论文提出了基于注意力的BVR模块,能够融合预测框、中心点和角点三种目标表示方式,并且能够无缝地嵌入到各种目标检测算法中,带来不错的收益
来源:晓飞的算法工程笔记 公众号
论文: RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder

Introduction
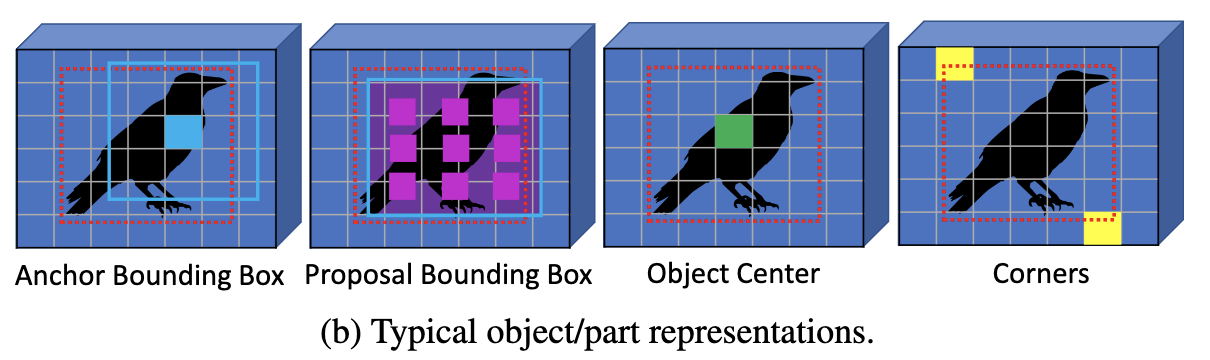
目标检测算法有很多种目标表示方法,如图b所示,有基于矩形框的也有基于关键点的。不同的表示方法使得检测算法在不同的方面表现更优,比如矩形框能更好的对齐标注信息,中心点更利于小目标识别,角点则能够更精细地定位。论文探讨能否将多种表示方式融合到单框架中,最终提出了基于注意力的解码模块BVR(bridging visual representations),该模块与Transformer的注意力机制类似,通过加权其它目标特征来增强当前目标特征,能够融合不同表示方式的异构特征。

以BVR嵌入anchor-based方法为例,如图a所示,表示方式acnhor作为\(query\),其它表示方式中心点和角点作为\(key\),计算\(query\)和\(key\)间关联性权重,基于权重整合\(key\)的特征来增强\(query\)的特征。针对目标检测的场景,论文对权重计算进行了加速,分别为key sampling和shared location embedding,用于减少\(key\)的数量以及权重计算量。除了嵌入到anchor-based方法外,BVR也可嵌入到多种形式的目标检测算法中。
论文的贡献如下:
- 提出通用模块BVR,可融合不同目标表示方式的异构特征,以in-place的方式嵌入到各种检测框架,不破坏原本的检测过程。
- 提出BVR模块的加速方法,key sampling和shared location embedding。
- 经测试,在ReinaNet、Faster R-CNN、FCOS和ATSS四个检测器上有明显的提升。
Bridging Visual Representations

使用不同表示方式的检测算法有不同的检测流程,如图2所示,BVR注意力模块以算法原本的表示方式为主特征,加入其它表示方式作为辅助特征。将主特征\(query\)和辅助特征\(key\)作为输入,注意力模块根据关联性加权辅助特征来增强主特征:

\(f^q_i\),\(f^{'q}_i\),\(g^q_i\)为第\(i\)个\(query\)实例的输入特征,输出特征和几何向量,\(f^k_j\),\(g^k_j\)为第\(j\)个\(key\)实例的输入特征和几何向量,\(T_v(\cdot)\)为线性变化,\(S(\cdot)\)为\(i\)和\(j\)实例间的关联性计算:

\(S^A(f^q_i, f^k_j)\)为外观特征相似度,计算方法为scaled dot product。\(S^G(g^q_i, g^k_j)\)为几何位置相关的项,先将相对的几何向量进行cosine/sine位置embedding,再通过两层MLP计算关联度。由于不同表示方式的几何向量(4-d预测框与2-d点)不同,需从4-d预测框提取对应的2-d点(中心或角点),这样两种不同表示方式的几何向量就对齐了。
在实现时,BVR模块采用了类似multi-head attention的机制,head数量默认为8,即公式1的+号后面改为Concate多个关联特征的计算,每个关联特征的维度为输入特征的1/8。
BVR for RetinaNet

以RetinaNet为例,RetinaNet在特征图的每个位置设置9个anchor,共有\(9\times H\times W\)个预测框,BVR模块将\(C\times 9\times H\times W\)特征图作为输入(\(C\)为特征图维度),生成相同大小的增强特征。如图a所示,BVR使用中心点和角点作为辅助的\(key\)特征,关键点通过轻量级的Point Head网络预测,然后选择少量的点输入到注意力模块中增强分类特征和回归特征。
Auxiliary (key) representation learning
Point Head网络包含两层共享的\(3\times 3\)卷积,然后接两个独立的子网(\(3\times 3\)卷积+sigmoid),预测特征图中每个位置为中心点(或角点)的概率及其相应的偏移值。如果网络包含FPN,则将所有GT的中心点和角点赋予各层进行训练,不需根据GT大小指定层,这样能够获取更多的正样本,加快训练。
Key selection
由于BVR模块使用了角点和中心作为辅助表示方式,特征图的每个位置会输出其为关键点的概率。如果将特征图的每个位置都作为角点和中心点的候选位置,会生成超大的\(key\)集,带来大量的计算消耗。此外,过多的背景候选者也会抑制真正的角点和中心点。为了解决上述问题,论文提出top-k(默认为50)\(key\)选择策略,以角点选择为例,使用stride=1的\(3\times 3\)MaxPool对角点分数图进行转换,选取top-k分数位置进行后续计算。对于包含FPN的网络,则选择所有层的top-k位置,输入BVR模块时不区分层。
Shared relative location embedding
对于每组\(query\)和\(key\),公式2的几何项需要对输入的相对位置进行cosine/sine embedding以及MLP网络转换后再计算关联度。公式2的几何项的几何复杂度和内存复杂度为\(\mathcal{O}(time)=(d_0+d_0d_1+d_1G)KHW\)和\(\mathcal{O}(memory)=(2+d_0+d_1+G)KHW\),\(d_0\),\(d_0\),\(G\),\(K\)分别为cosine/sine embedding维度,MLP网络内层的维度、multi-head attention模块的head数量以及选择的\(key\)数量,计算量和内存占用都很大。

由于几何向量的相对位置范围是有限的,一般都在\([-H+1, H-1]\times [-W+1, W-1]\)范围内,可以预先对每个可能的值进行embedding计算,生成\(G\)维几何图,然后通过双线性采样获得\(key/query\)对的值。为了进一步降低计算量,设定几何图的每个位置代表原图\(U=\frac{1}{2}S\)个像素,\(S\)为FPN层的stride,这样\(400\times 400\)的特征图就可表示\([-100S, 100S)\times [-100S, 100S)\)的原图。计算量和内存消耗也降低为\(\mathcal{O}(time)=(d_0+d_0d_1+d_1G)\cdot 400^2+GKHW\)和\(\mathcal{O}(memory)=(2+d_0+d_1+G)\cdot 400^2+GKHW\)。
Separate BVR modules for classification and regression
目标中心点表示方式可提供丰富目标类别信息,角点表示方式则可促进定位准确率。因此,论文分别使用独立的BVR模块来增强分类和回归特征,如图a所示,中心点用于增强分类特征,角点用于增强回归特征。
BVR for Other Frameworks

论文也在ATSS、FCOS和Faster R-CNN上尝试BVR模块的嵌入,ATSS的接入方式跟RetinaNet一致,FCOS跟RetinaNet也类似,只是将中心点作为\(query\)表示方式,而Faster R-CNN的嵌入如图4所示,使用的是RoI Aligin后的特征,其它也大同小异。
Experiment



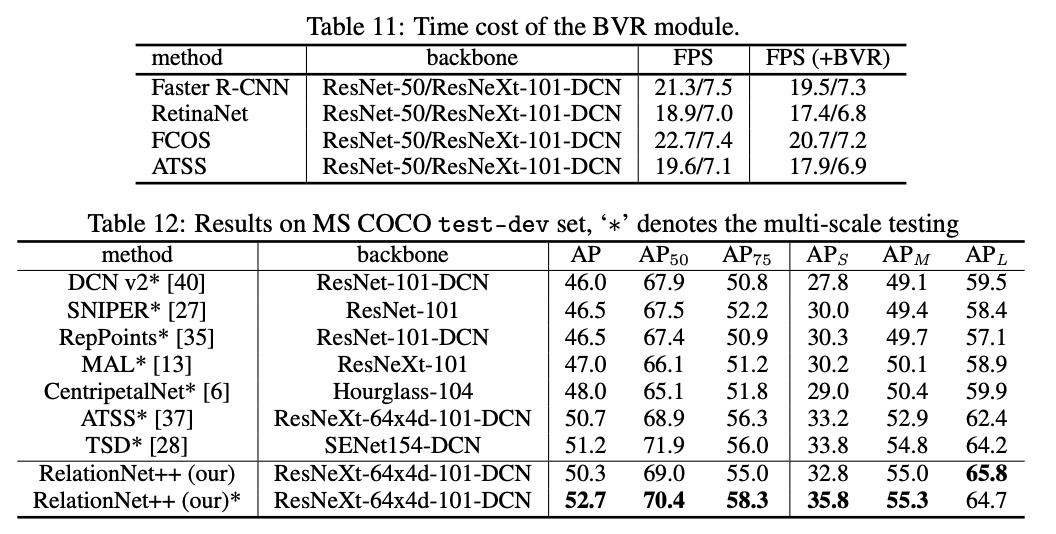
论文进行了充足的对比实验,可到原文看看具体的实验步骤和关键结论。
Conclusion
论文提出了基于注意力的BVR模块,能够融合预测框、中心点和角点三种目标表示方式,并且能够无缝地嵌入到各种目标检测算法中,带来不错的收益。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
