LRU原理与分析
LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”,也就是说,LRU缓存把最近最少使用的数据移除,让给最新读取的数据。而往往最常读取的,也是读取次数最多的,所以,利用LRU缓存,我们能够提高系统的performance.
LRU实现
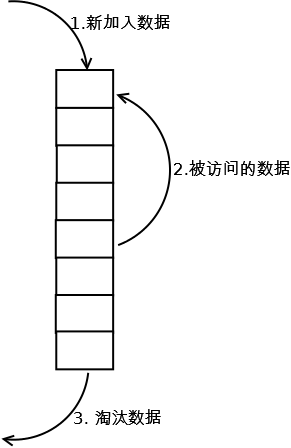
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
LRU分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
LRU实现
细节
添加元素时,放到链表头
缓存命中,将元素移动到链表头
缓存满了之后,将链表尾的元素删除
LRU算法实现
- 可以用一个双向链表保存数据
- 使用hash实现O(1)的访问
groupcache中LRU算法实现(Go语言)
https://github.com/golang/groupcache/blob/master/lru/lru.go
源码简单注释:
package lru
import "container/list"
// Cache 结构体,定义lru cache 不是线程安全的
type Cache struct {
// 数目限制,0是无限制
MaxEntries int
// 删除时, 可以添加可选的回调函数
OnEvicted func(key Key, value interface{})
ll *list.List // 使用链表保存数据
cache map[interface{}]*list.Element // map
}
// Key 是任何可以比较的值 http://golang.org/ref/spec#Comparison_operators
type Key interface{}
type entry struct {
key Key
value interface{}
}
// 创建新的cache 对象
func New(maxEntries int) *Cache {
return &Cache{
MaxEntries: maxEntries,
ll: list.New(),
cache: make(map[interface{}]*list.Element),
}
}
// 添加新的值到cache里
func (c *Cache) Add(key Key, value interface{}) {
if c.cache == nil {
c.cache = make(map[interface{}]*list.Element)
c.ll = list.New()
}
if ee, ok := c.cache[key]; ok {
// 缓存命中移动到链表的头部
c.ll.MoveToFront(ee)
ee.Value.(*entry).value = value
return
}
// 添加数据到链表头部
ele := c.ll.PushFront(&entry{key, value})
c.cache[key] = ele
if c.MaxEntries != 0 && c.ll.Len() > c.MaxEntries {
// 满了删除最后访问的元素
c.RemoveOldest()
}
}
// 从cache里获取值.
func (c *Cache) Get(key Key) (value interface{}, ok bool) {
if c.cache == nil {
return
}
if ele, hit := c.cache[key]; hit {
// 缓存命中,将命中元素移动到链表头
c.ll.MoveToFront(ele)
return ele.Value.(*entry).value, true
}
return
}
// 删除指定key的元素
func (c *Cache) Remove(key Key) {
if c.cache == nil {
return
}
if ele, hit := c.cache[key]; hit {
c.removeElement(ele)
}
}
// 删除最后访问的元素
func (c *Cache) RemoveOldest() {
if c.cache == nil {
return
}
ele := c.ll.Back()
if ele != nil {
c.removeElement(ele)
}
}
func (c *Cache) removeElement(e *list.Element) {
c.ll.Remove(e)
kv := e.Value.(*entry)
delete(c.cache, kv.key)
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
}
// cache 缓存数
func (c *Cache) Len() int {
if c.cache == nil {
return 0
}
return c.ll.Len()
}
LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
实现
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
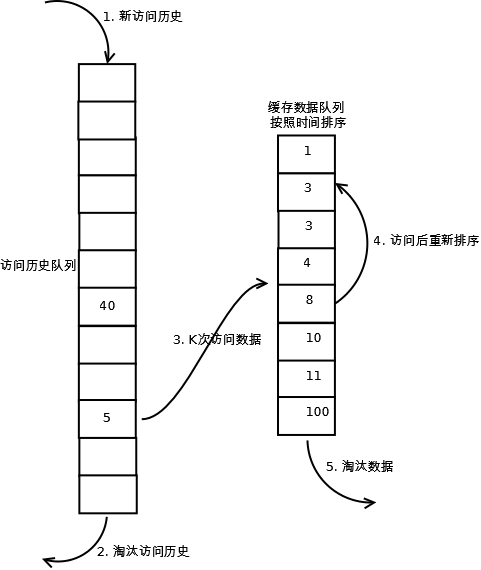
1. 数据第一次被访问,加入到访问历史列表;
2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
4. 缓存数据队列中被再次访问后,重新排序;
5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
分析
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高。