识别:
对以前见过的对象的再认识(Re-cognition)
模式识别:
对模式的区分与认识,将待识别的对象根据其特征归并到若干类别中某一类
模式识别定义
用各种数学方法让计算机(软件与硬件)来实现人的模式识别能力,即用计算机实现人对各种事物或现象的分析、描述、判断、识别
模式识别也可以看作是从特征向量向类别所做的映射
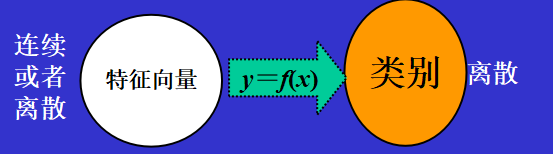
1.2 基本术语
样本(sample):
所研究对象的一个一个个体, 通常有一组特征构成的向量来描述,也称样本向量
样本集(sample set):
若干样本的集合
类或者类别(class):
在样本集上定义的模式类子集合,同一类的样本在我们所关心的某种性质上是不可区分的,即具有相同的模式。
特征(feature)或者属性(attribute):
描述样本的若干观测值。多个特征或属性构造特征向量或者属性向量,通常与样本向量混用。
2 模式识别的主要方法
1 根据问题的划分
监督模式识别(分类)
非监督模式识别(聚类)
2 根据理论基础的划分
统计模式识别
人工神经网络
结构模式识别
3 根据应用领域的划分
图像识别
文字识别
人脸识别
指纹识别
虹膜识别
掌纹识别
语音识别
3 模式识别系统

模式识别系统的主要组成部分:原始数据获取与预处理、特征提取和选择、分类或者聚类、后处理
3.1 处理监督模式识别问题的一般步骤
3.1.1 分析问题
- 针对具体的应用,分析是否可以转化成分类问题;
- 可能有那些类别;
- 已有的数据或者欲采集的数据中哪些因素或者特征与分类最具关联性。
3.1.2 原始数据获取与预处理、特征形成 - 设计采集数据方式,获取原始数据,并进行预处理
- 从原始数据获取样本的原始特征
- 构造出已知样本集
3.1.3 原始数据的获取
通过各种传感器,将光或声音等信息转化为电信息,或者将文字信息输入计算机
信息可以分成: - 一维波形:声波,心电图,脑电图等
- 二维图象:文字,图象等
- 物理量:人的身高、体重,商品的重量、质量级别等
- 逻辑量(0/1):有无、男女等
3.1.4 预处理
目的:去除噪声,增强有用的信息
常用技术:一维信号滤波去噪,图象的平滑、增强、恢复、滤波等
3.1.5 特征的提取和选择 - 目的:从原始数据中,得到最能反映分类本质的特征
- 特征形成:通过各种手段从原始数据中得出反映分类问题的若干特征(有时需进行数据标准化)
- 特征选择:从特征中选取最有利于分类的若干特征
- 特征提取:通过某些数学变换,降低特征数目
3.1.6 分类器设计
选定某一个分类器,用训练样本集对分类器进行训练,得到分类模型
3.1.7 分类决策 - 利用一定方式对分类器进行性能评价
- 对未知样本经过观测、预处理、特征形成、特征提取与选择,构造特征向量,用已经设计好的分类器进行决策(预测);
- 必要时再根据问题的背景知识进行适当的后处理
3.2 处理非监督模式识别问题的一般步骤
3.2.1 分析问题:
- 针对具有的应用,分析是否可以转化成聚类问题;
- 可能或者希望得到的类别数;
- 已有的数据或者欲采集的数据中那些因素或者特征与聚类相关。
3.2.2 原始数据获取与预处理、特征形成 - 设计采集数据方式,获取原始数据,并进行预处理
- 从原始数据获取样本的原始特征
- 构造出无类别标识的样本集(都是未知样本)
3.2.3 特征的提取与选择
了更好地进行聚类,经常需要采用一定的算法对原始特征进行提取与选择。一般来说,针对聚类的提取与选择要比分类更困难。
3.2.4 聚类分析
选定某一个非监督模式识别方法,对样本集进行聚类分析
3.2.5 结果解释 - 考查聚类结果的性能;
- 分析聚类结果与研究问题之间的关系;
- 根据问题背景知识分析聚类结果的可靠性;
- 解释类的含义;
- 如果有新样本,可以采用就近原则进行进行分类
4 统计模式识别:贝叶斯决策理论
- 利用概率论中的Bayes公式进行分类,可以得到错误率最小的分类规则
正确分类与错误分类
正确分类:将样本归属到样本本身所属的类别
错误分类:将样本归属到非样本本身所属的类别
5 线性线性分类器
Fisher线性判别分析(1936)的基本思想:
通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有性质:同类样本尽可能聚集在一起,不同类样本尽可能地远
算法的步骤:
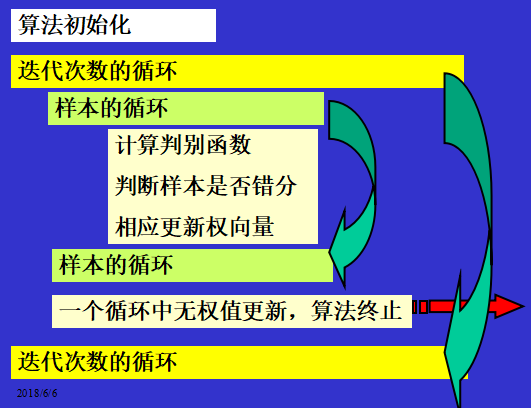
6 非线性分类器 神经网络
生物神经元结构
① 胞体:是神经细胞的本体,内有细胞核和细胞质,完成普通细胞的生存功能
② 树突:具有多达 103 数量级个的分枝,其长度较短,通常不超过一毫米,用以接受来自其他神经元的信号(输入端)
③轴突:用以输出信号,轴突远端有分枝,可与多个神经元连接(输出端)
④ 突触:轴突的末端与树突进行信号传递的界面(两个神经元的接口)
学习中的问题和解决过程
什么是虹膜识别?
虹膜识别的方法最早由美国的眼科医生Leonard Flom 和 Arin Safir在1987年提出来的。虹膜识别的算法是由剑桥大学John Dargman博士研究出来的。他提出了对虹膜进行编码、比较的数学算法。
虹膜是瞳孔周围的环状颜色组织,它有丰富而各不相同的纹理图案,构成了虹膜识别的基础。虹膜识别技术是通过一种近似红外线的光线对虹膜图案进行扫描成像,并通过图案象素位的异或操作来判定相似程度。虹膜识别过程首先需要把虹膜从眼睛图像中分离出来,再进行特征分析。理论上找到两个完全相同的虹膜的概率是120万分之一。这也是目前已知的所有生物识别技术中最为精确的。
虹膜识别因为设备复杂,扫描距离短(一般要求在7英寸范围以内),以及使用者心理上对健康的担心,而未能在民用市场大量使用。
其他
模式识别越来越多的应用到我们的生活领域,是属于人工智能的一小部分,最先听到有关人工智能这个词是在alphago,但对于具体的知识并不了解,通过本节课的学习让我清楚认识到模式识别。并且发现竟然与数学生物有如此紧密的联系。知识真的是融会贯通呀!