一、决策树:转自公众号《数据科学家联盟》
1、决策树
决策树是一个非常有意思的模型,它的建模思路是尽可能模拟人做决策的过程。因此决策树几乎没有任何抽象,完全通过生成决策规则来解决分类和回归问题。因为它的运行机制能很直接地被翻译成人类语言,即使对建模领域完全不了解的非技术人员也能很好地理解它。因此在学术上被归为白盒模型(white box model)。
决策树是一种常见的机器学习算法,它的思想十分朴素,类似于我们平时利用选择做决策的过程。它是类似流程图的结构,其中每个内部节点表示一个测试功能,即类似做出决策的过程(动作),每个叶节点都表示一个类标签,即在计算所有特征之后做出的决定(结果)。标签和分支表示导致这些类标签的功能的连接。从根到叶的路径表示分类规则。比如下面这个“相亲决策树”:
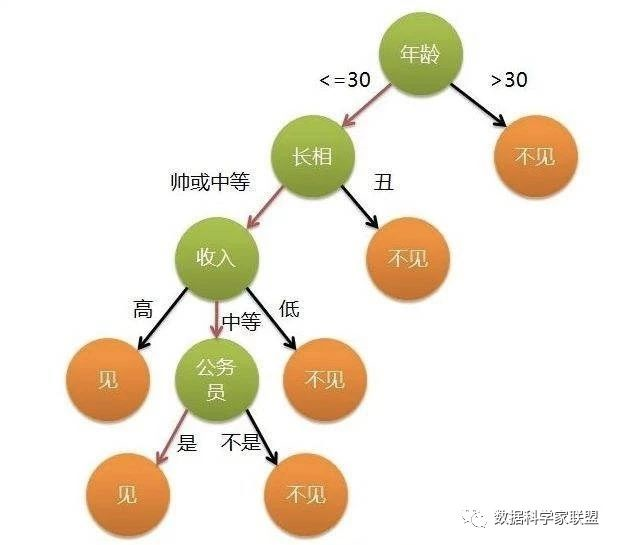
由此我们可以看到,决策树的思想还是非常直观的。
用决策树分类:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归的对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
1.2 决策树与条件概率
在前面已经从直观上了解决策树,及其构造步骤了。现在从统计学的角度对决策树进行定义能够能好地帮助我们理解模型。
决策树表示给定特征条件下,类的条件概率分布,这个条件概率分布表示在特征空间的划分上,将特征空间根据各个特征值不断进行划分,就将特征空间分为了多个不相交的单元,在每个单元定义了一个类的概率分布,这样,这条由根节点到达叶节点的路径就成了一个条件概率分布。
假设X表示特征的随机变量,Y表示类的随机变量,那么这个条件概率可以表示为,其中X取值于给定划分下单元的集合,Y取值于类的集合。各叶结点(单元)上的条件概率往往偏向某一个类。根据输入的测试样本,由路径找到对应单元的各个类的条件概率,并将该输入测试样本分为条件概率最大的一类中,就可以完成对测试样本的分类。
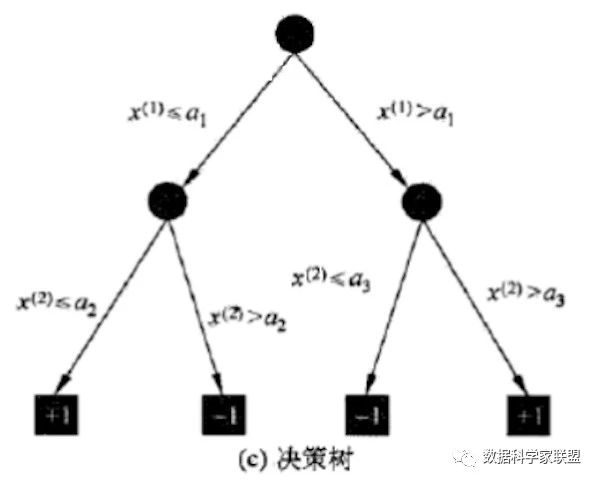
下图a,表示了特种空间的一个划分。大正方形表示特征空间。这个大正方形被若干个小矩形分割,每个小矩形表示一个单元。特征空间划分上的单元构成了一个集合,X取值为单元的集合。假设只有两类正类负类,Y=+1 OR -1;小矩形中的数字表示单元的类。

下图b表示特征空间(图a)划分确定时,特征(划分单元)给定条件下类的条件概率分布。图b中的条件概率分布对应于图a的划分;当某个单元C的条件概率满足 时,即认为该类属于正类,落在该单元的实例都视为正例。
时,即认为该类属于正类,落在该单元的实例都视为正例。

下图c表示了根节点到各个叶子结点上不同划分的条件分布。
学习目标与本质
假设给定训练数据集 ,其中
,其中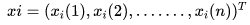 为输入实例(特征向量),n为特征个数,
为输入实例(特征向量),n为特征个数, 为类标记(label),i=1,2,。。。N为样本容量。
为类标记(label),i=1,2,。。。N为样本容量。
学习目标:根据给定的训练数据集构建一个决策模型,使它能够对实例进行正确的分类。
决策树学习本质上是从训练数据集中归纳出一组分类规则。与训练数据集不相矛盾的决策树(即能对训练数据进行正确分类的决策树)可能是0个或多个。我们需要找到一个与训练数据矛盾较小的决策树,同时具有很好的泛化能力。
从另一个角度看,决策树学习是由训练数据集估计条件概率模型。基于特征空间划分的类的条件概率模型有无穷多个。我们选择的条件概率模型应该不仅对训练数据有很好地拟合,而且对未知数据有很好地预测。
决策树损失函数
与其他模型相同,决策树学习用损失函数表示这一目标。决策树学习的损失函数通常是正则化的极大似然函数。决策树学习的策略是以损失函数为目标函数的最小化。
关于极大似然函数:极大似然法是属于数理统计范畴,旨在由果溯因。把“极大似然估计”拆成三个词:极大(最大的概率)、似然(看起来是这个样子的)、估计(就是这个样子的),连起来就是:大概率看起来是这样的,那就是这样。
比如扔一枚骰子(骰子每个面上只标记1或2),现在告诉你扔了n次骰子其中有k次朝上的是1;然后问你这个骰子标记为1的面所占的比例w是多少?极大似然法的思想就是估计当w取值为多少的时候,k次朝上的可能性最大。具体计算方法就是对表达式求最大值,得到参数值估计值:一般就是对这个表达式求一阶导=0(二阶导<0);
这就是极大似然估计方法的原理:用使概率达到最大的那个概率值w来估计真实参数w。决策树生成的过程可以理解成对决策树模型的参数估计(就是基于特征空间划分的类的概率模型),根据训练数据的特征分布,选择使得模型最契合当前样本分布空间时的条件概率模型。
当损失函数确定以后,学习问题就变为在损失函数意义下选择最优决策树的问题。因为从所有可能的决策树中选取最优决策树是NP完全问题,所以现实中决策树学习算法通常采用启发式方法,近似求解这一最优化问题。这样得到的决策树是次最优的。
决策树的构建
决策树通常有三个步骤:
- 特征选择
- 决策树的生成
- 决策树的修剪
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。
这一过程对应着对特征空间的划分,也对应着决策树的构建。
- 开始:构建根节点,将所有训练数据都放在根节点,选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
- 如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶子节点去。
- 如果还有子集不能够被正确的分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的节点,如此递归进行,直至所有训练数据子集被基本正确的分类,或者没有合适的特征为止。
- 每个子集都被分到叶节点上,即都有了明确的类,这样就生成了一颗决策树。
以上方法就是决策树学习中的特征选择和决策树生成,这样生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据却未必有很好的分类能力,即可能发生过拟合现象。我们需要对已生成的树自下而上进行剪枝,将树变得更简单,从而使其具有更好的泛化能力。具体地,就是去掉过于细分的叶结点,使其回退到父结点,甚至更高的结点,然后将父结点或更高的结点改为新的叶结点,从而使得模型有较好的泛化能力。。
决策树生成和决策树剪枝是个相对的过程,决策树生成旨在得到对于当前子数据集最好的分类效果(局部最优),而决策树剪枝则是考虑全局最优,增强泛化能力。
在对此有一定了解之后,我们先看看,如何在sklearn中将决策树用起来。然后再学习其中的细节。
2、信息熵与最优划分
3、基尼系数
4、CART
二、实现:决策树实现