存储机制
RabbitMQ消息有两种类型:持久化消息和非持久化消息。
这两种消息都会被写入磁盘。
持久化消息在到达队列时写入磁盘,同时会内存中保存一份备份,当内存吃紧时,消息从内存中清除。这会提高一定的性能。
非持久化消息一般只存于内存中,当内存吃紧时会被换入磁盘,以节省内存空间。
RabbitMQ存储层包含两个部分:队列索引和消息存储,如下图

队列索引:rabbit_queue_index(下文简称index)
index维护队列的落盘消息的信息,如存储地点、是否已被交付给消费者、是否已被消费者ack等。每个队列都有相对应的index。
index使用顺序的段文件来存储,后缀为.idx,文件名从0开始累加,每个段文件中包含固定的segment_entry_count条记录,默认值是16384。每个index从磁盘中读取消息的时候,至少要在内存中维护一个段文件,所以设置queue_index_embed_msgs_below值得时候要格外谨慎,一点点增大也可能会引起内存爆炸式增长。
消息存储:rabbit_msg_store(下文简称store)
store以键值的形式存储消息,所有队列共享同一个store,每个节点有且只有一个。从技术层面上说,store还可分为msg_store_persistent和msg_store_transient,前者负责持久化消息的持久化,重启后消息不会丢失;后者负责非持久化消息的持久化,重启后消息会丢失。通常情况下,两者习惯性的被当作一个整体。
store使用文件来存储,后缀为.rdq,经过store处理的所有消息都会以追加的方式写入到该文件中,当该文件的大小超过指定的限制(file_size_limit)后,将会关闭该文件并创建一个新的文件以供新的消息写入。文件名从0开始进行累加。在进行消息的存储时,RabbitMQ会在ETS(Erlang Term Storage)表中记录消息在文件中的位置映射和文件的相关信息。
消息(包括消息头、消息体、属性)可以直接存储在index中,也可以存储在store中。最佳的方式是较小的消息存在index中,而较大的消息存在store中。这个消息大小的界定可以通过queue_index_embed_msgs_below来配置,默认值为4096B。当一个消息小于设定的大小阈值时,就可以存储在index中,这样性能上可以得到优化(可理解为数据库的覆盖索引和回表)。
读取消息时,先根据消息的ID(msg_id)找到对应存储的文件,如果文件存在并且未被锁住,则直接打开文件,从指定位置读取消息内容。如果文件不存在或者被锁住了,则发送请求由store进行处理。
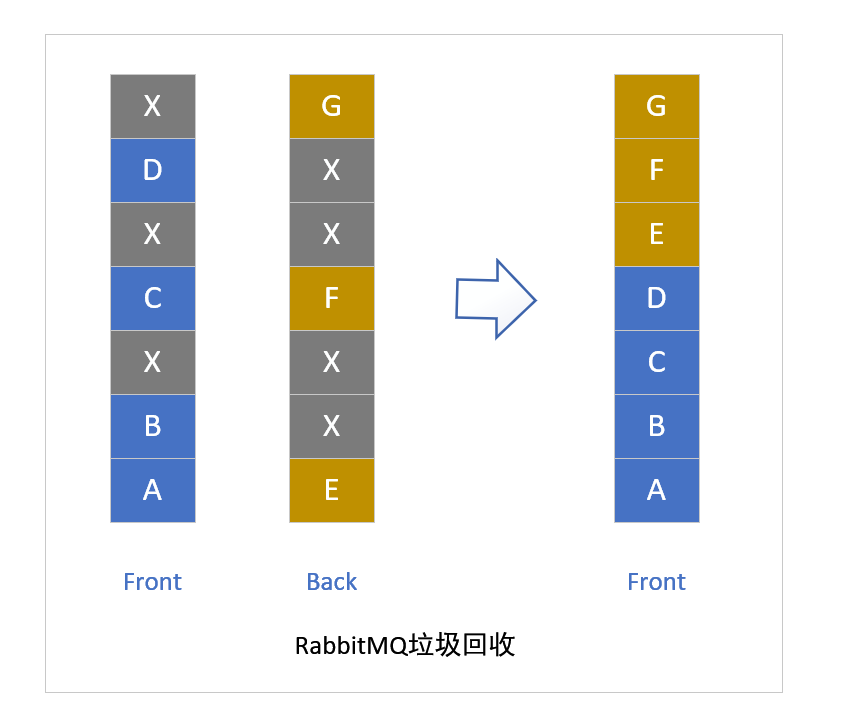
删除消息时,只是从ETS表删除指定消息的相关信息,同时更新消息对应的存储文件和相关信息。在执行消息删除操作时,并不立即对文件中的消息进行删除,也就是说消息依然在文件中,仅仅是标记为垃圾数据而已。
当一个文件中都是垃圾数据时可以将这个文件删除。当检测到前后两个文件中的有效数据可以合并成一个文件,并且所有的垃圾数据的大小和所有文件(至少有3个文件存在的情况下)的数据大小的比值超过设置的阈值garbage_fraction(默认值0.5)时,才会触发垃圾回收,将这两个文件合并,执行合并的两个文件一定是逻辑上相邻的两个文件。合并逻辑:
-
锁定这两个文件
-
先整理前面的文件的有效数据,再整理后面的文件的有效数据
-
将后面文件的有效数据写入到前面的文件中
-
更新消息在ETS表中的记录
-
删除后面文件
队列结构
通常队列由rabbit_amqqueue_process和backing_queue这两部分组成
rabbit_amqqueue_process负责协议相关的消息处理,即接收生产者发布的消息、向消费者交付消息、处理消息的确认(包括生产端的confirm和消费端的ack)等
backing_queue是消息存储的具体形式和引擎,并向rabbit_amqqueue_process提供相关的接口以供调用。
如果消息投递的目的队列是空的,并且有消费者订阅了这个队列,那么该消息会直接发送给消费者,不会经过队列这一步。当消息无法直接投递给消费者时,需要暂时将消息存入队列,以便重新投递。
RabbitMQ的队列消息有4种状态:
-
alpha:消息索引和消息内容都存内存,最耗内存,很少消耗CPU
-
beta:消息索引存内存,消息内存存磁盘
-
gama:消息索引内存和磁盘都有,消息内容存磁盘
-
delta:消息索引和内容都存磁盘,基本不消耗内存,消耗更多CPU和I/O操作
消息存入队列后,不是固定不变的,它会随着系统的负载在队列中不断流动,消息的状态会不断发送变化。
持久化的消息,索引和内容都必须先保存在磁盘上,才会处于上述状态中的一种,gama状态只有持久化消息才会有的状态。
在运行时,RabbitMQ会根据消息传递的速度定期计算一个当前内存中能够保存的最大消息数量(target_ram_count),如果alpha状态的消息数量大于此值,则会引起消息的状态转换,多余的消息可能会转换到beta、gama或者delta状态。区分这4种状态的主要作用是满足不同的内存和CPU需求。
对于普通没有设置优先级和镜像的队列来说,backing_queue的默认实现是rabbit_variable_queue,其内部通过5个子队列Q1、Q2、delta、Q3、Q4来体现消息的各个状态。
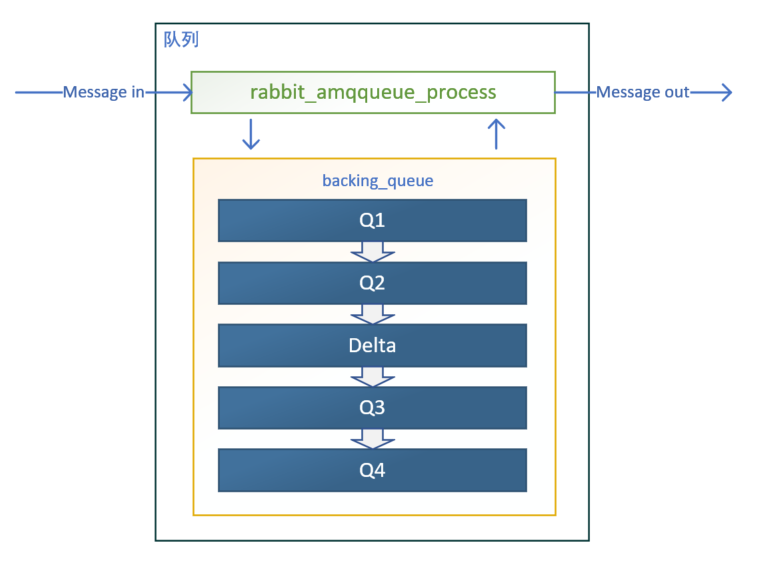
消费者获取消息也会引起消息的状态转换。
当消费者获取消息时,首先会从Q4中获取消息,如果获取成功则返回。如果Q4为空,则尝试从Q3中获取消息,系统首先会判断Q3是否为空,如果为空则返回队列为空,即此时队列中无消息。如果Q3不为空,则取出Q3中的消息,进而再判断此时Q3和Delta中的长度,如果都为空,则可以认为 Q2、Delta、 Q3、Q4 全部为空,此时将Q1中的消息直接转移至Q4,下次直接从 Q4 中获取消息。如果Q3为空,Delta不为空,则将Delta的消息转移至Q3中,下次可以直接从Q3中获取消息。在将消息从Delta转移到Q3的过程中,是按照索引分段读取的,首先读取某一段,然后判断读取的消息的个数与Delta中消息的个数是否相等,如果相等,则可以判定此时Delta中己无消息,则直接将Q2和刚读取到的消息一并放入到Q3中,如果不相等,仅将此次读取到的消息转移到Q3。
这里就有两处疑问,第一个疑问是:为什么Q3为空则可以认定整个队列为空?试想一下,如果Q3为空,Delta不为空,那么在Q3取出最后一条消息的时候,Delta 上的消息就会被转移到Q3这样与 Q3 为空矛盾;如果Delta 为空且Q2不为空,则在Q3取出最后一条消息时会将Q2的消息并入到Q3中,这样也与Q3为空矛盾;在Q3取出最后一条消息之后,如果Q2、Delta、Q3都为空,且Q1不为空时,则Q1的消息会被转移到Q4,这与Q4为空矛盾。其实这一番论述也解释了另一个问题:为什么Q3和Delta都为空时,则可以认为 Q2、Delta、Q3、Q4全部为空?
通常在负载正常时,如果消费速度大于生产速度,对于不需要保证可靠不丢失的消息来说,极有可能只会处于alpha状态。对于持久化消息,它一定会进入gamma状态,在开启publisher confirm机制时,只有到了gamma 状态时才会确认该消息己被接收,若消息消费速度足够快、内存也充足,这些消息也不会继续走到下一个状态。
在系统负载较高时,消息若不能很快被消费掉,这些消息就会进入到很深的队列中去,这样会增加处理每个消息的平均开销。因为要花更多的时间和资源处理“堆积”的消息,如此用来处理新流入的消息的能力就会降低,使得后流入的消息又被积压到很深的队列中,继续增大处理每个消息的平均开销,继而情况变得越来越恶化,使得系统的处理能力大大降低。 应对这一问题一般有3种措施:
-
增加prefetch_count的值,即一次发送多条消息给消费者,加快消息被消费的速度。
-
采用multiple ack,降低处理 ack 带来的开销
-
流量控制
集群原理
RabbitMQ分布式部署有3种方式:集群、Federation和Shovel
这三种方式并不是互斥的,可以根据需求选择相互组合来达到目的,后两者都是以插件的形式进行设计,复杂性相对高
集群
部署RabbitMQ的机器称为节点(broker)。broker有2种类型节点:磁盘节点和内存节点。顾名思义,磁盘节点的broker把元数据存储在磁盘中,内存节点把元数据存储在内存中,很明显,磁盘节点的broker在重启后元数据可以通过读取磁盘进行重建,保证了元数据不丢失,内存节点的broker可以获得更高的性能,但在重启后元数据就都丢了。元数据包含以下内容:
-
queue元数据:queue名称、属性
-
exchange:exchange名称、属性(注意此处是exchange本身)
-
binding元数据:exchange和queue之间、exchange和exchange之间的绑定关系
-
vhost元数据:vhost内部的命名空间、安全属性数据等
队列所在的节点称为宿主节点。
队列创建时,只会在宿主节点创建队列的进程,宿主节点包含完整的队列信息,包括元数据、状态、内容等等。因此,只有队列的宿主节点才能知道队列的所有信息。
队列创建后,集群只会同步队列和交换器的元数据到集群中的其他节点,并不会同步队列本身,因此非宿主节点就只知道队列的元数据和指向该队列宿主节点的指针。
这样的设计,保证了不论从哪个broker中均可以消费所有队列的数据,并分担了负载,因此,增加broker可以线性提高服务的性能和吞吐量。
但该方案也有显著的缺陷,那就是不能保证消息不会丢失。当集群中某一节点崩溃时,崩溃节点所在的队列进程和关联的绑定都会消失,附加在那些队列上的消费者也会丢失其订阅信息,匹配该队列的新消息也会丢失。
崩溃节点重启后,需要从磁盘节点中同步元数据信息,并重建队列,所以,集群中要求必须至少有一个broker为磁盘节点,以保证集群的可用性。
为何集群不将队列内容和状态复制到所有节点上呢?有2个原因:
-
如果包含了完整队列,那么所有节点将会是同样的数据拷贝,也就是所有节点均互为镜像,无法拓宽负载,延展性不高
-
每次的同步都会让消息同步到其他节点上并落盘,引发大量的网络IO和磁盘IO,无法提升性能。(此处可以引申思考一下kafka中replica的分配方式)
如果磁盘节点崩溃了,集群依然可以继续路由消息(因为其他节点元数据在还存在),但无法做以下操作:
-
创建队列、交换器、绑定
-
添加用户
-
更改权限
-
添加、删除集群节点
也就是说,唯一的磁盘节点崩溃后,为了保证可用性,禁用了和元数据相关的添加、修改和删除操作。所以建立集群的时候,建议保证有2个以上的磁盘节点。
集群添加或者删除节点时,会把变更通知到至少一个磁盘节点。在内存节点重启后,会先从磁盘节点中同步元数据,内存节点中唯一存储到磁盘的是磁盘节点的地址。
RabbitMQ采用镜像队列的方式保证队列的可靠性。镜像队列就是将队列镜像到集群中的其他节点,如果集群中一个节点失效了,队列就能自动的切换到镜像中的节点,一个镜像队列中包含有1个主节点master和若干个从节点slave。其主从节点包含如下几个特点:
-
消息的读写都是在master上进行,并不是读写分离
-
master接收命令后会向salve进行组播,salve会命令执行顺序执行
-
master失效,根据节点加入的时间,最老的slave会被提升为master
-
互为镜像的是队列,并非节点,集群中可以不同节点可以互为镜像队列,也就是说队列的master可以分布在不同的节点上
与Kafka的差异
RabbitMQ第一版发布于2007年,其构思的本质的原因是AMQP的出现。AMQP出现之前各家的MQ产品百花齐放,但也因此导致整合非常困难,没有形成统一的消息总线,在AMQP神兵天降之后RabbitMQ就开启了它的职业生涯。
Kafka起源于LinkedIn,开源于2011年,目标是为了帮助处理持续数据流而设计的组件,在尝试了消息系统、数据聚合、ETL工具等方式后,均无法满足其需求,因此Kafka就诞生了。
RabbitMQ遵循了AMQP协议,拥有比较完善的消息交换模型:
-
支持生产者消费者模式和发布订阅模式
-
支持消息的ack机制:显式ack和自动ack
-
支持多租户
-
支持权限配置
-
支持死信队列
-
支持消息超时机制
-
...
Kafka作为一个分布式流式组件:
-
支持生产者消费者模式和发布订阅模式
-
支持流回放
-
支持分批次写入
-
支持分片
-
支持副本策略
-
支持数据保存策略
-
...
以上特性可以分别看出两者使用场景上的差别,下面补充一下两者针对消息存储和消费的差异性。
存储方式
RabbitMQ将消息存储于队列(Queue)中,消费者确认收到消息后(返回ack)才会移除消息。
Kafka将消息存于主题(Topic)中,并分片分散在各个节点,提高了并行率。其存储策略可配置时间策略(如消息最长保存7天)或者空间策略(如消息最多保存10G)。
有序性
RabbitMQ中队列是先进先出队列,因此保证了消息的有序性。
Kafka如果分片配置为1,则消息也保证了有序性,但却降低了吞吐率;如果分片配置为多份,则只能保证每个分片里的数据是有序的,无法保证整个分片是有序的。
消息ACK机制
RabbitMQ如果没有配置自动ack,消息或者队列也没有设置TTL,则MQ将会一直等待消费者显式响应ack后才会将消息移除,否则消息将一直存着,这种情况下,如果出现消费者崩溃或者消费速率低于生产速率等情况,会导致消息堆积占用内存,时间一长将蔓延影响到生产者生产数据。
Kafka不支持消息的ack,但提供了消息偏移量offset,消费者根据offset获取消息,且支持消息回放(重复消费)。
集群
RabbitMQ有多种集群方式分为两大类:非镜像集群和镜像集群。在可靠性上,RabbitMQ使用集群+带有负载均衡的软硬件(如HAProxy)组件实现。在弹性拓展上,非镜像集群,拓展节点可线性提高性能,但由于并非所有节点都存储队列本身,因此如果某一个节点故障了,该节点的数据将会丢失。镜像集群,队列数据将同步到其他节点,保证了可用性,但同时也增加了网络和磁盘的负载,损失了性能。Kafka
Kafka在设计时支持分片和副本策略,该架构保存消息会消息分散到在不同的节点,在拥有可靠性的同时也有较好的拓展能力,也因此,但因依赖了ZooKeeper,且需要保证节点数为奇数个。