:
先贴一个代码:
#include<cstdio>
#include<cstring>
using namespace std;
char a[10000009],b[100010];int la,lb,p[100010];
int main()
{
scanf("%s%s",a+1,b+1);la=strlen(a+1);lb=strlen(b+1);
for(int i=2,j=0;i<=lb;i++)
{
while(j&&b[i]!=b[j+1])j=p[j];
if(b[i]==b[j+1])p[i]=++j;
}
for(int i=1,j=0;i<=la;i++)
{
while(j&&a[i]!=b[j+1])j=p[j];
if(a[i]==b[j+1])
{
if(++j==lb){printf("%d %d
",i-j+1,i);return 0;}
}
}
puts("NO");
return 0;
}
正确性证明:
for(int i=2,j=0;i<=lb;i++)
{
while(j&&b[i]!=b[j+1])j=p[j];
if(b[i]==b[j+1])p[i]=++j;
}
第1个循环是对子串的预处理,表示子串的前项前缀与后缀的最大匹配长度.
我们从2开始,是因为我们要保证前缀和后缀的最大匹配长度为整个区间长度.
对于第1个我们先假设~~是正确的,只要我们能保证的求法无误,就可以保证数组的正确性.
为前面的匹配长度.那么那个为什么是正确的呢.
因为,所以前项加上第项不能不能与前缀匹配,那么就必须变小.
因为要保证的变化量最小,并且变化后的能与前缀匹配.
那么就应该变为前缀与后缀的最长匹配长度,即.
那个判断显然是对的,不就不讲了.
我们证明了第1重循环是对的,那么第2重循环是类似的,我就不证明了.
一个小栗子:

应缩小的大小,使得缩小后仍能与子串前缀匹配,那么就应该变为后缀与前缀的最长匹配长度(即)啦.
复杂度证明:
复杂度,为什么呢——其实每重循环都是线性的。
那我就只讲第1重循环吧.
对于每次至少减小1.
而每次只增加1.
所以这个循环的复杂度就是的.
另一个循环的复杂度证明类似.
:
传送门
exKMP可以线性求解最长公共前缀长度.
那么它是怎么实现的呢?——一句话:高度继承前面的判断.
思路:
我们需要预处理出子串以每一个位置开头的前缀与子串前缀的最长公共前缀长度.
设子串为, 长度为, 表示的最长公共前缀长度.
设当前 最大)。
我们需要在线性时间内求出。
而对于的求法,我们需要分类讨论。

注意:上面的图画错了:
由于的定义,我们可以知道(红线),那么可以得到
.
设.
若,如上图,蓝线表示.则根据的定义有:,
否则,如下图。

注意:上面的图画错了:
我们直接暴力拓展,再更新即可。
需要注意的是点可能已经超过了.
我们现在已经完成了串的处理。关于的公共前缀,其实做法类似,这里就不赘述了。
代码:
#include<cstdio>
#include<cstring>
using namespace std;
const int N=1e6+10;
int max(int a,int b){return a>b?a:b;}
char a[N],b[N];
int la,lb,p[N],extend[N];
int main()
{
scanf("%s%s",a+1,b+1);
la=strlen(a+1);lb=strlen(b+1);
p[1]=lb; int x=1,k=2;
while(x<lb&&b[x]==b[x+1])x++;
p[2]=x-1;k=2;
for(int i=3;i<=lb;i++)
{
int L=p[i-k+1],R=k+p[k]-i;
if(L<R)p[i]=L;
else
{
x=max(R,0);
while(x+i<=lb&&b[x+1]==b[x+i])x++;
p[i]=x;k=i;
}
}
x=1;
while(x<=lb&&b[x]==a[x])++x;
extend[1]=x-1;k=1;
for(int i=2;i<=la;i++)
{
int L=p[i-k+1],R=k+extend[k]-i;
if(L<R)extend[i]=L;
else
{
x=max(R,0);
while(x<lb&&b[x+1]==a[x+i])x++;
extend[i]=x;k=i;
}
}
for(int i=1;i<la;i++)printf("%d ",extend[i]);
printf("%d
",extend[la]);
return 0;
}
算法(马拉车)
首先,回文串长度的奇偶会影响求解方法。为了方便,我们在每个字符两边插入一个(其他符号也行)。
显而易见的,这是更方便的。如
求解思路
我们定义一个叫做回文半径的东西,用于表示以一个点为中心的回文串的边界到中心的点的总数,以第个点为中心的回文半径为。
具体来讲,变化后中间的a的回文半径为6,原来中间的a的回文半径为3.
()
可以发现变化后的字符串的最长回文串长度为.
证明:
根据定义可推出以为中心的回文串长度为.
很明显,两端一定是. 并且比字母数多1.
总字母数则为。
以上我们讲解了如何求正确答案,下面介绍如何用最快的方法求.
定义为以该点为中心的回文串右端点最右的点,(细细体会)
在某个时刻,可能是这样的:
case 1:
我们根据回文串的轴对称性质,可以发现当一个点位于区间时 (如第二个b),它可以继承关于的对称点的回文半径(且可以保证第二个b的回文半径不小于第一个b的)
其实只有两种情况:
case 1.1:

注:
注意:
当以为中心的回文串的左端点大于以为中心的回文串的左端点(下面用代替,注意)时,可以保证.
为什么?因为 .根据对称性可知是正确的.(需要自己摸索一下)
case 1.2:
若,如果直接继承,以.
但是右边的世界是不能保证的,所以必须暴力拓展.
case 2:
当不小于,暴力判断即可.
复杂度证明:
这个算法的复杂度为.
为什么?因为主要复杂度在于的拓展,但是的移动次数始终为,所以复杂度为.
代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=22e6+10;
char a[N];
int n,p[N],ans;
void Manacher()
{
n=strlen(a+1);
for(int i=n;i>=1;i--)a[i*2]=a[i],a[i*2-1]='#';
n=n<<1|1;a[n]='#';
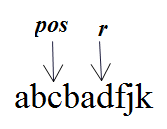
int pos=0,r=0;ans=0;
for(int i=1;i<=n;i++)
{
if(i<r)p[i]=min(p[2*pos-i],r-i);
else p[i]=1;
while(i-p[i]>0&&a[i-p[i]]==a[i+p[i]])p[i]++;
if(i+p[i]>r)pos=i,r=i+p[i],ans=max(ans,p[i]-1);
}
printf("%d
",ans);
}
int main() {
while(~scanf("%s",a+1))Manacher();
return 0;
}
:
字典树
Trie一般指字典树
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
Trie树太简单了 ,我就只给个复杂度吧:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=1e5+10;
int trie[N][26],tot=1,cnt[N];
void ins(char *s) {
int len=strlen(s),p=1;
for(int i=0;i<len;i++) {
char c=s[i]-'a';
if(!trie[p][c])trie[p][c]=++tot;
p=trie[p][c];cnt[p]++;
}
}
int search(char *s) {
int len=strlen(s),p=1;
for(int i=0;i<len;i++) {
p=trie[p][s[i]-'a'];
if(!p)break;
}
return cnt[p];
}
char s[15];
int main() {
int n,m;
scanf("%d",&n);
while(n--)scanf("%s",s),ins(s);
scanf("%d",&m);
while(m--)
scanf("%s",s),printf("%d
",search(s));
return 0;
}
自动机:
前言:
如果你会自动AC机,那还要学AC自动机干什么.
前置芝士:
(学了它们可以更加方便地学习AC自动机)
思路:
考虑暴力:
设模式串有个,分别为,长度为别为
对于一个位置,考虑以结尾有没有出现单词。即:
复杂度非常可观:(复杂度都是估大的)
考虑优化:
其实世上本没有算法,暴力继承的判断多了,也便成了算法。
由上面可以看出如果以一个位置为结尾,这个字符串的后缀没有单词(模版串),这样pd就会很低效。
同时,如果以为结尾的后缀为某些单词的前缀的话,那么就可以直接继承。
现在开始正式学习AC自动机。
一波定义:
学习了树以后,我们设表示编号为x的树节点到根这条路径所代表的字符串。(其实就是某个模版串的前缀。)
若,则表示的非前缀后缀为,并且。(如果找不到y,则y为根(代码中根为1))
举个小栗子:

代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=5e5+10,M=1e6+10;
int trie[N][26],fail[N],ed[N],tot;//相比于Trie树,只多了个fail
int T,n,ans;
char s[M];
void ins() {
int len=strlen(s),p=0;
for(int i=0;i<len;i++) {
char c=s[i]-'a';
if(!trie[p][c])trie[p][c]=++tot;
p=trie[p][c];
}
ed[p]++;
}
int q[N],l,r;
void bfs() {
l=r=1;q[1]=0;
while(l<=r) {
int p=q[l++];
for(int c=0,x,y;c<26;c++) {
if(!trie[p][c])continue;
x=trie[p][c];
if(p) {
y=fail[p];
while( y && !trie[y][c] )y=fail[y];//s[y](上面有定义)每次变化量尽可能小。
fail[x]=trie[y][c];//把根设为0就可以减少特判
}
q[++r]=x;
}
}
}
void search() {
ans=0;
int len=strlen(s),p=0,q;
for(int i=0;i<len;i++) {
char c=s[i]-'a';
while( p && !trie[p][c] )p=fail[p];//AC自动机优秀就在于它能把无用的后缀的前缀砍掉。
p=trie[p][c];q=p;
while(q) {
ans+=ed[q];
ed[q]=0;
q=fail[q];
}
}
printf("%d
",ans);
}
int main() {
scanf("%d",&T);
while(T--) {
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%s",s),ins();
bfs();
scanf("%s",s);search();
tot=(tot+1)<<2;
memset(trie,0,tot*26);
memset(fail,0,tot);
memset(ed ,0,tot);
tot=0;
}
return 0;
}
后缀数组:
定义:
根据定义可以发现:.
后缀排序:
DA(倍增大法):
一句话概括:每个后缀先以第一个字符排序,再以前两个字符排序,再以前四个字符排序……
具体来讲,先求出每个后缀第一个字符的大小(即).按第一个字符排序.
接着,可以发现后缀的第二个字符就是后缀的第一个字符,我们把它当作第二关键字进行排序,并求出每个后缀的前两个字符的相对大小(用离散化求)
第三次,我们拍每个后缀的前4个位置,每个后缀有两个关键字
()).
之后,以此类推……
贴一张罗穗骞大神的图:

代码恶心,需耐心食用。
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=11e5+10;
void write(int x) {
if(x/10)write(x/10);
putchar(x%10+'0');
}
char r[N];
int wa[N],wb[N],wv[N],c[N],sa[N],n,m;
void DA() {
int i,j,p,*x=wa,*y=wb;//只是交换指针比交换数组快得多。
for(i=1;i<=n;i++)++c[x[i]=r[i]];
for(i=2;i<=m;i++)c[i]+=c[i-1];
for(i=n;i>=1;i--)sa[c[x[i]]--]=i;//预处理出单个字符的排位
for(j=1,p=1;p<n;j=j<<1,m=p) {//m=p,表示桶的大小更新
p=0;//y[i]表示第二关键字排名为i的数,第一关键字的位置。
for(i=n-j+1;i<=n;i++)y[++p]=i;//当前处理的是每个后缀的前j*2个字符。[n-j+1,n]的压根没有第二关键字,第一关键字的位置就是自身的位置。
for(i=1;i<=n;i++)if(sa[i]>j)y[++p]=sa[i]-j;//sa在上一重循环已经按当前的第二关键字排序了。从小到大枚举可以保证第二关键字大的在后面。
for(i=1;i<=n;i++)wv[i]=x[y[i]];//wv为第一关键字,x[i]其实存的是[i,i+j-1]的数离散出来的值
for(i=1;i<=m;i++)c[i]=0;//清空桶
for(i=1;i<=n;i++)c[wv[i]]++;
for(i=2;i<=m;i++)c[i]+=c[i-1];
for(i=n;i>=1;i--)sa[c[wv[i]]--]=y[i];//按第一关键字排序
swap(x,y);p=1;x[sa[1]]=1;//把原来的值倒到y,求出新的离散值。
for(i=2;i<=n;i++)//离散化——求出下一次的第一关键字
x[sa[i]]=(y[sa[i-1]]==y[sa[i]]&&y[sa[i-1]+j]==y[sa[i]+j])?p:++p;
//由于&&的短路性质,我们这样写是能够保证不会RE的。(所以我并不能出到令代码RE的数据)
//现在其实是在处理每个后缀的前2*j个位置的离散化任务。当后缀不足2*j长度时,是能够自动补0的。
}
for(i=1;i<=n;i++)write(sa[i]),putchar(' ');
}
int main() {
scanf("%s",r+1);
n=strlen(r+1);m=122;//'z'的ascii码为122
DA();
return 0;
}
不可重叠最长重复子串:
这里要引入数组。
我们可以利用.
引理1:
设k为(排名上)i-1的前一个后缀.


当时,显然.
否则,由上图可以看出后缀k+1与后缀i的最长公共前缀至少为h[i-1]-1.
还有一点需要注意的是.为什么?因为
那么又因为在,与最相似的一定是后缀,
所以可以保证的是(LCP为最长公共前缀)
证毕!
求height:
void calcheight() {
for(int i=1;i<=n;i++)rk[sa[i]]=i;
for(int i=1,k=0,j;i<=n;height[rk[i++]]=k)
for((k?k--:0),j=sa[rk[i]-1];a[i+k]==a[j+k];k++);//i+k由1扫到n——O(n)
}
代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=20010;
int wa[N],wb[N],wv[N],c[N],sa[N],a[N],rk[N],height[N],n,m;
void DA() {
int i,j,p,*x=wa,*y=wb;
for(i=1;i<=m;i++)c[i]=0;
for(i=1;i<=n;i++)c[x[i]=a[i]]++;
for(i=2;i<=m;i++)c[i]+=c[i-1];
for(i=n;i>=1;i--)sa[c[x[i]]--]=i;
for(j=1,p=1;p<n;j=j<<1,m=p) {
for(p=0,i=n-j+1;i<=n;i++)y[++p]=i;
for(i=1;i<=n;i++)if(sa[i]>j)y[++p]=sa[i]-j;
for(i=1;i<=n;i++)wv[i]=x[y[i]];
for(i=1;i<=m;i++)c[i]=0;
for(i=1;i<=n;i++)c[wv[i]]++;
for(i=2;i<=m;i++)c[i]+=c[i-1];
for(i=n;i>=1;i--)sa[c[wv[i]]--]=y[i];
swap(x,y);p=1;x[sa[1]]=1;
for(i=2;i<=n;i++)
x[sa[i]]=(y[sa[i-1]]==y[sa[i]]&&y[sa[i-1]+j]==y[sa[i]+j])?p:++p;
}
}
void calcheight() {
for(int i=1;i<=n;i++)rk[sa[i]]=i;
for(int i=1,k=0,j;i<=n;height[rk[i++]]=k)
for((k?k--:0),j=sa[rk[i]-1];a[i+k]==a[j+k];k++);//i+k由1扫到n——O(n)
}
bool check(int k) {//找两端长度不小于k的相同子串,并且保证子串不相邻
int l,r;l=r=sa[1];
for(int i=2;i<=n;i++) {
if(height[i]<k)l=r=sa[i];
else {
if(sa[i]>r) {
r=sa[i];
if(r-l>k)return 1;
}
else if(sa[i]<l) {
l=sa[i];
if(r-l>k)return 1;
}
}
}
return 0;
}
void solve() {
int l=3,r=n>>1,mid;
while(l<r) {
mid=(l+r+1)>>1;
if(check(mid))l=mid;
else r=mid-1;
}
if(l==3)puts("0");
else printf("%d
",l+1);
}
int main() {
while(scanf("%d",&n),n) {
for(int i=1;i<=n;i++)scanf("%d",&a[i]);
--n;for(int i=1;i<=n;i++)a[i]=a[i+1]-a[i]+100;//允许转调,那么两段数的主题相同,则差分数组中的这两段数(忽略开头位置)相同。
m=200;DA();calcheight();solve();
}
return 0;
}
后缀自动机()
前言:
学这个数据结构,首先需要养好肝。
然后,牺牲花两天的空闲时间。
最后,光荣去世。
正题:
建议阅读这个优秀的,以下仅为个人总结或补充(建议后读或不读)
首先,定义串在原串中的结束位置组成的集合。
例如:原串为“abbab”,s为“ab",则。
我们把相同的子串集定义为等价类。定义.
例如上面的原串,有一个等价类
后缀自动机本质上就是对子串按等价类进行压缩。下面所说的“一个状态”对应一个等价类。
下面给出一些引理:
-
若子串a为b的后缀,则有:。
这个引理显然是成立的。凡是b出现的地方都有a,但有可能a出现的次数更多。同时,,
-
-
对于一个等价类中所有的子串,按长度排序后,则长度连续,且长度较短的为长度较长的子串的后缀。
后缀链接
知道了引理3,可以发现等价类中的子串的长度是连续的,但有时会断开。
即一个等价类的子串的长度集合可能为.
又例如:“abbab”,一个状态的最长子串为"abba",和“abba"同一等价类的有
但是”b”不属于这个等价类,因为.
我们定义“abba”对应的状态的后缀链接指向“b“对应的状态。
如果我们把后缀链接看成一条有向边,则SAM为一棵有根树。
状态集合
对于一个状态,它所能形成的状态构成它的状态集合。
有图有真相

如果我们把状态到新状态看成一条有向边,则SAM为一个DAG(有向无环图)
构造SAM:
模板题
代码:
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int N=250010;
struct node {
int len,link,v[27];
}tr[N<<1];
int n,last,tot,a[N],f[N],r[N<<1],c[N],sa[N<<1];
char s[N];
void ins(int c) {
int p=last,x=last=++tot;tr[x].len=tr[p].len+1;
for( ;p&&!tr[p].v[c];p=tr[p].link)tr[p].v[c]=x;
if(!p)tr[x].link=1;
else {
int q=tr[p].v[c],y;
if(tr[p].len+1==tr[q].len)tr[x].link=q;
else {
tr[y=++tot]=tr[q];//复制一遍
tr[y].len=tr[p].len+1;
tr[q].link=tr[x].link=y;
for( ;p&&tr[p].v[c]==q;p=tr[p].link)tr[p].v[c]=y;
}
}
}
int main() {
last=tot=1;
scanf("%s",s+1);n=strlen(s+1);
for(int i=1;i<=n;i++)ins(a[i]=s[i]-'a');
for(int i=1,p=1;i<=n;i++)r[p=tr[p].v[a[i]]]++;//因为一个子串一定是某个前缀的后缀,所以先给前缀对应的位置打上标记。
for(int i=1;i<=tot;i++)c[tr[i].len]++;
for(int i=2;i<=n;i++)c[i]+=c[i-1];
for(int i=1;i<=tot;i++)sa[c[tr[i].len]--]=i;//基数排序
for(int i=tot;i>=1;i--)r[tr[sa[i]].link]+=r[sa[i]];//给前缀的后缀打上标记
for(int i=1;i<=tot;i++)f[tr[i].len]=max(f[tr[i].len],r[i]);
for(int i=1;i<=n;i++)printf("%d
",f[i]);
return 0;
}