0.我们有这样一个表,表名为Student

1.在Hbase中创建一个表

表明为student,列族为info
2.插入数据
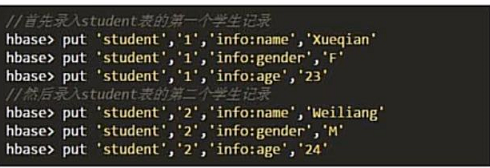
我们这里采用put来插入数据
格式如下 put ‘表命’,‘行键’,‘列族:列’,‘值’
我们知道Hbase 四个键确定一个值,
一般查询的时候我们需要提供 表名、行键、列族:列名、时间戳才会有一个确定的值。
但是这里插入的时候,时间戳自动被生成,我们并不用额外操作。
我们不用表的时候可以这样删除

注意,一定要先disable 再drop,不能像RDMS一样直接drop
3.配置spark
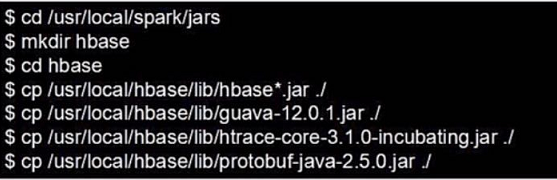
我们需要把Hbase的lib目录下的一些jar文件拷贝到Spark中,这些都是编程中需要引进的jar包。
需要拷贝的jar包包括:所有hbase开头的jar文件、guava-12.0.1.jar、htrace-core-3.1.0-incubating.jar和protobuf-java-2.5.0.jar
我们将文件拷贝到Spark目录下的jars文件中
4.编写程序
(1)读取数据

我们程序中需要的jar包如下

我们这里使用Maven来导入相关jar包
我们需要导入hadoop和spark相关的jar包
spark方面需要导入的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
hadoop方面需要导入的依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
hbase方面需要导入的依赖
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
我们使用的org.apache.hadoop.hbase.mapreduce是通过hbase-server导入的。
具体的程序如下
import org.apache.hadoop.hbase._
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
object SparkOperateHbase{
def main(args:Array[String]): Unit ={
//建立Hbase的连接
val conf = HBaseConfiguration.create();
//设置查询的表名student
conf.set(TableInputFormat.INPUT_TABLE,"student")
//通过SparkContext将student表中数据创建一个rdd
val sc = new SparkContext(new SparkConf());
val stuRdd = sc.newAPIHadoopRDD(conf,classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result]);
stuRdd.cache();//持久化
//计算数据条数
val count = stuRdd.count();
println("Student rdd count:"+count);
//遍历输出
//当我们建立Rdd的时候,前边全部是参数信息,后边的result才是保存数据的数据集
stuRdd.foreach({case (_,result) =>
//通过result.getRow来获取行键
val key = Bytes.toString(result.getRow);
//通过result.getValue("列族","列名")来获取值
//注意这里需要使用getBytes将字符流转化成字节流
val name = Bytes.toString(result.getValue("info".getBytes,"name".getBytes));
val gender = Bytes.toString(result.getValue("info".getBytes,"gender".getBytes));
val age = Bytes.toString(result.getValue("info".getBytes,"age".getBytes));
//打印结果
println("Row key:"+key+" Name:"+name+" Gender:"+gender+" Age:"+age);
});
}
}
(2)存入数据
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.{SparkConf, SparkContext}
object HbasePut{
def main(args:Array[String]): Unit = {
//建立sparkcontext
val sparkConf = new SparkConf().setAppName("HbasePut").setMaster("local")
val sc = new SparkContext(sparkConf)
//与hbase的student表建立连接
val tableName = "student"
sc.hadoopConfiguration.set(TableOutputFormat.OUTPUT_TABLE,tableName)
//建立任务job
val job = new Job(sc.hadoopConfiguration)
//配置job参数
job.setOutputKeyClass(classOf[ImmutableBytesWritable])
job.setOutputValueClass(classOf[Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
//要插入的数据,这里的makeRDD是parallelize的扩展版
val indataRdd = sc.makeRDD(Array("3,zhang,M,26","4,yue,M,27"))
val rdd = indataRdd.map(_.split(",")).map(arr=>{
val put = new Put(Bytes.toBytes(arr(0))) //行键的值
//依次给列族info的列添加值
put.add(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(arr(1)))
put.add(Bytes.toBytes("info"),Bytes.toBytes("gender"),Bytes.toBytes(arr(2)))
put.add(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(arr(3)))
//必须有这两个返回值,put为要传入的数据
(new ImmutableBytesWritable,put)
})
rdd.saveAsNewAPIHadoopDataset(job.getConfiguration)
}
}
5.Maven打包
我们用命令行打开到项目的根目录,输入mvn clean package -DskipTests=true
打包成功后我们到项目目录下的target文件下就会找到相应的jar包
6.提交任务
