还记得之前介绍过的命名实体识别系列文章吗,可以从句子中提取出人名、地址、公司等实体字段,当时只是简单提到了BERT+CRF模型,BERT已经在上一篇文章中介绍过了,本文将对CRF做一个基本的介绍。本文尽可能不涉及复杂晦涩的数学公式,目的只是快速了解CRF的基本概念以及其在命名实体识别等自然语言处理领域的作用。
什么是CRF?
CRF,全称 Conditional Random Fields,中文名:条件随机场。是给定一组输入序列的条件下,另一组输出序列的条件概率分布模型。
什么时候可以用CRF?
当输出序列的每一个位置的状态,需要考虑到相邻位置的状态的时候。举两个例子:
1、假设有一堆小明日常生活的照片,可能的状态有吃饭、洗澡、刷牙等,大部分情况,我们是能够识别出小明的状态的,但是如果你看到一张小明露出牙齿的照片,在没有相邻的小明的状态为条件的情况下,是很难判断他是在吃饭还是刷牙的。这时,就可以用crf。
2、假设有一句话,这里假设是英文,我们要判断每个词的词性,那么对于一些词来说,如果不知道相邻词的词性的情况下,是很难准确判断每个词的词性的。这时,也可以用crf。
什么是随机场?
我们先来说什么是随机场。
The collection of random variables is called a stochastic process.A stochastic process that is indexed by a spatial variable is called a random field.
随机变量的集合称为随机过程。由一个空间变量索引的随机过程,称为随机场。
也就是说,一组随机变量按照某种概率分布随机赋值到某个空间的一组位置上时,这些赋予了随机变量的位置就是一个随机场。比如上面的例子中,小明的一系列照片分别是什么状态组成了一组位置,我们从一组随机变量{吃饭、洗澡、刷牙}中取值,随机变量遵循某种概率分布,随机赋给一组照片的某一张的输出位置,并完成这组照片的所有输出位置的状态赋值后,这些状态和所在的位置全体称为随机场。
为什么叫条件随机场?
回答这个问题需要先来看看什么是马尔可夫随机场(也叫马尔可夫网络),如果一个位置的赋值只和与它相邻的位置的值有关,与和它不相邻的位置的值无关,那么这个随机场就是一个马尔可夫随机场。这个假设用在小明和词性标注的例子中的话就是我们是通过前一张照片或者后一张照片的状态来判断当前照片的状态是刷牙还是吃饭,我们是根据前一个词的词性或者后一个词的词性来判断当前词的词性是什么。
然而,无论是照片还是词性的判断,如果仅仅通过相邻的照片或词性来判断当前照片或词的状态还是过于草率了,如果还能加入对照片中的内容或词的含义的参考,最后的判断当然会更准确啦。
而条件随机场(CRF),就是给定了一组观测状态(照片可能的状态/可能出现的词)下的马尔可夫随机场。也就是说CRF考虑到了观测状态这个先验条件,这也是条件随机场中的条件一词的含义。
CRF的数学描述
设X与Y是随机变量,P(Y|X)是给定X时Y的条件概率分布,若随机变量Y构成的是一个马尔科夫随机场,则称条件概率分布P(Y|X)是条件随机场。在实际的应用中,比如上面的两个例子,我们一般都要求X和Y有相同的结构,如下:
X=(X1,X2,...Xn),Y=(Y1,Y2,...Yn)
比如词性标注,我们要求输出的词性序列和输入的句子中的每个词是一一对应的。
X和Y有相同的结构的CRF就构成了线性链条件随机场(Linear chain Conditional Random Fields,简称 linear-CRF)。
上面的例子中没有提到命名实体识别,但其实命名实体识别的原理和上面的例子是一样的,也是用到了linear-CRF,后面会提到。
CRF如何提取特征?
CRF中有两类特征函数,分别是状态特征和转移特征,状态特征用当前节点(某个输出位置可能的状态中的某个状态称为一个节点)的状态分数表示,转移特征用上一个节点到当前节点的转移分数表示。其损失函数定义如下:
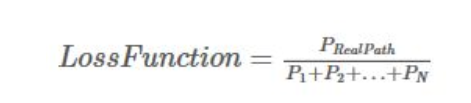
CRF损失函数的计算,需要用到真实路径分数(包括状态分数和转移分数),其他所有可能的路径的分数(包括状态分数和转移分数)。这里的路径用词性来举例就是一句话对应的词性序列,真实路径表示真实的词性序列,其他可能的路径表示其他的词性序列。
这里的分数就是指softmax之前的概率,或称为未规范化的概率。softmax的作用就是将一组数值转换成一组0-1之间的数值,这些数值的和为1,这样就可以表示概率了。
对于词性标注来说,给定一句话和其对应的词性序列,那么其似然性的计算公式(CRF的参数化公式)如下,图片出自条件随机场CRF:
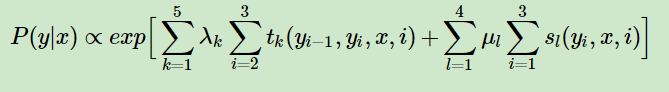
- l表示某个词上定义的状态特征的个数,k表示转移特征的个数,i表示词在句子中的位置。
- tk和sl分别是转移特征函数和状态特征函数。
- λk和μl分别是转移特征函数和状态特征函数的权重系数,通过最大似然估计可以得到。
- 上面提到的状态分数和转移分数都是非规范化的对数概率,所以概率计算都是加法,这里加上一个exp是为了将对数概率转为正常概率。实际计算时还会除以一个规范化因子Z(x),其实就是一个softmax过程。
在只有CRF的情况下,上面说的2类特征函数都是人工设定好的。通俗的说就是人工设定了观测序列的特征。
人为设定状态特征模板,比如设定“某个词是名词”等。
人为设定转移特征模板,比如设定“某个词是名词时,上一个词是形容词”等。
给定一句话的时候,就根据上面设定的特征模板来计算这句话的特征分数,计算的时候,如果这句话符合特征模板中的特征规则,则那个特征规则的值就为1,否则就为0。
实体识别的表现取决于2种特征模板设定的好坏。
所以如果我们能使用深度神经网络的方式,特征就可以由模型自己学习得到,这就是使用BERT+CRF的原因。
命名实体识别中的BERT和CRF是怎么配合的?
由BERT学习序列的状态特征,从而得到一个状态分数,该分数直接输入到CRF层,省去了人工设置状态特征模板。
这里的状态特征是说序列某个位置可能对应的状态(命名实体识别中是指实体标注),
状态分数是每个可能的状态的softmax前的概率(又称非规范化概率,或者直接称作分数),
实体标注通常用BIO标注,B表示词的开始,I表示词的延续,O表示非实体词,比如下面的句子和其对应的实体标注(假设我们要识别的是人名和地点):
小 明 爱 北 京 的 天 安 门 。
B-Person I-Person O B-Location I-Location O B-Location I-Location I-Location O
也就是说BERT层学到了句子中每个字符最可能对应的实体标注是什么,这个过程是考虑到了每个字符左边和右边的上下文信息的,但是输出的最大分数对应的实体标注依然可能有误,不会100%正确的,出现B后面直接跟着B,后者标注以I开头了,都是有可能的,而降低这些明显不符规则的问题的情况的发生概率,就可以进一步提高BERT模型预测的准确性。此时就有人想到用CRF来解决这个问题。
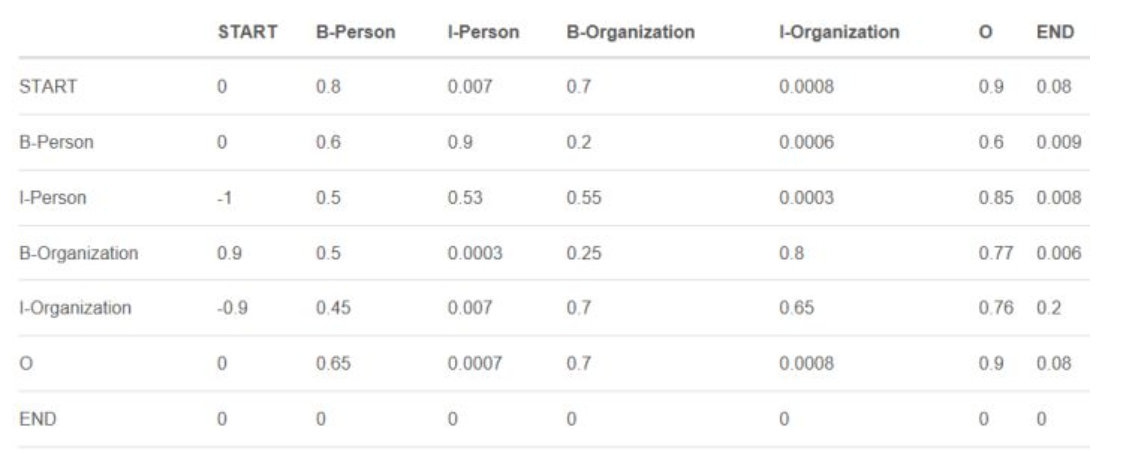
CRF算法中涉及到2种特征函数,一个是状态特征函数,计算状态分数,一个是转移特征函数,计算转移分数。前者只针对当前位置的字符可以被转换成哪些实体标注,后者关注的是当前位置和其相邻位置的字符可以有哪些实体标注的组合。BERT层已经将状态分数输出到CRF层了,所以CRF层还需要学习一个转移分数矩阵,该矩阵表示了所有标注状态之间的组合,比如我们这里有B-Person I-Person B-Location I-Location O 共5种状态,有时候还会在句子的开始和结束各加一个START 和 END标注,表示一个句子的开始和结束,那么此时就是7种状态了,那么2个状态(包括自己和自己)之间的组合就有7*7=49种,上面说的转移分数矩阵中的元素就是这49种组合的分数(或称作非规范化概率),表示了各个组合的可能性。这个矩阵一开始是随机初始化的,通过训练后慢慢会知道哪些组合更符合规则,哪些更不符合规则。从而为模型的预测带来类似如下的约束:
- 句子的开头应该是“B-”或“O”,而不是“I-”。
- “B-label1 I-label2 I-label3…”,在该模式中,类别1,2,3应该是同一种实体类别。比如,“B-Person I-Person” 是正确的,而“B-Person I-Organization”则是错误的。
- “O I-label”是错误的,命名实体的开头应该是“B-”而不是“I-”。
矩阵示意如下:
为什么不能通过人工来判断标注规则并编写好修正逻辑呢?
因为人工虽然能判断出预测的标注前后关系是否符合规则,但是无法知道如何对不符合规则的预测进行调整,比如我们知道句子的开头应该是“B-”或“O”,而不是“I-”,但是究竟是B-还是O呢?而且对于标注状态非常多的场景下,人工编写的工作量和逻辑是非常大且复杂的。
CRF损失函数的计算,需要用到真实路径分数(包括状态分数和转移分数),其他所有可能的路径的分数(包括状态分数和转移分数)。其中真实路径的状态分数是根据训练得到的BERT模型的输出计算出来的,转移分数是从CRF层提供的转移分数矩阵得到的。其他路径的状态分数和转移分数其实也是这样计算的。
其中真实路径的计算原理,其实是使用了维特比算法,关于维特比算法,这篇维特比算法在CRF(条件随机场)中是如何起作用的?中有具体介绍。
总结
命名实体识别中,BERT负责学习输入句子中每个字和符号到对应的实体标签的规律,而CRF负责学习相邻实体标签之间的转移规则。
ok,本篇就这么多内容啦~,感谢阅读O(∩_∩)O。