Linux中的文件
1.1 文件属性概述(ls -lhi)
linux里一切皆文件
Linux系统中的文件或目录的属性主要包括:索引节点(inode),文件类型,权限属性,链接数,所归属的用户和用户组,最近修改时间等内容: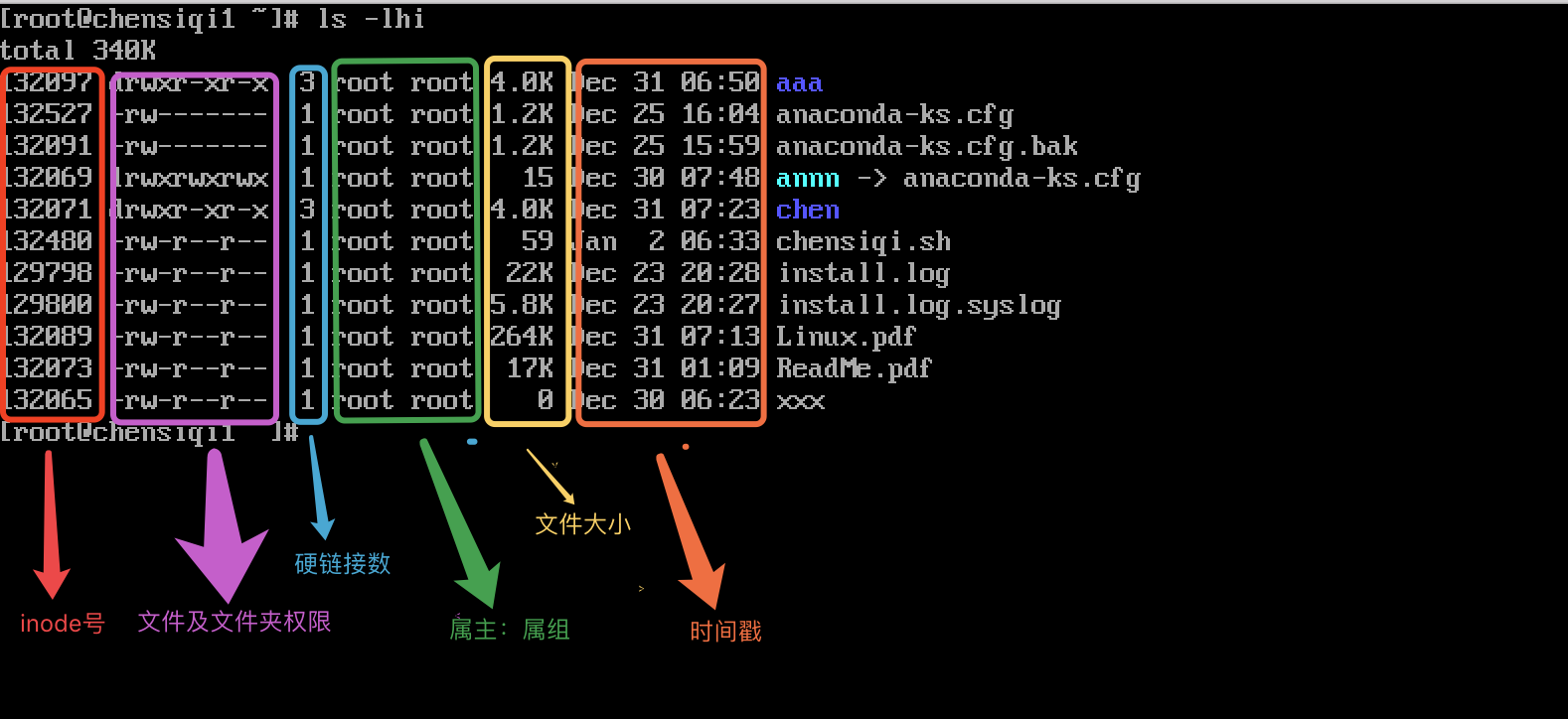
文字解释:
第一列:inode索引节点编号(相当于人的身份证,全国唯一)
第二列:文件类型及权限
第二列共11个字符:其中第一个字符为文件类型,随后的9个字符为文件的对应权限,最后一个字符点号“.”是和selinux有关的一个标识;
第三列:硬链接个数(详细参看ln命令的讲解);
相当于超市的多个入口,可以从不同的文件入口进入文件,还可以互为备份(消防通道)
第四列:文件或目录所属的用户 文件的所有者(属主);
linux里面文件和程序的存在必须要有用户和组满足相应的存在需求。
第五咧:文件或目录所属的组
第六列:文件或目录的大小;
第七八九列:文件或目录的修改时间:默认月日时分
第十列:实际的文件或目录名
文件名不算文件的属性
下面我们以chensiqi文件为例进行说明,具体列的内容参考下上面的图:
1736707 -rwx-xr-x- 1 root root 35 Oct 28 11:29 chensiqi
- inode索引节点编号:1736707
- 文件类型,文件类型是-,表示这是一个普通文件;
- 文件权限:文件权限是rwxr-xr-x,表示文件属主可读,可写,可执行,文件归属的用户组可读可执行,其他用户可执行。
- 硬链接个数:表示chensiqi这个文件没有其它的硬链接,因为连接数是1,就是他本身;
- 文件属主:这个文件所属的用户,这里意思是chensiqi文件被root用户拥有,注意,是第一个root;
- 文件属组:这个文件所属的用户组,在这里是root用户组,是显示信息里的第二个root
- 文件大小:文件大小是35个字节
- 文件修改时间:这里的时间是该文件最后被更新(包括文件创建,内容更新,文件名更新等)的时间,可用如下命令查看文件的修改,访问,创建的时间
1.2 索引节点inode
1.2.1 inode 概述
- 硬盘要存储数据,首先要分区,然后格式化创建文件系统,最后挂载,才能存数据。
- Inode,中文意思是索引节点(index node)。在每个linux存储设备或存储设备的分区(存储设备可以是硬盘,软盘,U盘...)被格式化为ext4(CentOS6.8)文件系统后,一般生成两部分:第一部分是Inode(很多个),第二部分是Block(很多个)。
- 这个Block是用来存储实际数据用的,例如:照片,视频等普通文件数据。
- 而inode就是用来存储这些数据属性信息的(也就是ls -l的结果),inode属性信息包括不限于文件大小,属主(用户),归属的用户组,文件权限,文件类型,修改时间,还包含指向文件实体的指针功能(inode节点--block的对应关系)等,但是,inode里面唯独不包含文件名本身
身份证号 ==== inode号
身高体重三围有没有头发(属性)====inode
- Inode除了记录文件属性的信息外,还会为每个文件进行信息索引,所以就有了inode的数值。操作系统根据指令,即可通过inode的值最快的找到相对应的文件实体。文件,inode,block之间的关系见下图:
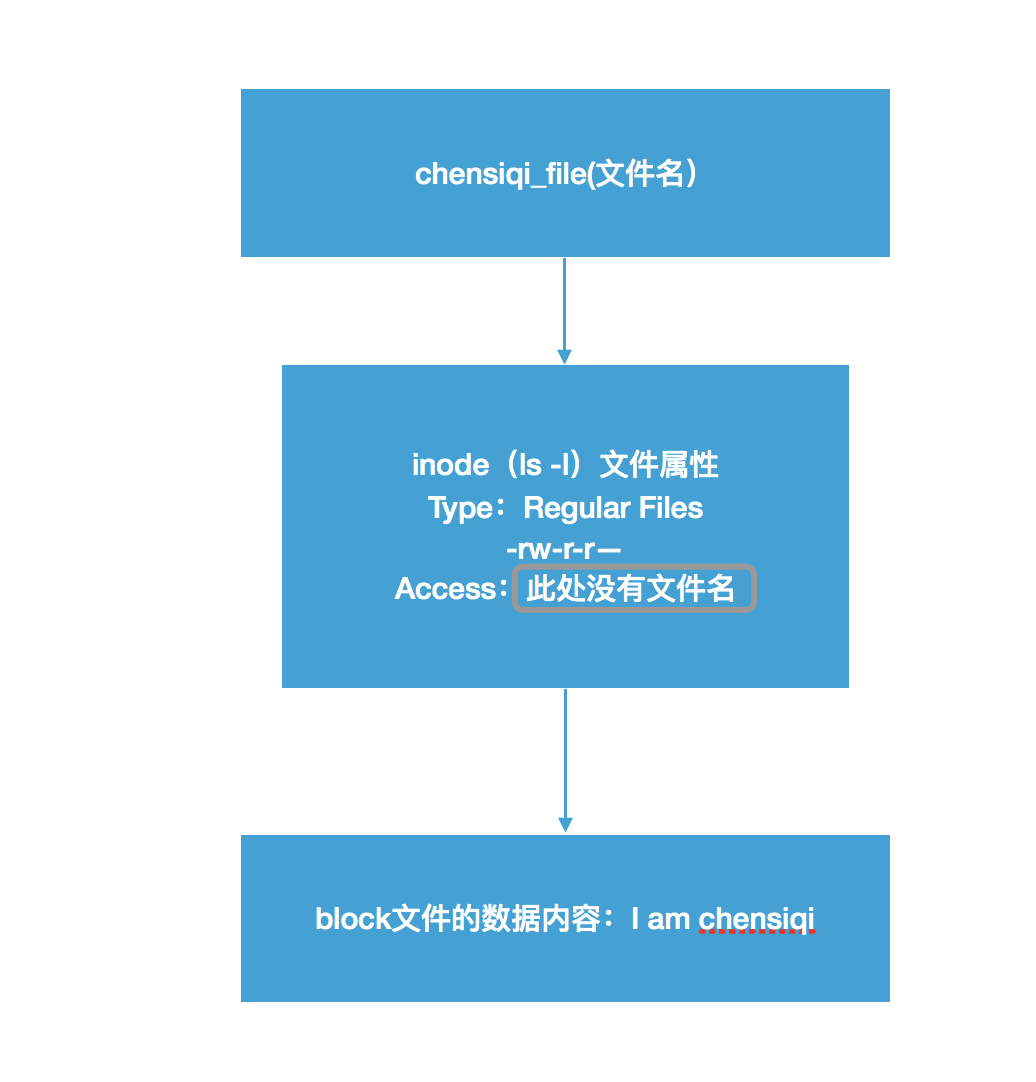
为了能让大家更形象的理解,我举个例子。假如有一本书,存储设备和分区就相当于这本书,Block相当于书中的每一页内容,而inode就相当于这本书前面的目录,一本书有很多内容,一个知识点可能有多页,如果想查找某部分或某知识点的内容,我们一般先查书的目录,通过目录能更快的找到我们想要看的知识点的内容。虽然不太恰当,但还是比较形象。
当我们用ls查看某个目录或文件时,如果加上-i参数,就可以看到inode节点了;
【root@chensiqi /】# ls -i
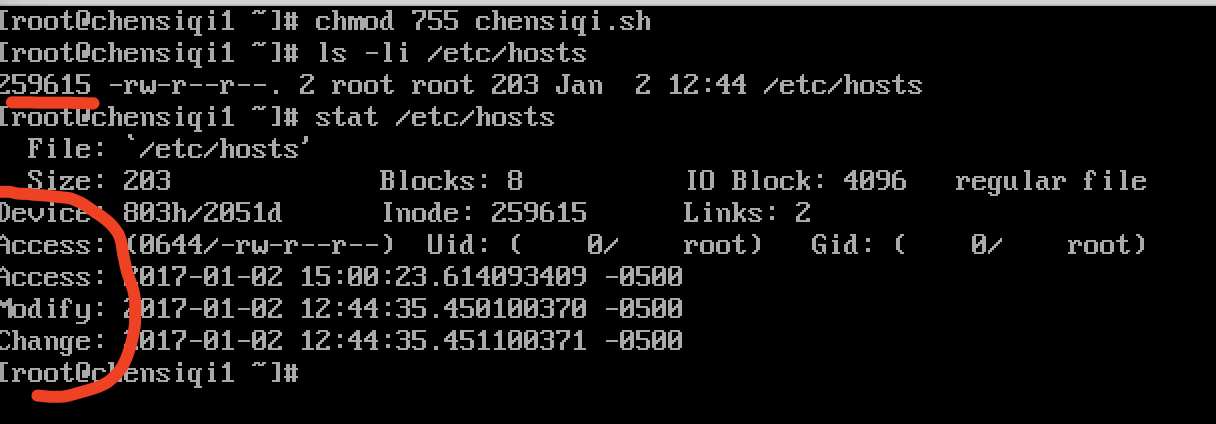
- 上图第一列inode值259615;查看一个文件或目录的inode,通过ls命令的-i参数即可。
- 因为inode要存放文件的属性信息,所以每个inode本身是有大小的,Centos5系列inode的默认大小是128字节,而Centos6系列inode的默认大小是256字节,inode的大小在分区被格式化创建文件系统之后定下来的,格式化以后就无法更改inode大小,格式化前可以通过参数指定inode的大小,但是一般企业工作环境没这个需求。
- 不同Centos版本inode大小不同
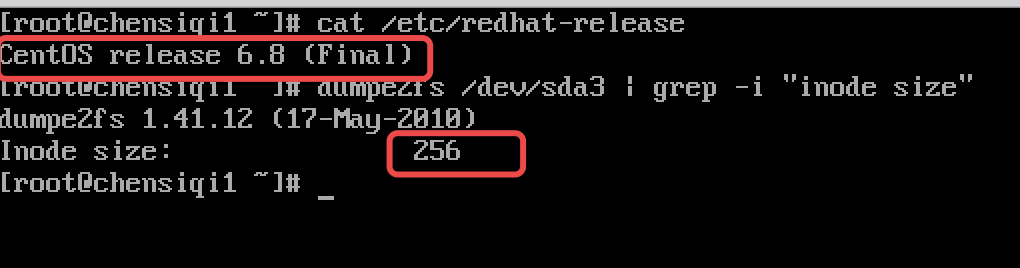
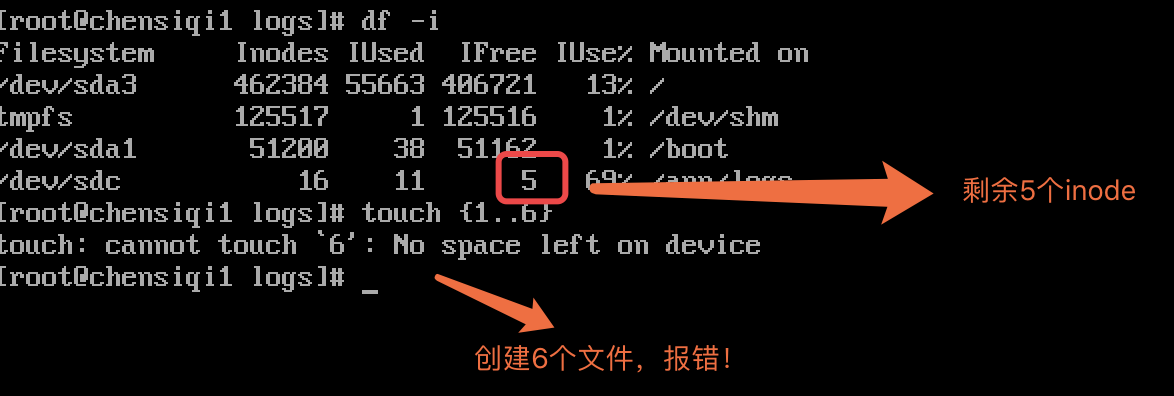
查看文件系统inode总量以及剩余量
【root@chensiqi /】# df -i
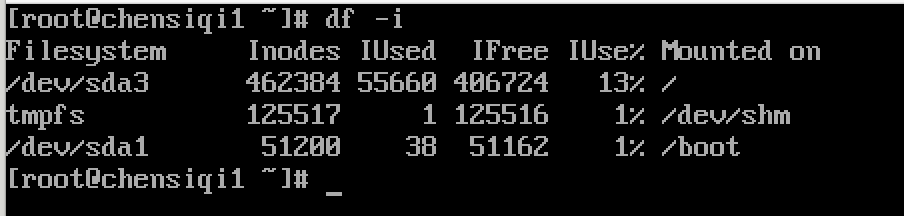
查看磁盘使用量
[root@chensiqi /]# df -h
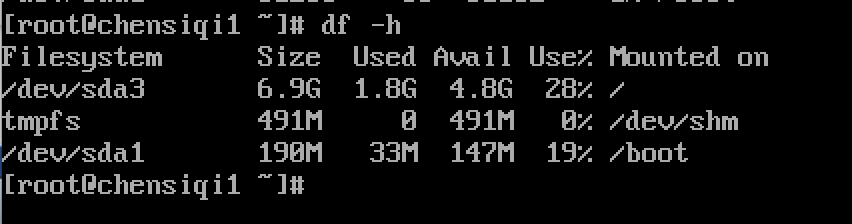
Inode:存放文件的属性+文件内容的位置(block的位置) df - l 查看使用量
Block:存放实际数据
1.2.2 企业案例模拟:
模拟磁盘满的情况
磁盘满的一个特征(no space left on device)
1.block 满了 磁盘空间满了
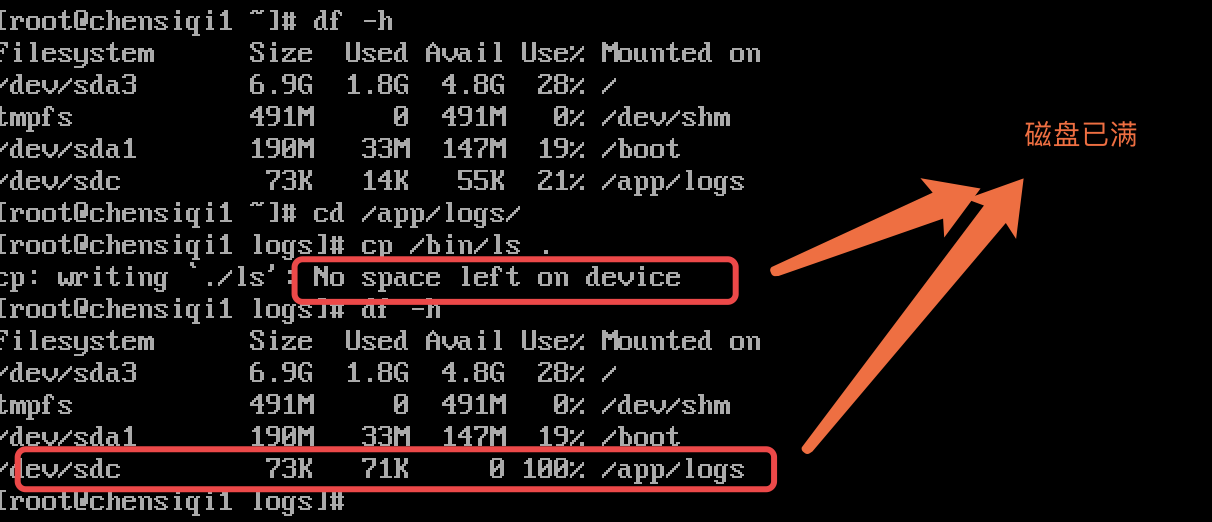
2.inode 满了 创建一个文件就需要一个inode
1.2.3 有关inode的小结
学会给阶段性的知识做小结是学好linux运维的好习惯。
- 诞生:磁盘被分区并格式化为ext4文件系统后,会生成一定数量的inode和block
- inode称为索引(目录)节点,它的作用是存放文件的属性信息以及作为文件的索引(指向文件的实体block)
- ext3/ext4 文件系统的block 存放的是文件的实际内容(数据)。
- inode是磁盘上的一块存储空间,CentOS6非启动分区inode默认大小256字节,CentOS5是128字节
- inode的表现是形式一串数字,不同的文件对应的inode(一串数字)在文件系统里是唯一的。
- inode节点号相同的文件,互为硬链接文件,可以认为是一个文件的不同入口。
- ext3/ext4文件系统下,一个文件至少要占用一个inode和一个block。(文件size比较大)
- ext3/ext4文件系统下,正常情况一个文件占用且只能占用一个inode(人和身份证号)
- block是用来存储实际数据的,每个block的大小一般有1k,2k,4k几种。其中引导分区等为1k,其他普通分区多为4K(CentOS6)
- 如果一个文件很大(高清大片4G),需要占用多个block,如果文件很小(0.01k),至少占一个block,并且这个block的剩余空间就浪费了,即无法在存储其他数据
1.2.4 有关Block的知识小结
- 磁盘读取数据是按block为单位读取的
- 一个文件可能占用多个block。每读取一个block就会消耗一次磁盘I/O
- 如果要提升磁盘I/O性能,那么就要尽可能一次性读取数据尽量的多。
- 一个block只能存放一个文件的内容,无论内容多小。如果block默认是4K大小,那么存放一个1K的文件,剩余3K就不能存放别的文件,只能浪费了
- Block并非越大越好。Block太大对于存放小文件就会浪费磁盘空间,例如:1000K的文件,Block大小为4K,占用250个Block,如果Block默认为1K,则需要占用1000个Block。访问效率谁更高?消耗I/O分别为250次和1000次。
- 根据业务需求,确定默认的block大小,如果是大文件(大于16K)一般设置block大一点,小文件(小于1K)一般设置block小一点
- block太大,例如4K,文件都是0.1K的,大量浪费磁盘空间,但是访问性能高
- block太小,例如1K,文件都是1000K,消耗大量磁盘I/O
- 企业里文件都会比较大(一般会大于4K),block设置大一些会提升磁盘访问效率。
- ext3/ext4文件系统(CentOS5和CentOS6),一般都设置为4K。
当前的生产环境一般设置为4K,特殊的业务,如视频可以加大block大小
- Block块越大对于单个的小文件多(0.5K)的业务,会非常浪费空间,因为,一个文件无论多大都会必须占用至少一个inode和一个block,磁盘读取数据是按Block为单位读取的,但是对于大文件,可以提升读取的效率,因为如果block太小,就要读多个block,这样就消耗磁盘I/O,如果block大,则会读较少的aBlock就读完数据,从而减少磁盘I/O
Block块太小又会影响硬盘读取大文件数据的效率,Block块越小,同样存储一个文件就需要更多的Block,这样硬盘读取数据时就要读取多个block,因此效率就越低。
Block分大了,浪费空间,分小了,影响磁盘读取性能
1.2.5 inode与block总的小结
- 磁盘被分区格式化文件系统后,会分为inode和block两部分内容
- inode存放文件的属性以及指向文件实体的指针(block的位置),文件名不在inode里,一般在上级目录的block里
- 访问文件的过程,通过文件名(上一级目录的block)--->inode--->blocks
- inode centos6一般情况默认非启动分区大小256B,block大小1,2,4K,默认是4K,注意,引导分区等特殊分区除外
- 通过df -i 查看inode的数量及使用情况,dumpe2fs /dev/sda3 查看inode及block的大小及数量
- 一个文件至少要占用一个inode及一个block,多个文件可以占用同一个inode(硬链接),相同文件
- 一个block只能被一个文件使用,如果文件很小block很大,剩余空间浪费,无法继续被其他文件使用
- block不是越大越好,要根据业务的文件大小进行选择,一般CentOS6就是默认4K
- 可以在格式化的时候改变inode及block的大小
1.2.6 企业面试题一:
一个100M(100000K)的磁盘分区,分别写入1K的文件或写入1M的文件,分别可以写多少个?
- 1K文件虽小,但是block一般默认4K,即使1K的数据也会占用4K大小,比如大家创建一个空文件,然后du -sk 看看大小是多少。(如果大家此时认为应该100000/4的话,那么你就掉坑了-_-!别忘了存储数据,消耗的不光是block还有inode,inode默认只有256K(centos6),每个文件至少占用一个block的同时还会占用一个inode)
- 1M的数据他刚好能被4整除。所以不会浪费空间,大约为100个左右,inode充足。
总上对于大文件一般inode是足够的,大文件基本也不会浪费空间,整除就可以;但是对于小文件来说,inode是不足够的,因此能够存储的数量就是inode的数量
1.27 企业面试题二:
如果向磁盘写入数据提示如下错误:No space left on device,通过df -h查看磁盘空间,发现没满,请问可能原因是什么?企业场景什么情况下会导致这个问题发生?
- 磁盘没满但是不能卸乳文件,最可能的原因就是inode被耗尽了
企业工作中邮件临时队列/var/spool/clientmquene或/var/spool/postfix/maildrop这里很容易被大量小文件占满导致No space left on device的错误。clientmquene目录只有安装了sendmail服务,才会有,是sendmail的临时队列。centos5.8默认就会装sendmail,centos6默认没有sendmail,但是有postfix
1.3文件类型及文件扩展名
1.3.1 文件类型介绍
- windows扩展名让系统区分不同文件类型,扩展名错误导致文件无法打开。
- linux通过扩展名让人区分文件类型,为了易读,错误也可以正常使用
例如:
windows图片文件扩展名:jpg,jpeg,png,gif等
文本文件扩展名:doc,docx,txt,pdf
1.3.2 Linux中的文件类型
对于这里我不想说太多,因为实在感觉对于实际应用意义不大,大家只需要知道通过ls -l查看目录的时候,
1,如果权限那里是-rw--r--r--,第一个字符是‘-’就代表是普通文件
2,如果第一个字符是d例如drw--r--r--.就代表是个文件夹
3,如果第一个字符是l例如lrw--r--r--,就代表是个软链接
1.3.3 软连接
软连接文件可通过:
ln -s 源文件名 新文件名 的方式来创建(如果不使用-s,则会创建硬链接,但不适合目录)
这个软连接和windows的快捷方式是相似的。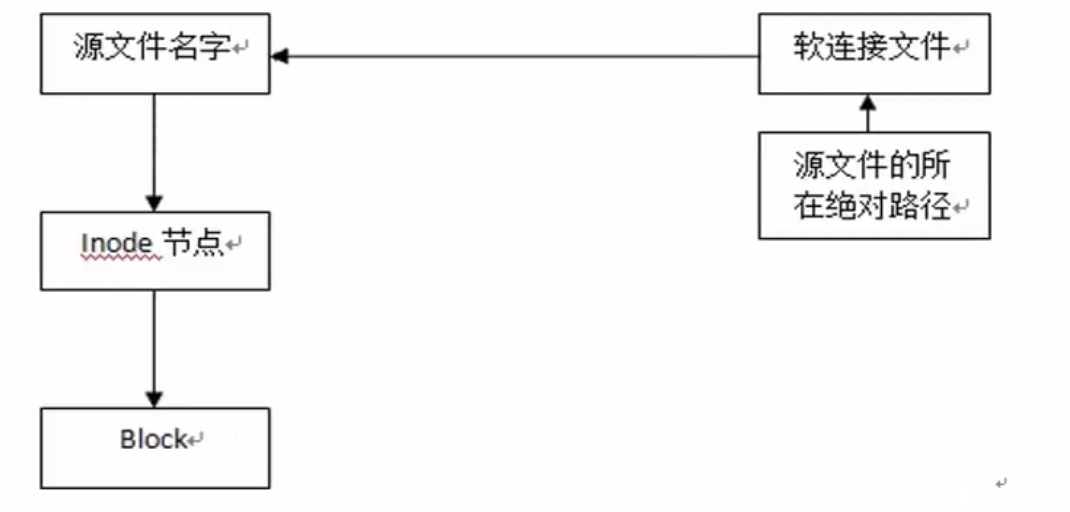
1.3.4 Linux下扩展名的作用
在linux中,虽然扩展名没什么意义,但是为了兼容windows,同时,便于我们大多数windows用户区分文件的不同,所以,我们还是习惯通过扩展名来表示不同文件的类型。
如下:
- tar,tar.gz,tgz,zip,tar.bz表示压缩文件,创建命令一般为tar,gzip,unzip等
- .sh表示shell脚本文件,通过shell语言开发的程序
- .pl表示perl语言文件,通过perl语言开发的程序
- .py表示python语言文件,通过python语言开发的程序
- .html,.htm,.php,.jsp,.do表示网页语言的文件
- .conf表示系统的配置文件
- .rpm表示rpm安装包文件
1.4 知识扩展(企业实际经验)
问题: Linux文件系统如何选择?
通过综合使用多种标准文件系统Benchmarks对Ext3,Ext4,Reiserfs,XFS,JFS,Reiser4的性能测试对比,对不同应用选择合适的文件系统给出以下方案,供大家参考。
- 大量小文件(LOSF,Lost of small files)I/O应用(如小图片)
- Reiserfs(首选),Ext4文件系统适合这类负载特征,IO调度算法选择deadline,block size=4096,ext4关闭日志功能
- reiserfs mount参数:-o defaults,async,noatime,nodiratime,notail,data=writeback
- ext4 mount参数:-o defaults,async,noatime,nodiratime,data=writeback,barrier=0
- 关闭ext4日志:tune2fs -O^has_joumal /dev/sdXX
2.大文件I/O应用(如视频下载,流媒体)
- EXT4文件系统适合此类负载特征,IO调度算法选择anticipatory,block size=4096,关闭日志功能,启用extent(default)
- mount参数:-o defaults,async,noatime,nodiratime,data=writeback,barrier=0
- 关闭ext4日志:tune2fs -O^has_joumal /dev/sdXX
3.SSD文件系统选择
EXT4/Reiserfs可以作为SSD文件系统,但未对SSD做优化,不能充分发挥SSD性能,并影响SSD使用时间
Btrfs对SSD作了优化,mount通过参数启用。但Btrfs扔处于试验阶段,生产环境谨慎使用
JFFS2/Nilfs2/YAFFS是常用的flash file system,在嵌入式环境广泛应用,建议使用。性能目前还未作测试评估
简单分析一下选择Reiserfs和ext4文件系统的原因
1、Reiserfs
大量小文件访问,衡量指标是IOPS,文件系统性能瓶颈在于文件元数据操作、目录操作、数据寻址。reiserfs对小文件作了优化,并使用B+ tree组织数据,加速了数据寻址,大大降低了open/create/delete/close等系统调用开销。mount时指定noatime,nodiratime,notail,减少不必要的inode操作,notail关闭tail package功能,以空间换取更高性能。因此,对于随机的小I/O读写,reiserfs是很好的选择。
2、Ext4
大文件顺序访问,衡量指标是IO吞吐量,文件系统性能瓶颈在于数据块布局(layout)、数据寻址。Ext4对ext3主要作了两方面的优化:
一:是inode预分配。这使得inode具有很好的局部性特征,同一目录文件inode尽量放在一起,加速了目录寻址与操作性能。因此在小文件应用方面也具有很好的性能表现。
二:是extent/delay/multi的数据块分配策略。这些策略使得大文件的数据块保持连续存储在磁盘上,数据寻址次数大大减少,显著提高I/O吞吐量。
因此,对于顺序大I/O读写,EXT4是很好的选择。另外,XFS性能在大文件方面也相当不错。