上篇文章hadoop之mapreduce详解(基础篇)我们了解了mapreduce的执行过程和shuffle过程,本篇文章主要从mapreduce的组件和输入输出方面进行阐述。
一、mapreduce作业控制模块以及其他功能
mapreduce包括作业控制模块,编程模型,数据处理引擎。这里我们重点阐述作业控制模块MRAppMaster。
1.1、MRAppMaster的构成
MRAppMaster主要有如下几个组件构成,如下图所示:
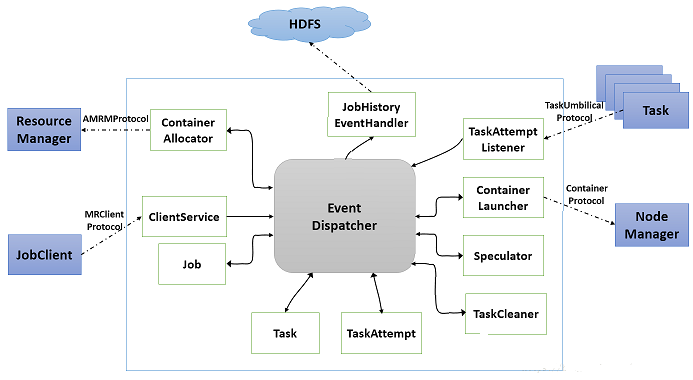
1、ContainerAllocator:与resourcemanager通信,为mapreduce申请资源,作业的所需资源描述为<priority,hostname,capability,containers,relax_locality>5元组格式,分别表示作业的优先级,期望资源所在的节点,资源量,container数目,是否松弛本地性。ContainerAllocator周期性的通过RPC与resourcemanager通信,而resourcemanager则通过心跳应答的方式为之返回所需的container列表,完成的container列表等信息。
ContainerAllocator工作流程:
步骤1:将Map Task的资源需求发送给RM;
步骤2:如果达到了Reduce Task的调度条件,则开始为Reduce Task申请资源;
步骤3:如果为某个Task申请到了资源,则取消其他重复资源的申请。由于在HDFS中,任何一份数据通常有三个备份,而对于一个任务而言,考虑到rack和any级别的本地性,它可能会对应7个资源请求
步骤4:如果任务运行失败,则会重新为该任务申请资源;
步骤5:如果一个任务运行速度过慢,则会为其额外申请资源以启动备份任务(如果启动了推测执行功能);
步骤6:如果一个节点失败的任务数目过多,则会撤销对该节点的所有资源的申请请求
2、ClientServer:实现了MRClientprotocol协议,客户端可以通过该协议获取到作业的执行状态(不需要通过resourcemanager)和控制作业(比如杀死作业,改变作业的优先级等)
3、Job:是一个mapreduce作业,负责监控作业的运行状态,维护一个作业的状态机,实现异步执行各种作业的相关操作
4、Task:一个mapreduce作业中一个任务,负责监控一个任务的运行状态,维护一个任务的状态机,实现异步执行各种任务的相关操作。
5、TaskAttempt:表示一个运行实例
6、TaskCleaner:负责清理失败任务或者杀死任务使用的目录和产生的临时结果,维护一个线程池和一个共享队列,异步删除任务产生的垃圾数据
7、Speculator:完成推测执行功能,当一个任务在执行速度上明显慢于其他任务的时候,Speculator将会启动一个功能相同的任务,先执行完成的任务会kill掉没执行完的那个作业。
8、ContainerLauncher:负责与NodeManager通信,以启动container
9、TaskAttempListener:负责各个任务的心跳信息,如果一个任务一段时间内未汇报心跳信息,则认为该任务死掉了,会将其从系统中移除。
10、JobHistoryEventHandler:负责各个作业的事件记录日志,比如作业的创建,运行等,都会写入hdfs的指定目录下,对作业的恢复很有用。
1.2、mapreduce客户端
是用户和yarn通信的唯一途径,通过该客户端,用户可以向yarn提交作业,获取作业的运行状态,以及控制作业(杀死作业或者任务),该客户端设计到两个通信协议:
ApplicationClientProtocol:resourcemanager实现了该协议,客户端需要通过该协议提交作业,杀死作业,改变作业的优先级等操作
MRClientProtocol:当作业启动Application Master后,会启动MRClientServer服务,该服务实现了MRClientProtocol协议,从而允许用户直接通过该协议直接与Application Master通信,获取作业的执行状态和控制作业,减轻resourcemanager的压力。
1.3、MRAppMaster工作流程
作业的运行分为local模式,yarn的uber模式和yarn的非uber模式:
首先看local模式和yarn模式的选择:客户端通过JobClient提交作业时,会通过java标准库中的Serverloader动态加载所有的ClientProtocolProvider的实现。默认情况下有两种实现:LocalClientProcotolProvider和YarnClientProcotolProvider。如果在配置中参数mapreduce.framework.mode设置为yarn时,客户端则会采用YarnClientProcotolProvider,创建一个YarnRunner对象作为真正的客户端,这样就可以通过YarnRunner.submitJob方法提交给yarn作业了。在该方法的内部实现会进一步调用ApplicationClientProcotol的submitApplication方法,提交作业给Resourcemanager。源码详情可见:hadoop2.7之作业提交详解(上)
uber模式和非uber模式的选择:
uber模式是小作业的一个优化,MrAppMaster不会再为每一个任务申请资源,而是让其重用一个container,map和reduce会在同一份资源上串行执行。
uber模式条件:
mapreduce.job.ubertask.enable #是否启用uber模式
mapreduce.job.ubertask.maxmaps #ubertask的最大map数 (默认9)
mapreduce.job.ubertask.maxreduces #ubertask的最大reduce数 (默认1)
mapreduce.job.ubertask.maxbytes #ubertask最大作业大小 (默认为block.size)
map和reduce使用的资源不得超过MRAppMaster可使用的资源
满足如上条件则使用yarn的uber模式执行, 否则为非uber模式执行
在yarn上运行mapreduce作业需要解决两个问题:
1、reduce作业啥时候启动比较合适
由参数mapreduce.job.reduce.slowstart.completedmaps控制,表示当Map Task完成的比例达到该值后才会为Reduce Task申请资源,默认是0.05;
2、怎样完成shuffle过程
当用户向YARN中提交一个MapReduce应用程序后,YARN将分两个阶段运行该应用程序:
第一个阶段是由ResourceManager启动MRAppMaster;
第二个阶段是由MRAppMaster创建应用程序,为它申请资源,并监控它的整个运行过程,直到运行完成。
具体的运行流程图如下:
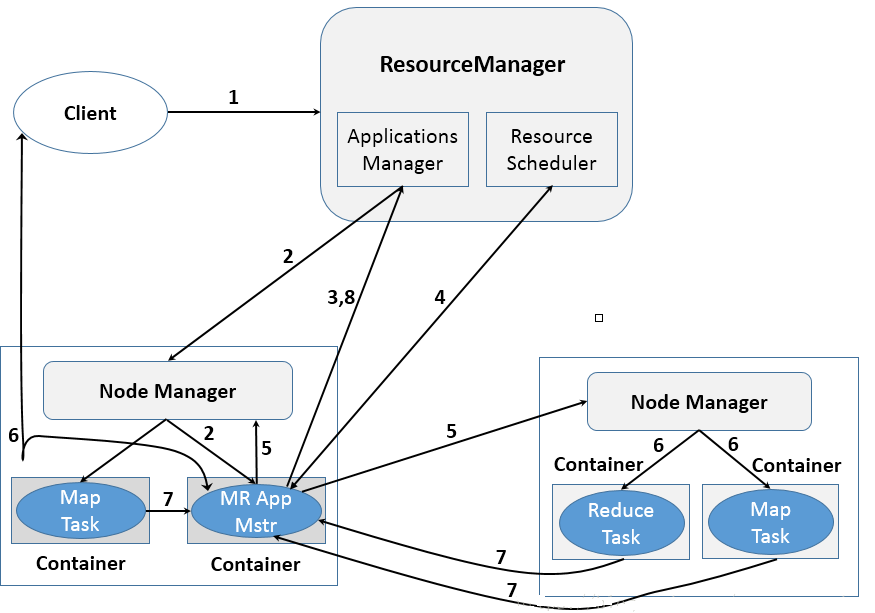
步骤1:用户向YARN中提交应用程序,其中包括MRAppMaster程序、启动MRAppMaster的命令、用户程序等;
步骤2:ResourceManager为该应用程序分配第一个Container,并与对应的NodeManager通信,要求它在这个Container中启动应用程序的MRAppMaster;
步骤3:MRAppMaster启动后,首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,之后,它将为内部任务申请资源,并监控它们的运行状态,直到运行结束,即重复步骤4~7;
步骤4:MRAppMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源;
步骤5:一旦MRAppMaster申请到资源后,则与对应的NodeManager通信,要求它启动任务;
步骤6:NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务;
步骤7:各个任务通过RPC协议向MRAppMaster汇报自己的状态和进度,以让MRAppMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
步骤8:应用程序运行完成后,MRAppMaster向ResourceManager注销并关闭自己
1.4、推测执行
在分布式集群环境下,因软件Bug、负载不均衡或者资源分布不均等原因,造成同一个作业的多个任务之间运行速度不一致,有的任务运行速度明显慢于其他任务(比如某个时刻,一个作业的某个任务进度只有10%,而其他所有Task已经运行完毕),则这些任务将拖慢作业的整体执行进度。为了避免这种情况发生,运用推测执行(Speculative Execution)机制,Hadoop会为该任务启动一个备份任务,让该备份任务与原始任务同时处理一份数据,谁先运行完成,则将谁的结果作为最终结果。
推测执行算法的核心思想是:某一时刻,判断一个任务是否拖后腿或者是否是值得为其启动备份任务,采用的方法为,先假设为其启动一个备份任务,则可估算出备份任务的完成时间estimatedEndTime2;同样地,如果按照此刻该任务的计算速度,可估算出该任务最有可能的完成时间estimatedEndTime1,这样estimatedEndTime1与estimatedEndTime2之差越大,表明为该任务启动备份任务的价值越大,则倾向于为这样的任务启动备份任务。
这种算法的最大优点是,可最大化备份任务的有效率,其中有效率是有效备份任务数与所有备份任务数的比值,有效备份任务是指完成时间早于原始任务完成时间的备份任务(即带来实际收益的备份任务)。备份任务的有效率越高、推测执行算法就越优秀,带来的收益也就越大。
推测执行机制实际上采用了经典的算法优化方法:以空间换时间,它同时启动多个相同任务处理同一份数据,并让这些任务竞争以缩短数据处理时间,显然这种方法需要占用更多的计算资源,在集群资源紧缺的情况下,应合理使用该机制,争取在多用少量资源情况下,减少大作业的计算时间。
参数控制:
mapreduce.map.speculative
mapreduce.reduce.speculative
二、mapreduce输入输出格式
2.1、输入格式
2.1.1、分片
在FileInputFormat中,分片计算源码详见:hadoop2.7作业提交详解之文件分片
计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize))
minSize的默认值是1,而maxSize的默认值是long类型的最大值,即可得切片的默认大小是blockSize(128M)
maxSize参数如果调得比blocksize小,则会让切片变小,而且就等于配置的这个参数的值
minSize参数调的比blockSize大,则可以让切片变得比blocksize还大
hadoop为每个分片构建一个map任务,可以并行处理多个分片上的数据,整个数据的处理过程将得到很好的负载均衡,因为一台性能较强的计算机能处理更多的数据分片,分片也不能切得太小,否则多个map和reduce间数据的传输时间,管理分片,构建多个map任务的时间将决定整个作业的执行时间.(大部分时间都不在计算上)如果文件大小小于128M,则该文件不会被切片,不管文件多小都会是一个单独的切片,交给一个maptask处理.如果有大量的小文件,将导致产生大量的maptask,大大降低集群性能.
注意:分片本身不包含数据本身,而是指向数据的引用,存储位置供mapreduce系统使用以便使得map任务尽量数据本地化,而分片的大小用来排序,以便优先处理大的分片,
从而做小化作业执行时间。
2.1.2、小文件处理
小文件不仅会增加NameNode的存储压力,还会增加运行作业时的寻址次数,也会造成map的大批量增加,所以处理小文件是必要的。
1、 在数据处理的前端就将小文件整合成大文件,再上传到hdfs上,即避免了hdfs不适合存储小文件的缺点,又避免了后期使用mapreduce处理大量小文件的问题。(最提倡的做法)
2、小文件已经存在hdfs上了,可以使用另一种inputformat来做切片(CombineFileInputFormat),它的切片逻辑和FileInputFormat(默认)不同,它可以将多个小文件在逻辑上规划到一个切片上,交给一个maptask处理。
2.1.3、如何避免切片
1、动态调整blocksize
2、重写isSplitable()方法,返回false
2.1.4、文本行整条数据分片存储
文本行一行记录是否会被切分存放在两个分片上,又如何保证数据不丢失和数据不重复。
事实上,Hadoop对这种某一行跨两个分片的情况进行了特殊的处理。
通常Hadoop使用的InputSplit是FileSplit,一个FileSplit主要存储了三个信息<path, start, 分片length>。假设根据设置分片大小为100,那么一个250字节大小的文件切分之后,我们会得到如下的FileSplit:
<path, 0, 100>
<path, 100, 100>
<path, 200, 50>
(具体的切分算法可以参考FileInputFormat的实现)
因此,事实上,每个MapReduce程序得到的只是类似<path, 0, 100>的信息。当MapReduce程序开始执行时,会根据path构建一个FSDataInputStream,定位到start,然后开始读取数据。在处理一个FileSplit的最后一行时,当读取到一个FileSplit的最后一个字符时,如果不是换行符,那么会继续读取下一个FileSplit的内容,直到读取到下一个FileSplit的第一个换行符。这样子就保证我们不会得到一个不完整的行了。
那么当MapReduce在处理下一个FileSplit的时候,怎么知道上一个FileSplit有没有已经处理了这个FileSplit的第一行内容?
我们只需要检查一下前一个FileSplit的最后一个字符是不是换行符,如果是,那么当前Split的第一行还没有被处理,如果不是,表示当前Split的第一行已经被处理,我们应该跳过。
在LineRecordReader中,使用了一个很巧妙的方法来实现上述的逻辑,把当前FileSplit的start减一,然后跳过第一行(下面是这个代码片断)
}else{ if(start!= 0) { skipFirstLine =true; --start; fileIn.seek(start); } in=newLineReader(fileIn, job, recordDelimiter); } if(skipFirstLine) {// skip first line and re-establish "start". start+=in.readLine(newText(), 0, (int)Math.min((long)Integer.MAX_VALUE,end-start)); }
2.1.5、常用的输入格式
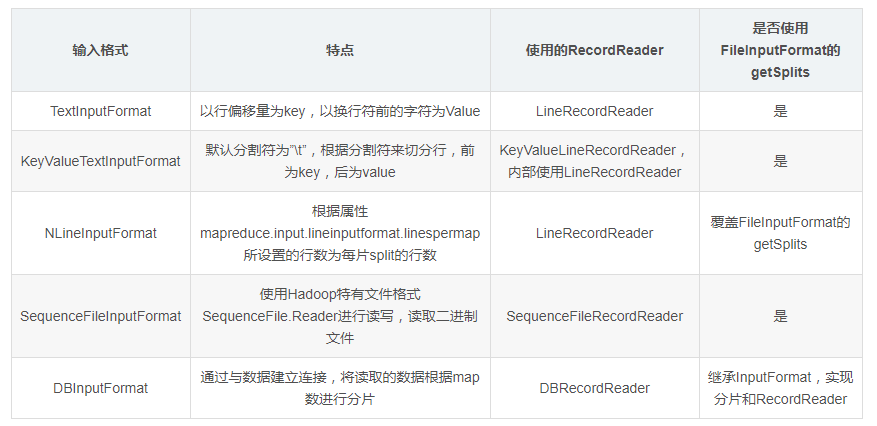
FileInputFormat是所有使用文件作为其数据源的InputFormat的基类,其提供了两个功能,一个是指出作业的输入文件位置,一个是为输入文件生成分片的代码实现。把分片分割成记录的实现由其子类完成,FileInputFormat层次结构图如下: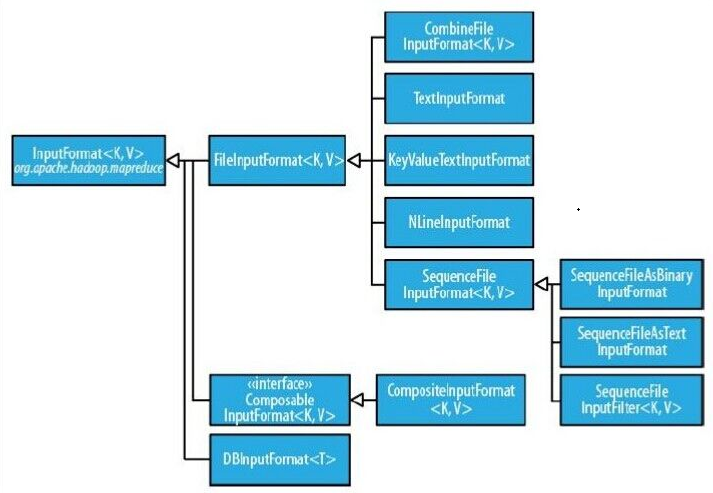
2.2、输出格式
针对上一节的输入格式,都会有相对应的输入格式,OutputFormat层次结构图如下:

常用的输出格式:

更多hadoop生态文章见: hadoop生态系列
参考:
https://blog.csdn.net/appstore81/article/details/15027767
https://www.cnblogs.com/52mm/p/p15.html
https://blog.csdn.net/u011812294/article/details/63262624
https://blog.csdn.net/penggougoude/article/details/82432802#commentBox
《Hadoop权威指南 大数据的存储与分析 第四版》
《hadoop技术内幕深入解析yarn架构设计与实现原理》