本文由 网易云 发布。
在之前的文章中简要介绍了Join在大数据领域中的使用背景以及常用的几种算法-broadcast hash join 、shuffle hash join以及 sort merge join等,对每一种算法的核心应用场景也做了相关介绍,这里再重点说明一番:大表与小表进行join会使用broadcast hash join,一旦小表稍微大点不再适合广播分发就会选择shuffle hash join,最后,两张大表的话无疑选择sort merge join。
好了,问题来了,说是这么一说,但到底选择哪种算法归根结底是SQL执行引擎干的事情,按照上文逻辑,SQL执行引擎肯定要知 道参与Join的两表大小,才能选择最优的算法喽!那么斗胆问一句,怎么知道两表大小?衡量两表大小的是物理大小还是纪录多少 抑或两者都有?其实,这是另一门学问-基于代价优化(Cost Based Optimization,简称CBO),它不仅能够解释Join算法的选 择问题,更重要的,它还能确定多表联合Join场景下的Join顺序问题。
是不是对CBO很期待呢?好吧,这里先刨个坑,下一个话题我们再聊。那今天要聊点什么呢?Join算法选择、Join顺序选择确实对 Join性能影响极大,但,还有一个很重要的因素对Join的性能至关重要,那就是Join算法优化!无论是broadcast hash join、 shuffle hash join还是sort merge join,都是最基础的join算法,有没有什么优化方案呢?还真有,这就是今天要聊的主角- Runtime Filter(下文简称RF)。
RF预备知识:bloom filter
RF说白了是使用bloomfilter对参与join的表进行过滤,减少实际参与join的数据量。为了下文详细解释整个流程,有必要先解释一 下bloomfilter这个数据结构(对之熟悉的看官可以绕道)。Bloom Filter使用位数组来实现过滤,初始状态下位数组每一位都为 0,如下图所示:

假如此时有一个集合S = {x1,x2,...,xn},Bloom Filter使用k个独立的hash函数,分别将集合中的每一个元素映射到{1,…,m}的范围。 对于任何一个元素,被映射到的数字作为对应的位数组的索引,该位会被置为1。比如元素x1被hash函数映射到数字8,那么位数组 的第8位就会被置为1。下图中集合S只有两个元素x和y,分别被3个hash函数进行映射,映射到的位置分别为(0,3,6)和(4,7,10),对 应的位会被置为1:
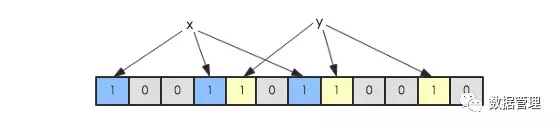
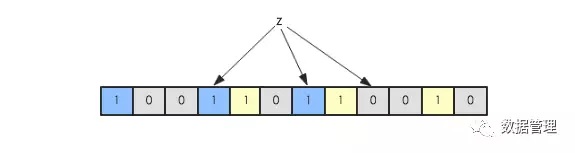
现在假如要判断另一个元素是否是在此集合中,只需要被这3个hash函数进行映射,查看对应的位置是否有0存在,如果有的话,表 示此元素肯定不存在于这个集合,否则有可能存在。下图所示就表示z肯定不在集合{x,y}中:
RF算法理论
为了更好地说明整个过程,这里使用一个SQL示例对RF算法进行完整讲解,SQL:select item.name,order.* from order,item where order.item_id = item.id and item.category = ‘book’,其中order为订单表,item为商品表,两张表根据商品id字段 进行join,该SQL意为取出商品类别为书籍的所有订单详情。假设商品类型为书籍的商品并不多,join算法因此确定为broadcast hash join。整个流程如下图所示:
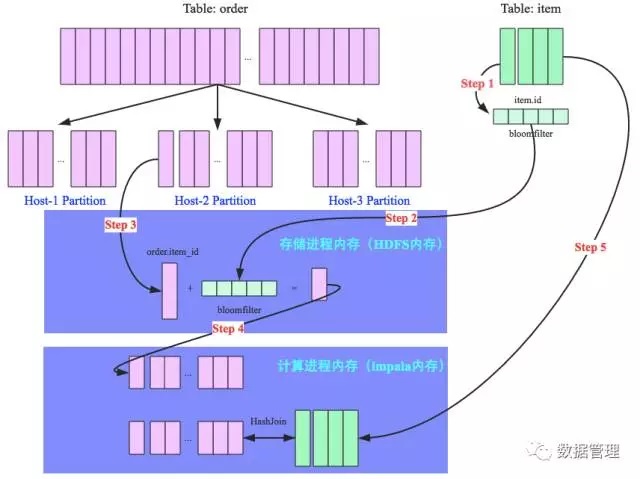
Step 1:将item表的join字段(item.id)经过多个hash函数映射处理为一个bloomfilter(如果对bloomfilter不了解,自行 google);
Step 2:将映射好的bloomfilter分别广播到order表的所有partition上,准备进行过滤;
Step 3:以Partition2为例,存储进程(比如DataNode进程)将order表中join列(order.item_id)数据一条一条读出来,使用 bloomfilter进行过滤。淘汰该订单数据不是书籍相关商品的订单,这条数据直接跳过;否则该条订单数据有可能是待检索订单,将 该行数据全部扫描出来;
Step 4:将所有未被bloomfilter过滤掉的订单数据,通过本地socket通信发送到计算进程(impalad);
Step 5:再将所有书籍商品数据广播到所有Partition节点与step4所得订单数据进行真正的hashjoin操作,得到最终的选择结果。
RF算法分析
上面通过一个SQL示例简单演示了整个RF算法在broadcast hash join中的操作流程,根据流程对该算法进行一下理论层次分析:
RF本质:通过谓词( bloomfilter)下推,在存储层通过bloomfilter对数据进行过滤,可以从三个方面实现对Join的优化。其一, 如果可以跳过很多记录,就可以减少了数据IO扫描次数。这点需要重点解释一下,许多朋友会有这样的疑问:既然需要把数据扫描 出来使用BloomFilter进行过滤,为什么还会减少IO扫描次数呢?这里需要关注一个事实:大多数表存储行为都是列存,列之间独 立存储,扫描过滤只需要扫描join列数据(而不是所有列),如果某一列被过滤掉了,其他对应的同一行的列就不需要扫描了,这 样减少IO扫描次数。其二,减少了数据从存储层通过socket(甚至TPC)发送到计算层的开销,其三,减少了最终hash join执行的 开销。
RF代价:对照未使用RF的Broadcast Hash Join来看,前者主要增加了bloomfilter的生成、广播以及大表根据bloomfilter进行过 滤这三个开销。通常情况下,这几个步骤在小表较小的情况下代价并不大,基本可以忽略。
RF优化效果:基本取决于bloomfilter的过滤效果,如果大量数据被过滤掉了,那么join的性能就会得到极大提升;否则性能提升就 会有限。
RF实现:和常见的谓词下推(’=‘,’>’,’<‘等)一样,RF实现需要在计算层以及存储层分别进行相关逻辑实现,计算层 要构造bloomfilter并将bloomfilter下传到存储层,存储层要实现使用该bloomfilter对指定数据进行过滤。
RF效果验证
事实上,RF这个东东的优化效果是在组内同事何大神做impala on parquet以及impala on kudu的基准对比测试的时候分析发现 的。实际测试中,impala on parquet 比之impala on kudu性能有明显优势,目测至少10倍性能提升。同一SQL解析引擎,不同 存储引擎,性能竟然天壤之别!为了分析具体原因,同事就使用impala的执行计划分析工具对两者的执行计划分别进行了分析,才 透过蛛丝马迹发现前者使用了RF,而后者并没有(当然可能还有其他因素,但RF肯定是原因之一)。
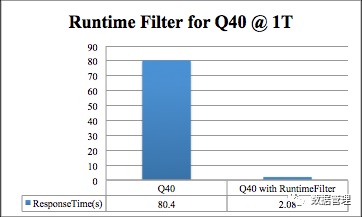
简单复盘一下这次测试吧,基准测试使用TPCDS测试,数据规模为1T,本文使用测试过程中的一个典型SQL(Q40)作为示例对RF 的神奇功效进行回放演示。下图是Q40的对比性能,直观上来看RF可以直接带来40x的性能提升,40倍哎,这到底是怎么做到的?
先来简单看看Q40的SQL语句,如下所示,看起来比较复杂,核心涉及到3个表(catalog_sales join date_dim 、catalog_sales join warehouse 、catalog_sales join item)的join操作:
select
w_state, i_item_id,
sum(case when (cast(d_date as date) <
cast ('1998-04-08' as date))
then cs_sales_price –
coalesce(cr_refunded_cash,0)
else 0 end) as sales_before,
sum(case when (cast(d_date as date) >=
cast ('1998-04-08' as date))
then cs_sales_price –
coalesce(cr_refunded_cash,0)
else 0 end) as sales_after
from
catalog_sales left outer join catalog_returns
on
(catalog_sales.cs_order_number =
catalog_returns.cr_order_number
and catalog_sales.cs_item_sk =
catalog_returns.cr_item_sk),
warehouse, item, date_dim where
i_current_price between 0.99 and 1.49
and item.i_item_sk = catalog_sales.cs_item_sk
and catalog_sales.cs_warehouse_sk =
warehouse.w_warehouse_sk
and catalog_sales.cs_sold_date_sk =
date_dim.d_date_sk
and date_dim.d_date between
'1998-03-09' and '1998-05-08' group by w_state, i_item_id order by w_state, i_item_id limit 100;
典型的星型结构,其中catalog_sales是事实表,其他表为纬度表。本次分析选择其中catalog_sales join item这个纬度的join。因 为对比测试中两者的SQL解析引擎都是使用impala,所以SQL执行计划基本都相同。在此基础上,来看看执行计划中单个执行节点 在执行catalog_sales join item操作时由先到后的主要阶段耗时,其中只贴出来重要耗时阶段(Q40中Join算法为shuffle hash join,与上文所举broadcast hash join示例略有不同,不过不影响结论):
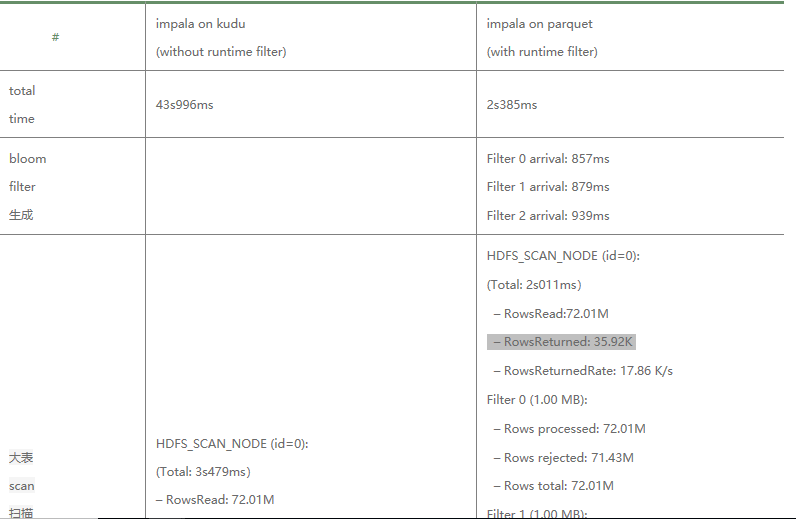
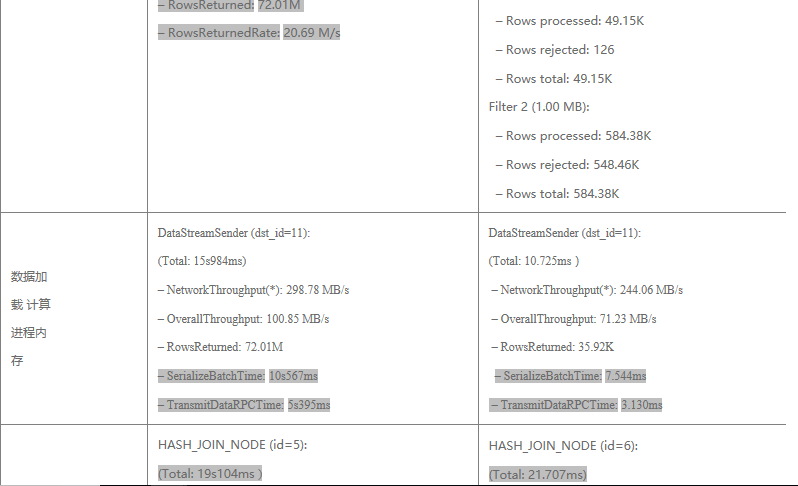
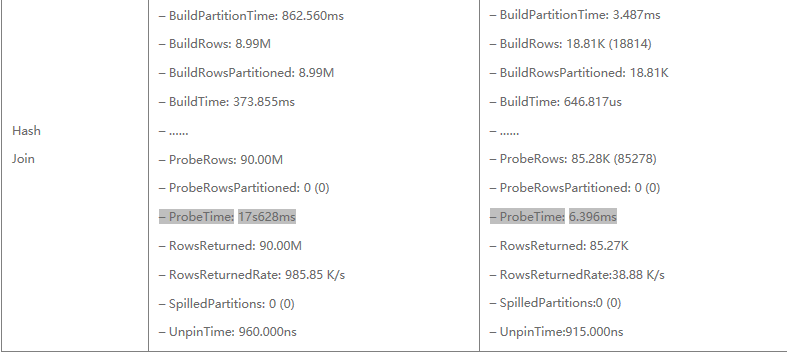
经过对两种场景执行计划的解析,可以基本验证上文所做的基本理论结果:
1. 确认经过RF之后大表的数据量得到大量滤除,只剩下少量数据参与最终的HashJoin。参见第二行大表scan扫描结果,未使用rf的 返回结果有7千万行+纪录,而经过RF过滤之后满足条件的只有3w+纪录。3万相比7千万,性能优化效果自然不言而喻。
2. 经过RF滤除之后,少量数据经过网络从存储进程加载到计算进程内存的网络耗时大量减少。参见第三行“数据加载到计算进程内 存”,前者耗时15s,后者耗时仅仅11ms。主要耗时分为两部分,其中数据序列化时间占到2/3-10s左右,数据经过RPC传输时间 占另外1/3 -5s左右。
3.最后,经过RF滤除之后,参与到最终Hash Join的数量大幅减少,Hash Join 耗时前者是19s,后者是21ms左右,主要耗时在于大表Probe Time,前者消耗了17s左右,而后者仅需6ms。
说好的谓词下推?
讲真,刚开始接触RF的时候觉得这简直是一个实实在在的神器,崇拜之情溢于言表。然而,经过一段时间的探索消化,直至把这篇 文章写完,也就是此时此刻,忽然觉得它并不高深莫测,说白了就是一个谓词下推,不同的是这里的谓词稍微奇怪一点,是一个 bloomfilter而已。
提到谓词下推,这里再引申一下下。以前经常满大街听到谓词下推,然而对谓词下推却总感觉懵懵懂懂,并不明白的很真切。经过 RF的洗礼,现在确信有了更进一步的理解。这里拿出来和大家交流交流。个人认为谓词下推有两个层面的理解:
其一是逻辑执行计划优化层面的说法,比如SQL语句:select * from order ,item where item.id = order.item_id and item.category = ‘book’,正常情况语法解析之后应该是先执行Join操作,再执行Filter操作。通过谓词下推,可以将Filter操作 下推到Join操作之前执行。即将where item.category = ‘book’下推到 item.id = order.item_id之前先行执行。
其二是真正实现层面的说法,谓词下推是将过滤条件从计算进程下推到存储进程先行执行,注意这里有两种类型进程:计算进程以 及存储进程。计算与存储分离思想,这在大数据领域相当常见,比如最常见的计算进程有SparkSQL、Hive、impala等,负责SQL 解析优化、数据计算聚合等,存储进程有HDFS(DataNode)、Kudu、HBase,负责数据存储。正常情况下应该是将所有数据从 存储进程加载到计算进程,再进行过滤计算。谓词下推是说将一些过滤条件下推到存储进程,直接让存储进程将数据过滤掉。这样 的好处显而易见,过滤的越早,数据量越少,序列化开销、网络开销、计算开销这一系列都会减少,性能自然会提高。
写到这里,忽然意识到笔者在上文出现了一个很严重的认知错误:RF机制并不仅仅是一个简单的谓词下推,它的精髓在于提出了一 个重要的谓词-bloomfilter。当前对RF支持的系统并不多,笔者只知道目前唯有Impala on Parquet进行了支持。Impala on Kudu虽说Impala支持,但Kudu并不支持。SparkSQL on Parqeut中虽有存储系统支持,无奈计算引擎-SparkSQL目前还不支 持。
本文主要介绍了一种类似于semi-join的优化方法,对优化细节进行了深入地探讨,并结合分析过程对谓词下推技术谈了谈自己的理 解。后续将会为各位看官带来基于代价优化(CBO)相关的议题,敬请期待!
网易有数
企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。
点击这里---免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/