-
将 spark-3.0.0-bin-hadoop3.2.tgz 文件解压缩在指定位置(/opt/module)
tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
-
修改解压后文件名称为spark-standalone
mv spark-3.0.0-bin-hadoop3.2 spark-standalone
-
进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
mv slaves.template slaves
-
修改 slaves 文件,添加虚拟机节点master,s1,s2
-
修改 spark-env.sh.template 文件名为 spark-env.sh
mv spark-env.sh.template spark-env.sh
-
修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
export JAVA_HOME=/root/jdk1.8.0_171 SPARK_MASTER_HOST=master SPARK_MASTER_PORT=7077
-
分发 spark-standalone 目录
xsync spark-standalone
Spark集群启动
-
执行脚本命令:
sbin/start-all.sh
-
查看进程:
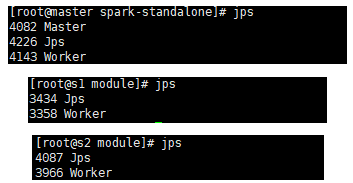
-
查看 Master 资源监控 Web UI 界面:master:8080
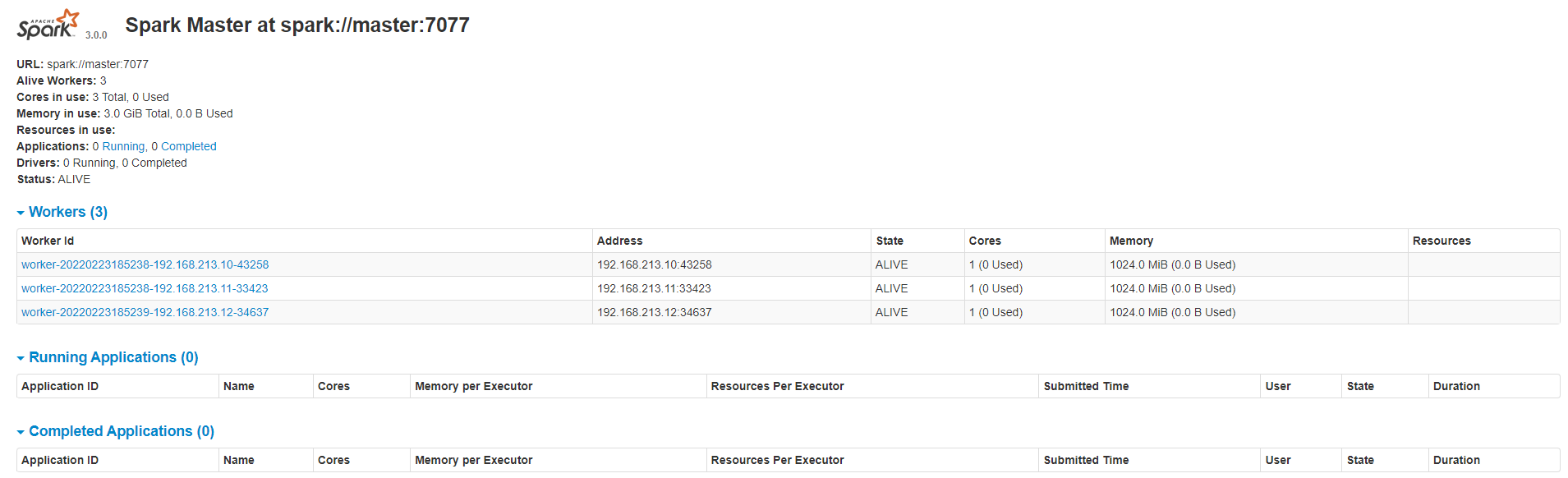
-
提交应用:
bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://master:7077 \ ./examples/jars/spark-examples_2.12-3.0.0.jar \ 10
-
提交参数说明