OS内存段页机制
1 内存分段机制
1.1 重定位
重定位可以在编译或载入程序时,修改程序中的地址(即原来程序中的地址是相对的)
如有以下程序
...
1040:_main:mov [300],
...
call xx
1000:call 40
在编译时给这段程序增加一个偏移量offset=1000,那么该段程序运行起来后实际上是这样的
...
1040:_main:mov [1300],
...
call xx
1000:call 1040
因此call 1040就能跑到main里执行了
由于编译时重定位(静态重定位)使用与一些硬编码,只能放在内存固定位置。而使用载入时重定位(动态重定位),可以找一段空闲内存,然后进行载入,但是载入后就不能再动
1.2 swap与运行时重定位
由于内存空间有限,会在磁盘中开辟出一块交换分区。当内存中出现一些睡眠时间久的进程时,就会把这些进程放入交换分区中,同时将一些被唤醒的进程从交换分区中取出来,这个过程叫做swap。从交换分区中被换出的进程被装载到内存后,又需要将内存进行一次重定位(因为进程可能被换到了其他地方),这种重定位叫做运行时重定位
300:_sum:.int 0
...
-----------------------------
...
IP-> _main:mov [300] 0
...
call xx
call 40
base:--------------------------
上述程序可以换到内存中任何地方,将代码中的地址 300变为 base+300(offset)即可,称为地址翻译。其中base在进程装载入时存在PCB中,该进程运行时,base会存在CPU寄存器中
1.3 分段
实际上,一个程序由若干段组成,每个段有各自用途,特点。如代码段只读,代码段/数据段不会动态增长,那么具体定位某具体指令(数据),是通过<段号,段内偏移>实现的。
这样的优点是方便管理,比如让只读的段只读,可读写的可读写,甚至可以选择性的载入段(如函数库)
因此,程序载入时,是将各段分别放入内存的
/*------------第一段------------*/
500K->480K
/*------------第二段------------*/
460K->360K
/*------------第三段------------*/
330K->160K
/*------------第四段------------*/
160K->90K
/*------------第五段------------*/
80K->20K
此时,PCB中存的应该是该进程的段表,段表中记录了每个段的base地址,进行运行时重定位的指令应该如此 mov [DS:100], %eax
实际上GDT表就是OS的段表,LDT是每个进程的段表,那条jmpl 0,8指令,就是访问GDT段表,因为其实际作用为:将GDT表第2项的段基址交给CS,同时IP=0,这就跳转到对应的段去了;此外每次进程切换时,就要切换LDT表。
LDTR寄存器:指向当前进程对应的那个LDT
GDT和LDT每项的内容(64位/8字节)
2 内存分页机制
2.1 内存分配算法
OS将段载入内存时会挑选空闲内存区域进行装载,而选择哪个空闲区是由算法决定的,常见算法有
- 最先适配
- 最优适配
- 最差适配
以上算法只适用在虚拟内存的分配中(内存分段是对应虚拟内存的),而物理内存使用的是内存分页机制
2.2 内存分页
将内存分为一页一页的,每页大小为4k,将每个段也分成一页一页的,装载时只要将这些页放入内存的空闲页中即可,同时段中维护一张页表,记录下页号|页框号|保护,即每页对应的页框号以及该页的保护措施(可读,可写,可读写)
MMU
此时假设有一条指令mov [0x2240],%eax,即要访问内存地址0x2240,那么只需要截取前面的0x02(前4位)作为页号,去页表中找到指定的页框号,后面的0x240(后12位)作为页内偏移地址,就能定位到指定地址了
这个功能是由MMU(内存管理单元)实现的
2.3 多级页表
内存分页存在的问题
如果内存为4G,一页内存大小为4k,那么页表中就会有1M项,页表大小就是4M,如果有100个进程,光是页表就会占据400M内存,这显然是无法接受的。
于是我们引入多级页表,用来降低内存消耗,同时保证搜索页的速度
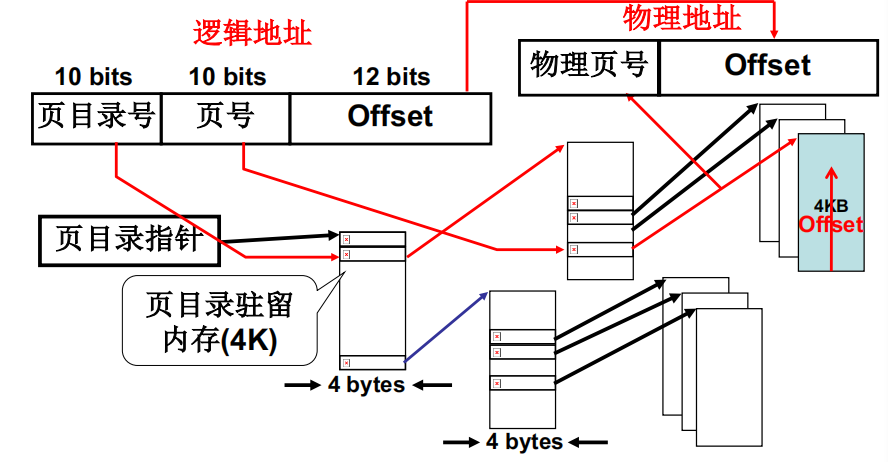
上图就是多级页表的原理,逻辑地址的前十位指向页目录(一级页表)的某一项A,A是指向二级页表B的一个指针;逻辑地址的中间十位指向二级页表B的某一项C,C是指向某一页框D的指针,逻辑地址的最后十二位就是页框D对应的页的偏移地址,就是物理地址了
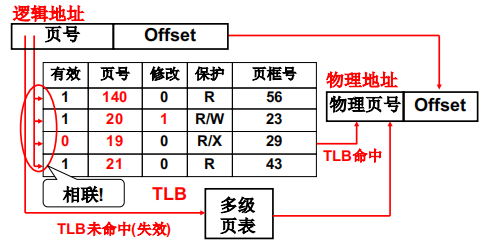
2.4 快表
多级页表仍然十分庞大(尤其是在64位系统中),为了再次加速,我们使用快表
TLB是一组相互关联的寄存器,进程通过页号寻找页框号时,先去快表里找,找不到再去多级页表里找
由于程序地址访问具有局部性:比如某个进程在循环时会不断询问内存某个地址,那么使用快表就会大幅度提高寻址速度
3 段页结合
对于用户来说,内存段的形式更适合更新维护;对于硬件层面,内存页的形式易于实现。为了将内存段与内存页结合起来,我们使用虚拟内存计数,即进程的内存段地址其实是虚拟地址,在经过映射后才是实际的物理地址,我们用两张图来解释
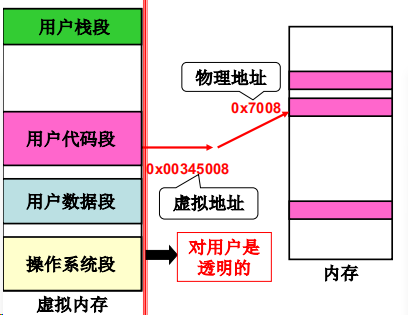
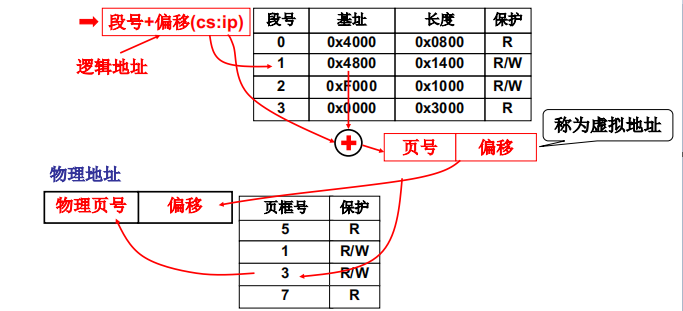
那么怎么由虚拟内存地址得到物理地址呢?
- 我们通过
cs:ip等寄存器的结合,去访问某一段的某个偏移量(去段表里找段的基址),可以得到一个32位逻辑地址 - 这个32位虚拟地址先去快表里查询,如果查得到的话,直接就有了物理地址
- 如果在快表里查不到,就要到多级页表里去查。参考多级页表查找过程,逻辑地址的前十位指向页目录(一级页表)的某一项A,A是指向二级页表B的一个指针;逻辑地址的中间十位指向二级页表B的某一项C,C是指向某一页框D的指针,逻辑地址的最后十二位就是页框D对应的页的偏移地址,就是物理地址了
3.1 段页结合的实例
我们以系统调用fork为例,分析子进程在创建过程中,是如何分配虚拟内存段,初始化页表的
3.1.1 分配虚存,建立段表
来看copy_process里的一段代码,该函数在在linux/kernel/fork.c中
int copy_process(int nr, long ebp,...){
...
copy_mem(nr, p); // 赋值内存
...
}
int copy_mem(int nr, task_struct *p){
...
unsigned long new_data_base;
new_data_base=nr*0x4000000; //64M*nr
set_base(p->ldt[1],new_data_base);
set_base(p->ldt[2],new_data_base);
...
}
我们可以发现,赋值进程的过程中,会调用函数copy_mem,这个函数的功能就是将父进程的内存段同样也分配给子进程。linux0.11中每个进程段占64M内存(并不分数据段和代码段),因此子进程的基址为64M*nr
3.1.2 分配内存,建立页表
我们继续看copy_mem里的另一段代码
int copy_mem(int nr, task_struct *p){
...
unsigned long old_data_base;
old_data_base=get_base(current->ldt[2]); // 指向父进程ldt的基址
copy_page_tables(old_data_base,new_data_base,data_limit); // 复制页表
...
}
int copy_page_tables(unsigned long from,unsigned long to, long size) {
...
from_dir = (unsigned long *)((from>>20)&0xffc); // 指向父进程一条虚存页目录,from>>22得到目录项编号,(from>>22)*4每项4字节
to_dir = (unsigned long *)((to>>20)&0xffc); // 指向子进程一条虚存页目录
size = (unsigned long)(size+0x3fffff)>>22; // 父进程拥有的虚存页目录条数
/*
* 进入循环:遍历父进程的所有页表,在子进程新建出来
* 枚举每条页目录,子进程都通过每条页目录新建一个页表
* from_page_table指向父进程的一个页表
* to_page_table指向子进程的一个新建页表
*/
for(; size-->0; from_dir++, to_dir++){
from_page_table=(0xfffff000&*from_dir); // from_fir是一个指向二级页表的指针,这里让from_page_table指向二级页表
to_page_table=get_free_page(); // to_page_table 申请新一页,用来复制from_page_table指向的那一页
...
*to_dir=((unsigned long)to_page_table)|7;// to_dir指向单元的值改为to_page_table的值,然后修改下子进程该二级页表的权限
}
}
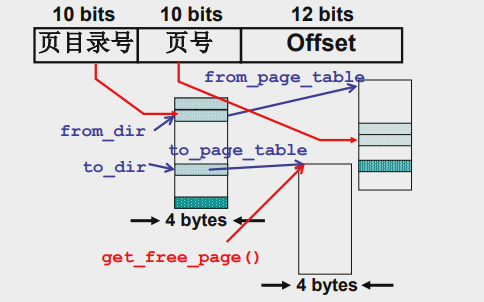
配合图和代码,我们可以看出,在复制页表的时候,from_dir指向父进程的一级页表中的页目录项,然后一项一项移动复制二级页表,from_page_table是from_dir指向单元的值,其指向了一页二级页表;对应的to_dir会跟着from_dir逐项移动,而to_page_table只要跟着申请新的页,然后复制二级页表就行
接下去就是要复制真正的页了(之前都是在复制一级和二级页表),我们看继续copy_page_tables里的代码
for(; size-->0; from_dir++, to_dir++){
from_page_table=(0xfffff000&*from_dir); // from_fir是一个指向二级页表的指针,这里让from_page_table指向二级页表
to_page_table=get_free_page(); // to_page_table 申请新一页,用来复制from_page_table指向的那一页
...
*to_dir=((unsigned long)to_page_table)|7;// to_dir指向单元的值改为to_page_table的值,然后修改下子进程该二级页表的权限
...
/*
* 将from_page_table指向的所有页都复制给to_page_table
* 一页有1024项,所以nr初始值为1024
*/
for(nr=1024;nr-->0;from_page_table++,to_page_table++){
this_page = *from_page_table; // this_page指向from_page_table存的那一页
this_page&=~2;// 只读 *to_page_table=this_page;
*from_page_table=this_page; // 父子进程指向同一页, 将该页权限改为只读,同时父子进程都更新这个只读页
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++; // 将this_page对应的页号++即可,表示多了个指向这页的进程
}
...
}
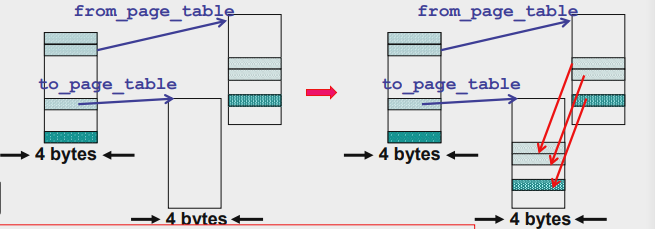
配合上图及代码,我们可以得知到目前为止,子进程已经将父进程的内存页(包括一二级页表和真正的页)复制完毕,现在一二级页表是子进程复制出来的,其他页是父子进程共享的(且被打上了只读标记)
3.1.3 写时复制
在此之后,子进程的内存映射建立完毕,但是对于子进程来说,那些页表还是只读的(因为不能和父进程同时写同一份数据),所以当子进程也要写某页数据时,就要复制该页,然后将更新LDT表中的映射,这就称为写时复制
PS:比较迷惑的是在拷贝时父进程的的指针也把页给改成了只读。。父进程又是什么时候改成可写的呢
4 内存换入-请求调页
在32位地址的内存中,用户可使用的是固定的[0,4G]内存,但是实际物理内存不一定有这么多,因此,需要借助虚拟内存来实现,因为虚存中的4G内存并非一下子都要用上,所以我们可以在请求时再映射,这就需要内存换入换出功能来实现
内存换入指对于虚存中没有对应页的地址,我们从磁盘中将该页调到物理内存中,然后建立映射的过程,下图所示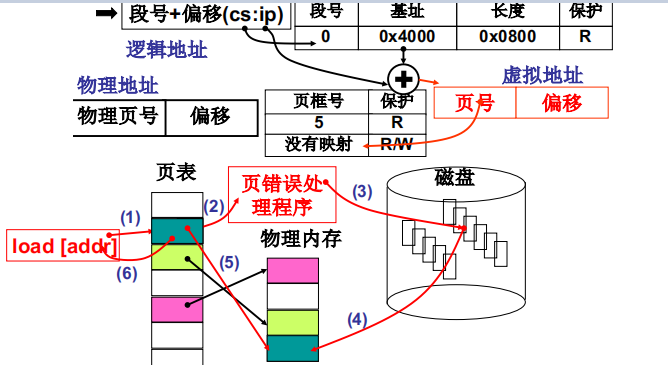
- 由
cs:ip获取的逻辑地址在页表中没有映射 - 由页错误处理程序处理这个错误
- 从磁盘调入这个缺失的页,调到物理内存中,并和虚拟内存建立映射关系
4.1 内存换入实现:缺页中断
请求调页,当然从缺页中断开始,缺页中断Page fault (页不在内存)的中断号是14,可想而知在系统初始化时会执行如下代码
void trap_init(void){ set_trap_gate(14, &page_fault); }
#define set_trap_gate(n, addr)
_set_gate(&idt[n], 15, 0, addr);
以上就是将14号中断,即缺页中断和对应的处理函数绑定在一起(可以和系统调用中断对照着看)
然后我们来看缺页中断的处理函数 _page_fault,在linux/mm/page.s中
.globl _page_fault
# 将一些寄存器信息压栈保存
xchgl %eax,(%esp) # 错误码被压到了栈中,将esp指向的内容和eax交换
pushl %ecx
pushl %edx
push %ds
push %es
push %fs
movl $0x10, %edx
mov %dx, %ds
mov %dx, %es
mov %dx, %fs
movl %cr2, %edx # 寄存器cr2里存着页错误地址,此处交给edx保存
pushl %edx
pushl %eax
testl $1, %eax # 测试标志P
jne 1f
call _do_no_page # 核心处理函数
jmp 2f
1: call _do_wp_page //保护
2: add $8, %esp
pop %fs
pop %es
pop %ds
pop %edx
pop %ecx
pop %eax
iret
可以看出,在做一些准备工作后,会调用核心函数do_no_page来处理缺页中断,我们来看看这个函数,在linux/mm/memory.c中
void do_no_page(unsigned long error_code,unsigned long address){ address&=0xfffff000; //页号
tmp=address–current->start_code; //页面对应的偏移
if(!current->executable||tmp>=current->end_data){ // 不是代码和数据,那就不是用来访问的,直接返回一个空页
get_empty_page(address); return;
}
page=get_free_page();
bread_page(page, current->executable->i_dev, nr); // 读文件系统
put_page(page, address);
}
// 获得一个空页
void get_empty_page(unsigned long address){
unsigned long tmp = get_free_page();
put_page(tmp, address);
}
以上代码的逻辑很清晰:首先获取地址所在页号(页地址),然后判断这页是不是代码页或数据页。如果不是,那就返回一个空页;如果不是,那就从文件系统中把这页读进来,然后让这页和address绑定
我们发现物理页和虚拟地址address绑定是在函数put_page中实现的,那么我们来看看这个函数
unsigned long put_page(unsigned long page, // 物理地址
unsigned long address){ // 虚拟地址
...
unsigned long tmp, *page_table;
page_table=(unsigned long *)((address>>20)&ffc); //指向页目录项
if((*page_table)&1) // 判断权限
page_table=(unsigned long*)(0xfffff000&*page_table); // 指向某二级页表
else{
tmp=get_free_page();
*page_table=tmp|7;
page_table=(unsigned long*)tmp;}
page_table[(address>>12)&0x3ff] = page|7;
return page;
}
//后面就是在二级页表中找到一空项,将page和该页绑定就行
...
}
5 内存换出
内存换出重点在各种换出算法,因为实现的难度主要也在换出算法
5.1 FIFO
经典算法了。。先入先出页面置换算法。效率很低的
5.2 LRU
选最近最长一段时间没有使用的页淘汰(最近最少使用)
算法实现看LEETCODE的LRU那题就行
class LRUCache {
public:
struct Node{
Node *nxt;
Node *pre;
int value,key;
Node(Node *nxt,Node *pre,int key,int value):nxt(nxt),pre(pre),key(key),value(value){}
};
Node *head,*tail;
int capacity,size;
unordered_map<int,Node*> mp;
LRUCache(int capacity) {
this->capacity=capacity;
this->size=0;
mp.clear();
head = new Node(nullptr,nullptr,0,0);
tail = new Node(nullptr,nullptr,0,0);
head->nxt=tail;
tail->pre=head;
}
int get(int key) {
if(mp.find(key)!=mp.end()){
Node *p = (mp.find(key))->second;
p->pre->nxt=p->nxt;
p->nxt->pre=p->pre;
moveToHead(p);
cout<<key<<":get"<<mp[key]->value<<'
';
return p->value;
}
return -1;
}
void put(int key, int value) {
if(mp.count(key)!=0){
Node *p=(mp.find(key))->second;
p->pre->nxt=p->nxt;
p->nxt->pre=p->pre;
moveToHead(p);
p->value=value;
cout<<key<<":update"<<mp[key]->value<<'
';
}else { //要插入一个结点
Node *p = new Node(nullptr,nullptr,key,value);
if(size==capacity){
removeTail();
mp[key]=p;
moveToHead(p);
cout<<key<<":put"<<mp[key]->value<<"
";
}else {
mp[key]=p;
moveToHead(p);
cout<<key<<":put"<<mp[key]->value<<"
";
size++;
}
}
}
// 移除队尾结点
void removeTail(){
Node *p=tail->pre;
if(p==head)return;
p->pre->nxt=p->nxt;
p->nxt->pre=p->pre;
mp.erase(p->key);
}
void moveToHead(Node *p){
p->nxt=head->nxt;
p->pre=head;
head->nxt->pre=p;
head->nxt=p;
}
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/