作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
答:MapReduce顾义为大量数据的高效处理,其功能:1)数据划分和计算任务调度:2)数据/代码互定位:3)系统优化:4)出错检测和恢复:
工作原理:
一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的分片(split),这些分片可以被多个Map任务并行处理 Map输出由Reduce处理输出结果,存入分布式文件系统。
工做流程:
Map通常运行在数据存储的结点上,不同的Map任务之间不会进行通信 不同的Reduce任务之间也不会发生任何信息交换, 用户不能显式地从一台机器向另一台机器发送消息 所有的数据交换都是通过MapReduce框架自身去实现的。
HDFS顾名思义为大规模数据的高效存储
其功能为:
1.元数据
Metadata,维护文件和目录信息,分为内存元数据和元数据文件
NameNode主要存储元数据镜像文件Fsimage和日志文件Edits
Fsimage记录某一永久性检查点时整个HDFS的元信息
Edits所有对HDFS的写操作都会记录在此文件
2.检查点
定期对NameNode中的文件进行备份,NameNode启动时会将最新的Fsimage加载到内存中
由secondary namenode完成namenode备份,后者损坏后前者将fsimage拷贝到namenode工作目录,恢复其元数据
触发条件分为两次检查点间隔时间和两次检查点操作数两种
3.DataNode功能
存储管理用户的文件块数据,默认128M/block
定期汇报块信息给namenode,默认3600000ms(1小时一次)
HDFS工作原理:Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的 机器上。它能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。
工作过程:客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本。客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
2)编写map函数和reduce函数,在本地运行测试通过


3)启动Hadoop:HDFS, JobTracker, TaskTracker

4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh

7)source run.sh来执行mapreduce
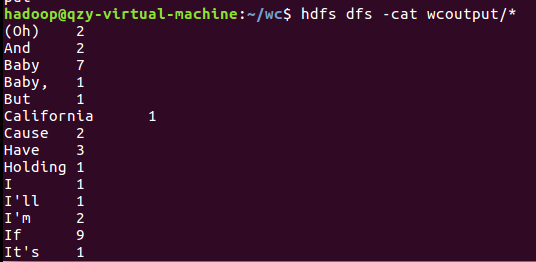
8)查看运行结果