论文:
EESEN:END-TO-END SPEECH RECOGNITION USING DEEP RNN MODELS AND WFST-BASED DECODING
现状:
- 混合DNN仍然GMM为其提供初始化的帧对齐,需要迭代训练强制对齐,以及决策树
- end2end的asr面临问题:
- 如何将发音词典和语言模型更好的融入解码中
- 现有算法模型缺乏共享的实验平台进行基准测试
思想:
网络框架采用多层双向LSTM结构,以CTC作为目标函数,进行end2end的声学模型训练;解码时通过WFST将输出的音素/字符序列、发音和语言模型进行融合,一方面发音、语音模型的融入提升了asr效果;另一方面借助减枝,以及WFST的确定化、最小化等操作,加快的解码速度;该方法取得了与混合DNN可比的WER,3.2倍的解码速度
模型:
- 输入特征:40维fbank+一阶差分+二阶差分=120维
- 模型采用4层Bi-LSTM结构,结点数为320

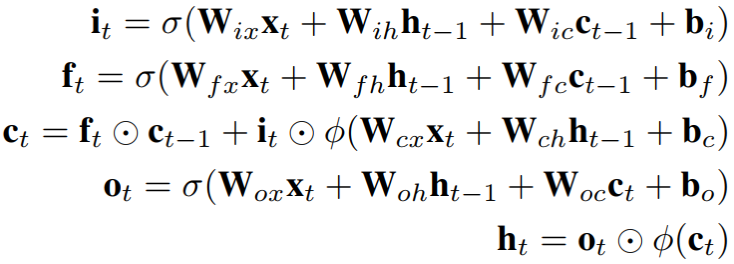
其中,it, ot, ft, ct分别表示输入门、输出门、遗忘门和记忆cell;W.c为对角权重矩阵,这样gate函数向量的m维仅获得来自cell的m维作为输入;σ 为sigmoid激活函数;φ为双正切激活函数tanh
- 目标函数:最大化标签所对应对齐路径的概率和ln Pr(zjX)
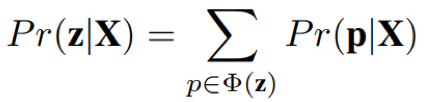
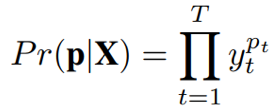

其中,X = (x1,..., xT );对应的标签序列为z = (z1,...., zU),且U<T; yt表示t时刻的音素或字符的后验概率;αt和βt分别代表前向 概率和后向概率;需要注意的是,为了防止因字符连续出现而合并出错的情况,CTC引入blank字符插入到标签序列z的每一个字符的前后,因此标签序列由之前长度U变成2U+1
- 解码:WFST,将音素或字符组成的对齐序列、发音、语言模型通过一系列composition、determinization和 minimization操作组成路径搜索图;一方面将发音和语言模型融入解码过程提升识别效果;另一方面加快解码速度
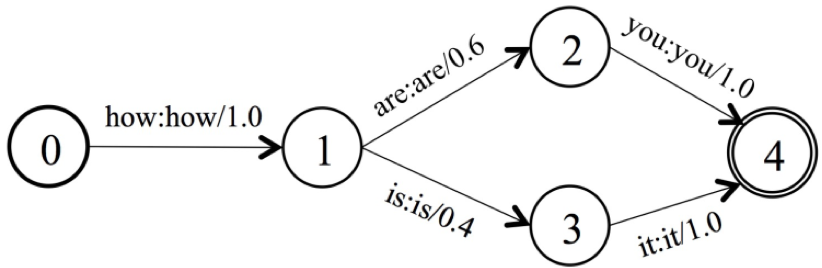
Grammer(G)

phone组成的lexicon(L)
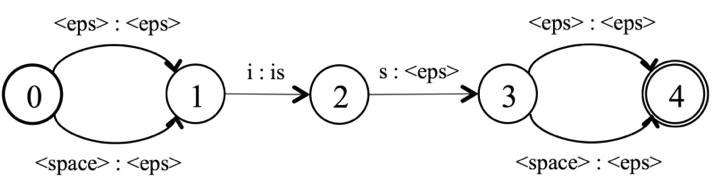
spell组成的lexicon(L)
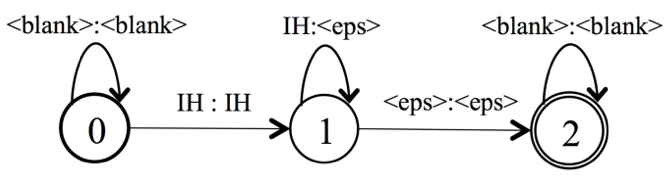
对齐序列T,允许blank、连续重复有效字符

其中, ◦, det and min分别表示复合、确定化和最小化操作
细节:
- 模型参数采用均匀分布[-0.1,0.1]
- 初始学习率设置为0.00004,当验证集连续两个epoch的损失下降低于0.5%时,学习率衰减0.5;当验证集连续两个epoch的损失下降低于0.1%时,停止训练
- CTC训练不能处理具有多发音的词,于是对每个多发音的词仅保留其第一发音或频次出现最多,移除其他发音
- 后验概率归一化
- 训练句子按长度进行排序,将长度相近的句子组成一个batch,并且按最长的句子进行padding;并且可以减少的padding,稳定训练
- 支持GPU并行化训练
- 采用clip gradients,使梯度控制在[-50,50],保持训练的稳定性
实验效果:
- baseline:HMM/DNN混合结构
- 连续的上下文11帧fbank特征作为输入
- 6个隐层,隐层结点1024
- 3421个senones,即输出维度
- 受限波尔滋蔓机进行参数初始化
- CE交叉熵训练
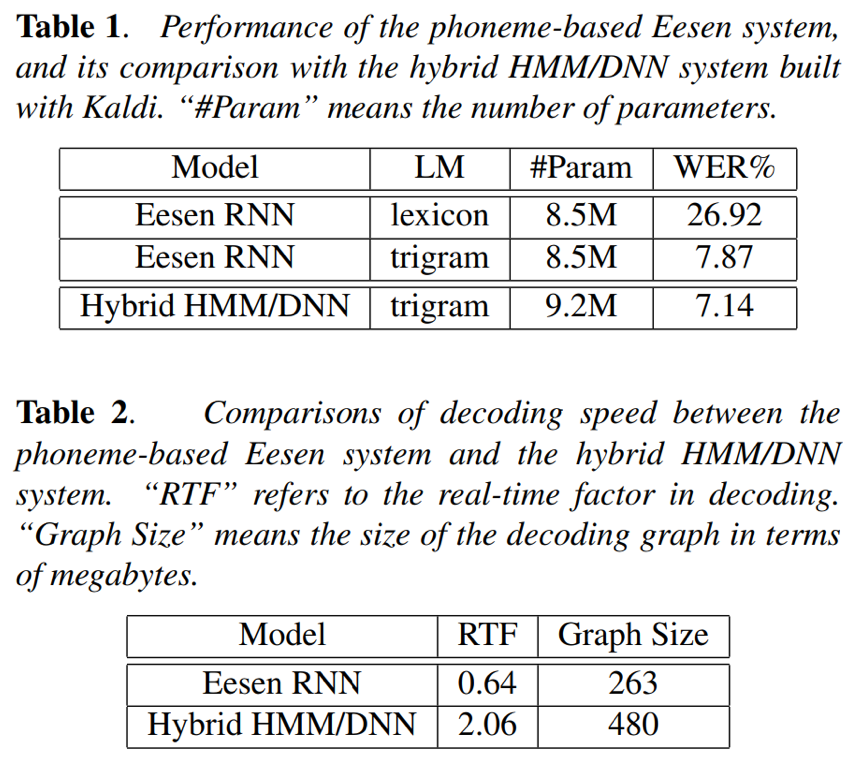
- 音素为建模单元时:
- LER为7.87%略差于HMM/DNN的7.14%;作者分析原因在于,数据集的量,在大数据集上,CTC训练的模型能得到超越HMM/DNN混合系统的实际效果
- 解码速度相对于HMM/DNN混合系统提升3.2倍,原因在于:1)eesen输出单元结点数算上blank只有几十个,但是HMM/DNN有3421个;2)eesen的解码图TLG相对于HMM/DNN的HCLG要小得多
- TLG相对于HMM/DNN的HCLG要小得多,所以占磁盘空间也更小
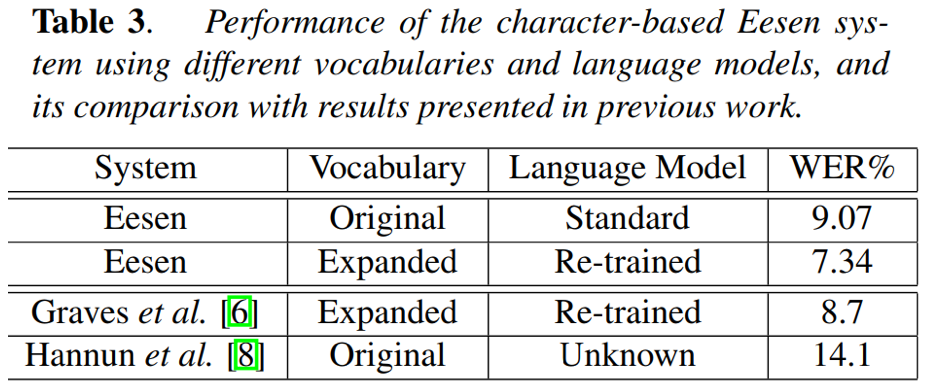
- 字符为建模单元时:LER为9.07%;将训练集中出现的两次以上的集外词OOV加入到词典中,LER降为7.34%
- 语言:C++
- 核心模块:
- 声学模型
- hkust/v1



- tedlium


- CTC
- char
- phone
- WFST解码
- T:字符或音素对齐序列,包括blank
- L:lexicon
- G:语言模型
- 语言模型
- 3-gram
- 4-gram
- RNNLM
- 效果:
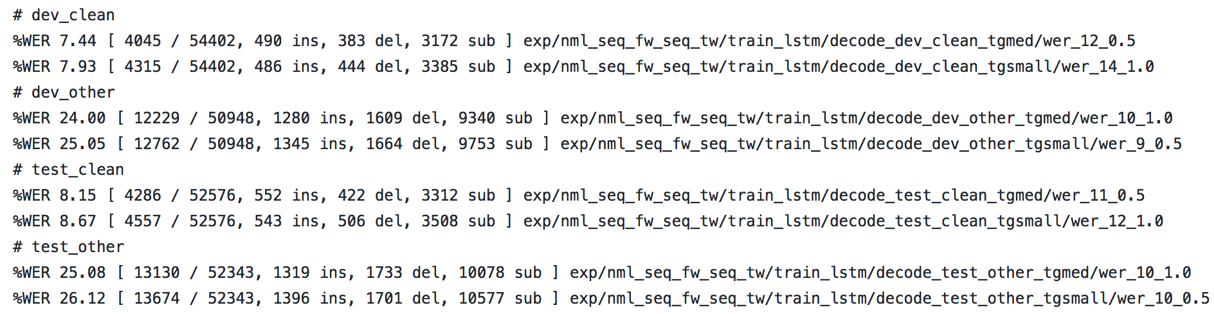
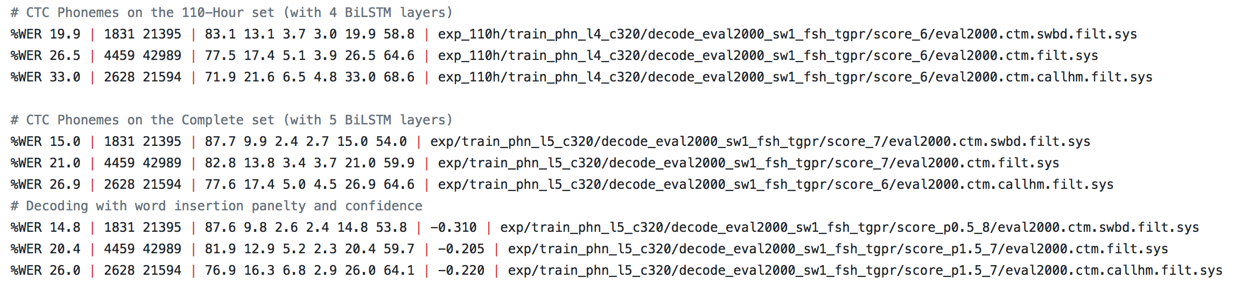
- hkust:

- tedlium

- wsj

Reference: