①导入相关扩展包
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
②获取数据集
iris = load_iris()
③划分数据集
x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=20)
④决策树预估器(estimator)
estimator=DecisionTreeClassifier(criterion="entropy") #criterion默认为'gini'系数,也可选择信息增益熵'entropy' estimator.fit(x_train,y_train) #调用fit()方法进行训练,()内为训练集的特征值与目标值
⑤模型评估
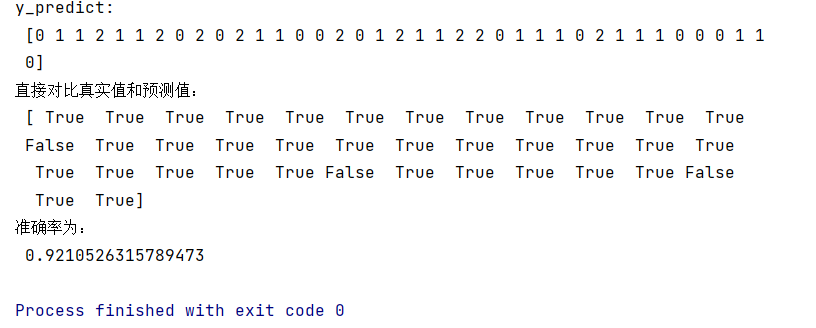
方法一:直接对比测试集的真实值和预测值
y_predict=estimator.predict(x_test) #传入测试集特征值,预测所给测试集的目标值 print("y_predict: ",y_predict) print("直接对比真实值和预测值: ",y_test==y_predict)
方法二:计算准确率
score=estimator.score(x_test,y_test) #传入测试集的特征值和目标值
⑥决策树可视化(将结果写入tree.dot文件中,然后将tree.dot文件中的内容粘贴在webgraphviz.com中进行可视化展示
export_graphviz(estimator, out_file="tree.dot", feature_names=iris.feature_names)
主要代码:
def decision_demo(): # 1.获取数据集 iris = load_iris() # 2.划分数据集 x_train,x_test,y_train,y_test=train_test_split(iris.data,iris.target,random_state=20) # 3.决策树预估器(estimator) estimator=DecisionTreeClassifier(criterion="entropy") #criterion默认为'gini'系数,也可选择信息增益熵'entropy' estimator.fit(x_train,y_train) #调用fit()方法进行训练,()内为训练集的特征值与目标值 # 4.模型评估 #方法一:直接对比真实值和预测值 y_predict=estimator.predict(x_test) #传入测试集特征值,预测所给测试集的目标值 print("y_predict: ",y_predict) print("直接对比真实值和预测值: ",y_test==y_predict) #方法二:计算准确率 score=estimator.score(x_test,y_test) #传入测试集的特征值和目标值 print("准确率为: ",score) #决策树可视化 export_graphviz(estimator,out_file="tree.dot",feature_names=iris.feature_names) return None
代码运行结果:
可视化展示结果:
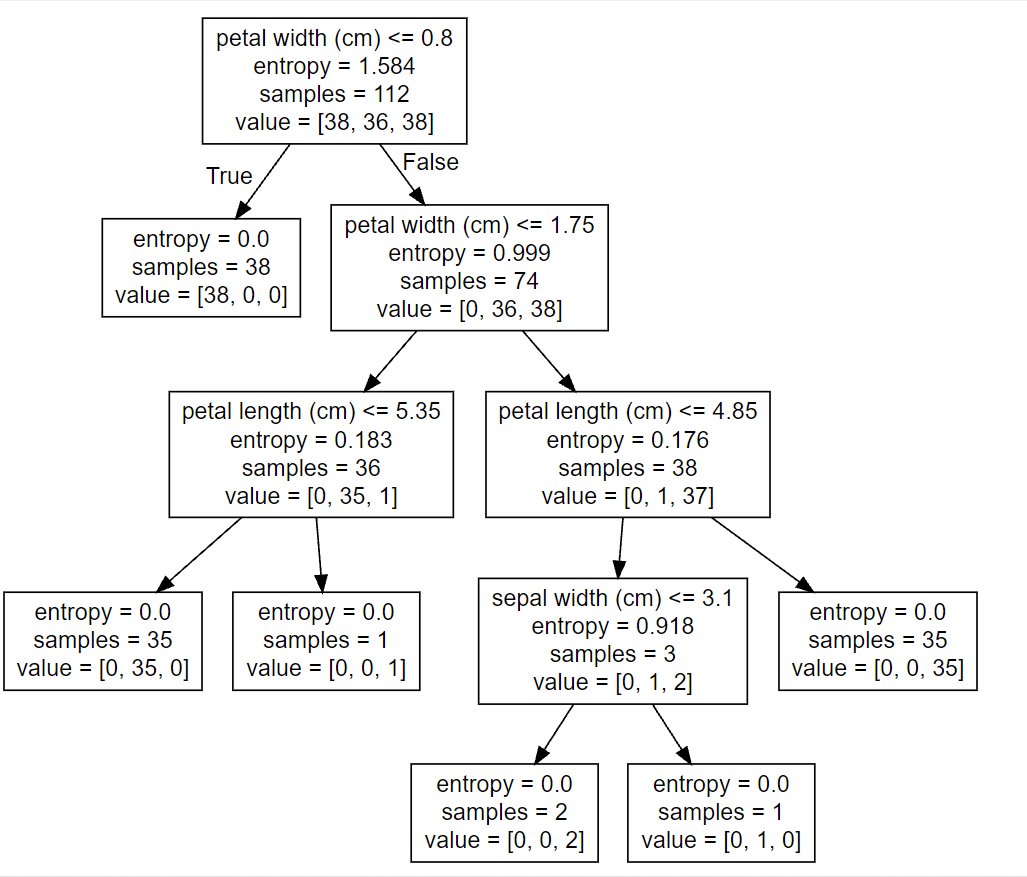
注:可视化展示中,feature_names=iris.feature_names缺省会出现特征值名称缺失现象,如下图所示:
