第十二章并发编程
1、如果逻辑控制流在时间上重叠,那么它们就是并发的。这种现象,称为并发(concurrency)。
2、为了允许服务器同时为大量客户端服务,比较好的方法是:创建并发服务器,为每个客户端创建各自独立的逻辑流。现代OS提供的常用构造并发的方法有:
进程和线程。
1)每个逻辑流都是一个进程,由内核来调度维护。每个进程都有独立的虚拟地址空间,控制流通过IPC机制来进行通信。
2)线程:运行在单一进程上下文中的逻辑流,由内核进行调度,共享同一进程的虚拟地址空间。
由于进程控制和IPC的开销较高,所以基于进程的设计比基于线程的设计慢。
常见IPC有:管道,FIFO,共享存储器,信号。
3、基于线程的并发编程
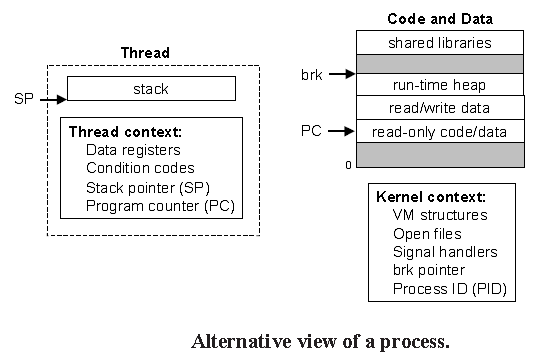
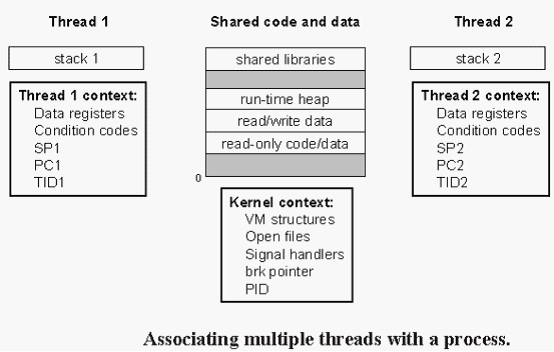
线程由内核自动调度,每个线程都有它自己的线程上下文(thread context),包括一个惟一的整数线程ID(Thread ID,TID),栈,栈指针,程序计数器,通用目的寄存器和条件码。每个线程和其他线程一起共享进程上下文的剩余部分,包括整个用户的虚拟地址空间,它是由只读文本(代码),读/写数据,堆以及所有的共享库代码和数据区域组成的,还有,线程也共享同样的打开文件的集合。
1)线程执行模型
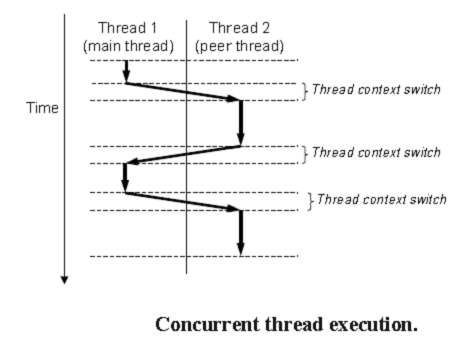
线程不像进程那样,不是按照严格的父子层次来组织的。和一个进程相关的线程组成一个对等线程池(a pool of peers),独立于其他线程创建的线程(The threads associated with a process form a pool of peers, independent of which threads were created by which other threads.个人理解,这句是说独立于其他进程的线程池中的线程)。进程中第一个运行的线程称为主线程。对等(线程)池概念的主要影响是,一个线程可以杀死它的任何对等线程,或者等待它的任意对等线程终止;进一步来说,每个对等线程都能读写相同的共享数据。
2)关于posix线程示例,及其相关函数,参见原书13.3.2节中。这部分举的例子很经典,值得一读
3)分离线程
在任何一个时间点上,线程是可结合的(joinable),或者是分离的(detached)。一个可结合的线程能够被其他线程收回其资源和杀死。在被其他线程回收之前,它的存储器资源(如栈)是不释放的。相反,一个分离的线程是不能被其他线程回收或杀死的,它的存储器资源在它终止时由系统自动释放。
示例程序
/*
* echoservert.c - A concurrent echo server using threads
/
/ $begin echoservertmain */
include "csapp.h"
void echo(int connfd);
void *thread(void *vargp);
int main(int argc, char **argv)
{
int listenfd, *connfdp, port, clientlen=sizeof(struct sockaddr_in);
struct sockaddr_in clientaddr;
pthread_t tid;
if (argc != 2) {
fprintf(stderr, "usage: %s
exit(0);
}
port = atoi(argv[1]);
listenfd = Open_listenfd(port);
while (1) {
connfdp = Malloc(sizeof(int));
*connfdp = Accept(listenfd, (SA ) &clientaddr, &clientlen);
Pthread_create(&tid, NULL, thread, connfdp);
}
}
/ thread routine */
void *thread(void *vargp)
{
int connfd = *((int )vargp);
Pthread_detach(pthread_self());
Free(vargp);
echo(connfd);
Close(connfd);
return NULL;
}
/ $end echoservertmain /
1、共享变量
1)线程存储模型
线程由内核自动调度,每个线程都有它自己的线程上下文(thread context),包括一个惟一的整数线程ID(Thread ID,TID),栈,栈指针,程序计数器,通用目的寄存器和条件码。每个线程和其他线程一起共享进程上下文的剩余部分,包括整个用户的虚拟地址空间,它是由只读文本(代码),读/写数据,堆以及所有的共享库代码和数据区域组成的,还有,线程也共享同样的打开文件的集合。[1]
寄存器从不共享,而虚拟存储器总是共享。
The memory model for the separate thread stacks is not as clean(整齐清楚的). These stacks are contained in the stack area of the virtual address space, and are usually accessed independently by their respective threads. We say usually rather than always, because different thread stacks are not protected from other threads. So if a thread somehow manages to acquire a pointer to another thread’s stack, then it can read and write any part of that stack. 示例29行中, where the peer threads reference the contents of the main thread’s stack indirectly through the global ptr variable.
2)将变量映射到存储器
和全局变量一样,虚拟存储器的读/写区域只包含在程序中声明的每个本地静态变量的一个实例。每个线程的栈都包含它自己的所有本地自动变量的实例。
3)我们说变量v是共享的,当且仅当它的一个实例被一个以上的线程引用。
示例代码
/ $begin sharing */
include "csapp.h"
define N 2
void *thread(void *vargp);
char *ptr; / global variable */
int main()
{
int i;
pthread_t tid;
char *msgs[N] = {
"Hello from foo",
"Hello from bar"
};
ptr = msgs;
for (i = 0; i < N; i++)
Pthread_create(&tid, NULL, thread, (void *)i);
Pthread_exit(NULL);
}
void *thread(void vargp)
{
int myid = (int)vargp; //cnt是共享的,而myid不是共享的
static int cnt = 0;
printf("[%d]: %s (cnt=%d)
", myid, ptr[myid], ++cnt);
}
/ $end sharing */
2、用信号量同步
当对同一共享变量,有多个线程进行更新时,由于每一次更新,对该变量来说,都有“加载到寄存器,更新之,存储写回到存储器”这个过程,多个线程操作时,便会产生错位,混乱的情况,有必要对共享变量作一保护,使这个更新操作具有原子性。
信号量s是具有非页整数值的全局变量,只能由两种特殊的操作来处理,称为P,V操作。
P(s):
while (s <= 0); s--;
V (s): s++;
The P operation waits for the semaphore s to become nonzero, and then decrements it.The V operation increments s.
1)基本思想是,将每个共享变量(或者相关共享变量集合)与一个信号量s(初始值1)联系起来,然后用P(s),V(s)操作将相应的临界区(一段代码)包围起来。以这种方法来保护共享变量的信号量叫做二进制信号量(binary semaphore),因为值总是1,0。
The definitions of P and V ensure that a running program can never enter a state where a properly initialized semaphore has a negative value.
11.4.4有posix信号量的简介。
2)二进制信号量通常叫做互斥锁,在互斥锁上执行一个P操作叫做加锁,V操作叫做解锁;一个已经对一个互斥锁加锁而还没有解锁的线程被称为占用互斥锁。
3、用信号量来调度共享资源
这种情况下,一个线程用信号量来通知另一个线程,程序状态中的某个条件已经为真了。如生产者-消费者问题。
示例代码
ifndef SBUF_H
define SBUF_H
include "csapp.h"
/* $begin sbuft */
typedef struct {
int buf; / Buffer array /
int n; / Maximum number of slots /
int front; / buf[(front+1)%n] is first item /
int rear; / buf[rear%n] is last item /
sem_t mutex; / Protects accesses to buf /
sem_t slots; / Counts available slots /
sem_t items; / Counts available items /
} sbuf_t;
/ $end sbuft */
void sbuf_init(sbuf_t *sp, int n);
void sbuf_deinit(sbuf_t *sp);
void sbuf_insert(sbuf_t *sp, int item);
int sbuf_remove(sbuf_t *sp);
endif /* SBUF_H */
//source code
/* $begin sbufc */
include "csapp.h"
include "sbuf.h"
/* Create an empty, bounded, shared FIFO buffer with n slots /
/ $begin sbuf_init */
void sbuf_init(sbuf_t sp, int n)
{
sp->buf = Calloc(n, sizeof(int));
sp->n = n; / Buffer holds max of n items /
sp->front = sp->rear = 0; / Empty buffer iff front == rear /
Sem_init(&sp->mutex, 0, 1); / Binary semaphore for locking /
Sem_init(&sp->slots, 0, n); / Initially, buf has n empty slots /
Sem_init(&sp->items, 0, 0); / Initially, buf has zero data items /
}
/ $end sbuf_init /
/ Clean up buffer sp /
/ $begin sbuf_deinit */
void sbuf_deinit(sbuf_t sp)
{
Free(sp->buf);
}
/ $end sbuf_deinit /
/ Insert item onto the rear of shared buffer sp /
/ $begin sbuf_insert */
void sbuf_insert(sbuf_t sp, int item)
{
P(&sp->slots); / Wait for available slot /
P(&sp->mutex); / Lock the buffer /
sp->buf[(++sp->rear)%(sp->n)] = item; / Insert the item /
V(&sp->mutex); / Unlock the buffer /
V(&sp->items); / Announce available item /
}
/ $end sbuf_insert /
/ Remove and return the first item from buffer sp /
/ $begin sbuf_remove */
int sbuf_remove(sbuf_t sp)
{
int item;
P(&sp->items); / Wait for available item /
P(&sp->mutex); / Lock the buffer /
item = sp->buf[(++sp->front)%(sp->n)]; / Remove the item /
V(&sp->mutex); / Unlock the buffer /
V(&sp->slots); / Announce available slot /
return item;
}
/ $end sbuf_remove /
/ $end sbufc */
1、基于预线程化(prethreading)的并发服务器
常规的并发服务器中,我们为每一个客户端创建一个新线程,代价较大。一个基于预线程化的服务器通过使用“生产者-消费者模型”来试图降低这种开销。
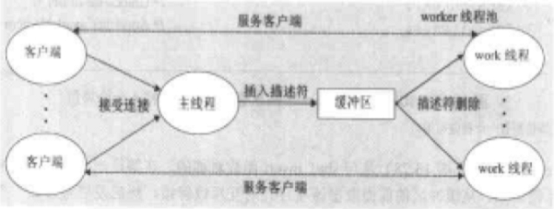
服务器由一个主线程和一组worker线程组成的,主线程不断地接受来自客户端的连接请求,并将得到的连接描述符放在一个共享的缓冲区中。每一个worker线程反复从共享缓冲区中取出描述符,为客户端服务,然后等待下一个描述符。
示例代码
/*
* echoservert_pre.c - A prethreaded concurrent echo server
/
/ $begin echoservertpremain */
include "csapp.h"
include "sbuf.h"
define NTHREADS 4
define SBUFSIZE 16
void echo_cnt(int connfd);
void *thread(void vargp);
sbuf_t sbuf; / shared buffer of connected descriptors */
int main(int argc, char *argv)
{
int i, listenfd, connfd, port, clientlen=sizeof(struct sockaddr_in);
struct sockaddr_in clientaddr;
pthread_t tid;
if (argc != 2) {
fprintf(stderr, "usage: %s
exit(0);
}
port = atoi(argv[1]);
sbuf_init(&sbuf, SBUFSIZE);
listenfd = Open_listenfd(port);
for (i = 0; i < NTHREADS; i++) /
Pthread_create(&tid, NULL, thread, NULL);
while (1) {
connfd = Accept(listenfd, (SA ) &clientaddr, &clientlen);
sbuf_insert(&sbuf, connfd); / Insert connfd in buffer */
}
}
void *thread(void vargp)
{
Pthread_detach(pthread_self());
while (1) {
int connfd = sbuf_remove(&sbuf); / Remove connfd from buffer /
echo_cnt(connfd); / Service client /
Close(connfd);
}
}
/ $end echoservertpremain */
如上模型组成事件驱动服务器,事件驱动程序创建它们自己的并发逻辑流,这些逻辑流被模型化为状态机,带有主线程和worker线程的简单状态机。
2、其他并发问题
一个函数被称为线程安全(thread-safe)的,当且仅当多个线程反复地调用时,它会一下产生正确的结果。
下面是四类不安全(相交)的函数:
1)不保护共享变量的函数
利用P,V操作解决这个问题。
2)保持跨越多个调用的状态的函数
示例代码
include <stdio.h>
/* $begin rand /
unsigned int next = 1;
/ rand - return pseudo-random integer on 0..32767 /
int rand(void)
{
next = next1103515245 + 12345;
return (unsigned int)(next/65536) % 32768;
}
/* srand - set seed for rand() /
void srand(unsigned int seed)
{
next = seed;
}
/ $end rand */
int main()
{
srand(100);
printf("%d
", rand());
printf("%d
", rand());
printf("%d
", rand());
exit(0);
}
srand设置种子,调用rand生成随机数。多线程调用时就出问题了。我们可以重写之解决,使之不再使用任何静态数据,取而代之地依靠调用者在参数中传递状态信息。
示例代码
include <stdio.h>
/* $begin rand_r /
/ rand_r - a reentrant pseudo-random integer on 0..32767 */
int rand_r(unsigned int *nextp)
{
nextp = nextp * 1103515245 + 12345;
return (unsigned int)(nextp / 65536) % 32768;
}
/ $end rand_r */
int main()
{
unsigned int next = 1;
printf("%d
", rand_r(&next));
printf("%d
", rand_r(&next));
printf("%d
", rand_r(&next));
exit(0);
}
3)返回指向静态变量的指针的函数
某些函数(如gethostbyname)将结果放在静态结构中,并返回一个指向这个结构的指针。多线程并发可能引发灾难,因为正在被一个线程使用的结果会被另一个线程悄悄覆盖。
两种方法处理:
一是重写之。使得调用者传递存放结果的结构的地址,这就消除了共享数据。
第二种方法是:使用称为lock-and-copy的技术。在每一个调用位置,对互斥锁加锁,调用线程不安全函数,动态地为结果分配存储器,copy函数返回结果到这个存储器位置,对互斥锁解锁。
示例代码
/*
* gethostbyname_ts - A thread-safe wrapper for gethostbyname
*/
include "csapp.h"
static sem_t mutex; /* protects calls to gethostbyname /
static void init_gethostbyname_ts(void)
{
Sem_init(&mutex, 0, 1);
}
/ $begin gethostbyname_ts */
struct hostent *gethostbyname_ts(char *hostname)
{
struct hostent *sharedp, *unsharedp;
unsharedp = Malloc(sizeof(struct hostent));
P(&mutex);
sharedp = gethostbyname(hostname);
*unsharedp = sharedp; / copy shared struct to private struct /
V(&mutex);
return unsharedp;
}
/ $end gethostbyname_ts */
int main(int argc, char **argv)
{
char **pp;
struct in_addr addr;
struct hostent *hostp;
if (argc != 2) {
fprintf(stderr, "usage: %s
exit(0);
}
init_gethostbyname_ts();
hostp = gethostbyname_ts(argv[1]);
if (hostp) {
printf("official hostname: %s
", hostp->h_name);
for (pp = hostp->h_aliases; *pp != NULL; pp++)
printf("alias: %s
", *pp);
for (pp = hostp->h_addr_list; *pp != NULL; pp++) {
addr.s_addr = *((unsigned int )pp);
printf("address: %s
", inet_ntoa(addr));
}
}
else {
printf("host %s not found
", argv[1]);
}
exit(0);
}
4)调用线程不安全函数的函数
f调用g。如果g是2)类函数,则f也是不安全的,只能得写。如果g是1)或3)类函数,则利用互斥锁保护调用位置和任何想得到的共享数据,f仍是线程安全的。如上例中。
3、可重入性
可重入函数(reenterant function)具有这样的属性:当它们被多个线程调用时,不会引用任何共享数据。
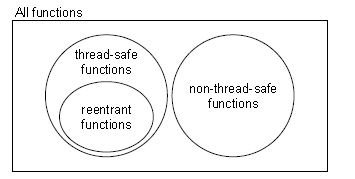
可重入函数通常比不可重入函数高效一些,因为不需要同步操作。
如果所有的函数参数都是传值传递(没有指针),且所有的数据引用都是本地的自动栈变量(没有引用静态或全局变量),则函数是显式可重入的,无论如何调用,都没有问题。
允许显式可重入函数中部分参数用指针传递,则隐式可重入的。在调用线程时小心传递指向非共享数据的指针,它才是可重入。如rand_r。
可重入性同时是调用者和被调用者的属性。
4、C库中常用的线程不安全函数及unix线程安全版本

5、竞争
当一个程序的正确性依赖于一个线程要在另一个线程到达y点之前到达它的控制流中的x点时,就会发生竞争(race)。
示例代码
/*
* race.c - demonstrates a race condition
/
/ $begin race */
include "csapp.h"
define N 4
void *thread(void vargp);
int main()
{
pthread_t tid[N];
int i;
for (i = 0; i < N; i++)
Pthread_create(&tid[i], NULL, thread, &i);
for (i = 0; i < N; i++)
Pthread_join(tid[i], NULL);
exit(0);
}
/ thread routine */
void *thread(void *vargp)
{
int myid = *((int )vargp);
printf("Hello from thread %d
", myid);
return NULL;
}
/ $end race */
示例代码2(消除竞争)
*
* norace.c - fixes the race in race.c
/
/ $begin norace */
include "csapp.h"
define N 4
void *thread(void *vargp);
int main()
{
pthread_t tid[N];
int i, *ptr;
for (i = 0; i < N; i++) {
ptr = Malloc(sizeof(int));
ptr = i;
Pthread_create(&tid[i], NULL, thread, ptr);
}
for (i = 0; i < N; i++)
Pthread_join(tid[i], NULL);
exit(0);
}
/ thread routine */
void *thread(void *vargp)
{
int myid = *((int *)vargp);
Free(vargp);
printf("Hello from thread %d
", myid);
return NULL;
}
6、死锁
信号量引入一个潜在的运行是错误-死锁。死锁是因为每个线程都在等待其他线程运行一个根本不可能发生的V操作。
避免死锁是很困难的。当使用二进制信号量来实现互斥时,可以用如下规则避免:
如果用于程序中每对互斥锁(s,t),每个既包含s也包含t的线程都按照相同顺序同时对它们加锁,则程序是无死锁的。