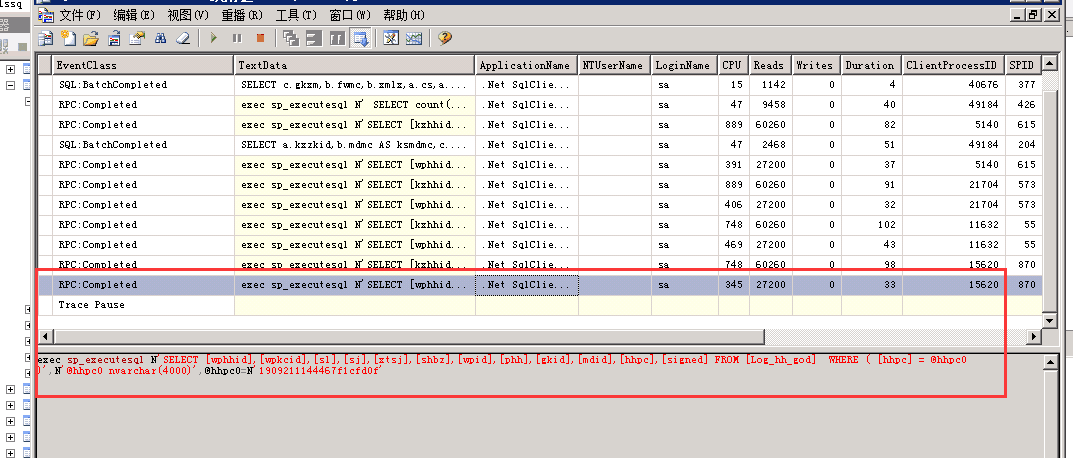
今天SqlServer数据库出现了访问不通的情况,抓紧重启了下服务,让大家先恢复使用,然后我开了 SQL Server Profiler 看看是不是存在性能问题SQL,然后就发现一批这样的SQL,看reads到了6万、2万的级别,这个SQL查询的结果也就几条,这reads明显存在问题
把SQL改写下试试,
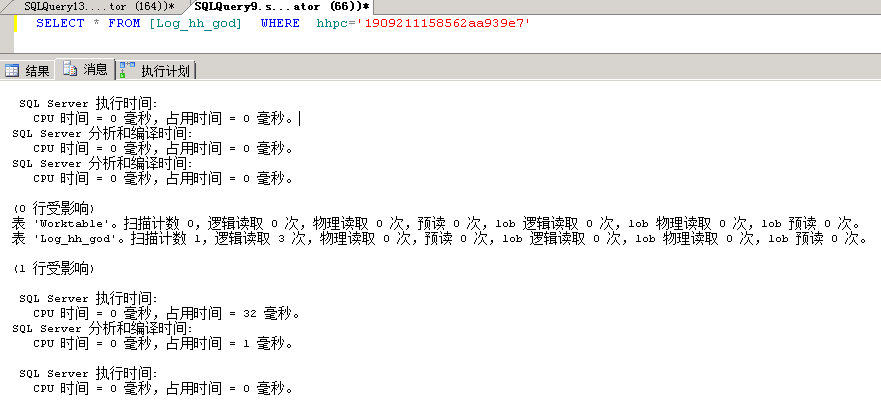
可以看到,SQL很快的,reads在个位数,确认存在问题无疑。
上面自动生成的SQL与改写的SQL对比,可以看到写法最大的区别就是 exec sp_executesql ,初步怀疑是这个引起的问题。
找到代码所在行,上面的SQL是使用的SqlSugar生成的代码
List<Log_hh_god> wpList = _ILog_hh_godRep.FindListByClause(x => x.hhpc == hhpc);
怀疑是不是自动生成的SQL有问题,改成手写的SQL,执行后发现还是不行
List<Log_hh_crd> kxList = _ILog_hh_crdRep.QueryList<Log_hh_crd>("SELECT * FROM [Log_hh_crd] WHERE hhpc=@hhpc ", new { hhpc = hhpc });
然后就是在网上找资料,最终有个回答引起了我的注意,于是我去确认了下Log_hh_crd表中的字段hhpc的类型,是varchar ,而上面自动生成的SQL里面是nvarcahr(4000),会不会是这个区别的问题呢

改了一对比,结果很明显了,就是SQL中的类型与实际类型不一致,导致资源消耗远远超过预期。
试了SqlSugar提供的字段标注功能,有个ColumnDataType,加上试试
[SqlSugar.SugarColumn(ColumnDataType = "varchar(40)")] public string hhpc { get; set; }
结果不行,去翻了下文档,说“自定义生成的数据类型,生成表会用到”,这条路走不通了。。。
只能使用终极办法=======> 修改字段类型!!!
注意
1、如果这个字段存在索引的话,需要先备份索引创建SQL,然后删除索引,再改字段格式,然后再加上索引
2、如果数据量比较大,建议在非业务高峰进行这个操作。