背景
作为以科技创新为驱动的娱乐公司,爱奇艺努力为用户提供丰富、高品质和智能化的专业服务。舆情分析是理解用户的一个重要方面。用户在观看视频或使用产品后,通过各种方式表达着自己的情感和观点。如对电视综艺节目内容本身的热议、对演员角色的喜爱和吐槽、对产品的意见都是舆情的内容。针对这些舆情的挖掘和分析可以更直观更清晰的显示用户的关注点和主观感受。
整个舆情分析的内容可以包括文本、图片、音频等多种形式,数据的来源也多种多样。要想从多维度全面深入的分析,就要结合技术和经验的许多知识是个系统性工程。我们只关注文本评论,讨论一些利用 NLP 技术进行舆情分析的探索和实践。
主要内容会集中在利用词法和句法分析技术、提取用户观点(包括用户评论对象和相关评价词)、情感、聚焦点等反映用户关注焦点和主观感受的特征。如,电视剧《你和我的倾城时光》中部分用户评论会作为示例,并展示具体分析过程。
功能
爱奇艺有着大量的影视剧、综艺和动漫资源。我们观看的同时也会产生大量弹幕、剧集和泡泡圈评论等语料。每一条用户的评论都可以看做文本舆情分析的基本单位。虽然文本评论属于非结构化数据, 用户的表达也比较随意,但是我们通过 NLP 技术可以转化为结构化有效信息,提取出用户对某个评价对象的观点意见和情感表达。
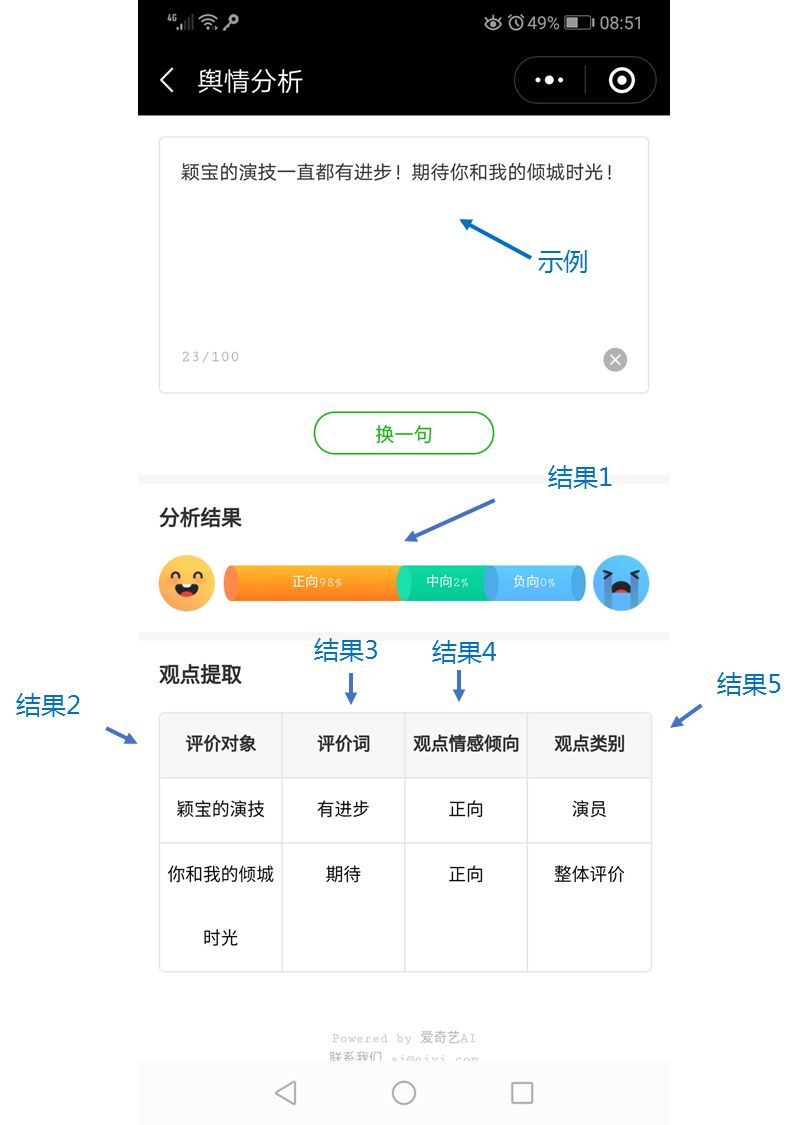
以用户的单句评论为示例,我们的舆情分析可以提取和归纳出下面多种信息:如图 1 中 电视剧《你和我的倾城时光》中一条示例评论, “颖宝的演技一直都有进步!期待你和我的倾城时光”。 我们可以得到的结构化信息包括:
- 这条评论的整句情感倾向“正向”;
- 用户评论的评价对象,“颖宝的演技” 和《你和我的倾城时光》;
- 针对评价对象的评价词,“有进步”评价颖宝的演技和“期待”评价《你和我的倾城时光》;
- 用户对评价对象的情感倾向, 在正向评价颖宝的演技和《你和我们的倾城时光》;
- 划分用户评价的观点到预先设定的类别,”颖宝的演技“属于演员类和《你和我的倾城时光》属于整体评价类。

上述只是单句级别的观点分析和情感识别,表达了单个用户的态度和感受。影视剧集的舆情分析中还需要用户群体整体感受的归纳。尤其是用户群体对特定方面的感受聚合。比如用户喜欢哪个演员、喜欢演员的哪个方面、剧集本身的情节如何等等。
我们的舆情分析在单句分析的基础上, 也包括了观点和情感归纳的功能。 如图 3 中,展示了利用大量评论语料,从《你和我的倾城时光》中演员、剧情、视觉音效三个特定维度的观点总结。分析的语料中,大多数的用户表达了对演员和剧集的喜爱。
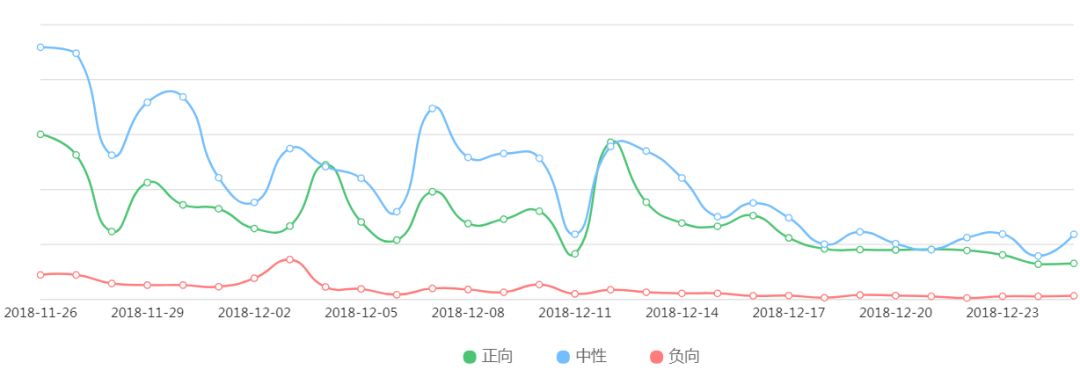
如图 4,是另外一种用户整体情感态度的归纳,是《你和我的倾城时光》在某段日期上的情感分布。这是在单句情感分析的基础上合并统计后的结果,同时也反映了用户对剧集的喜爱程度。
算法和流程
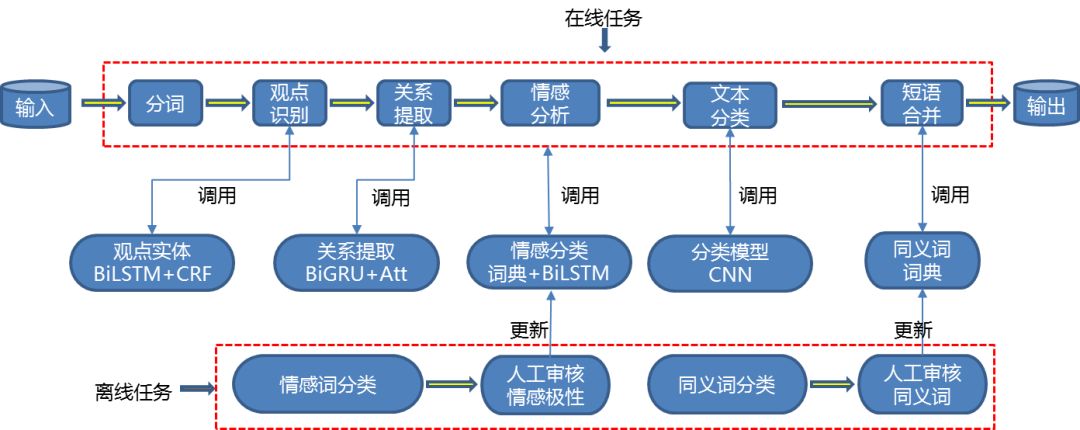
从图 1 到图 3 中的分析过程中主要会用到 NLP 技术中词语和句子级别的语义理解,具体会涉及到多个基于机器学习和深度学习的 NLP 模型。 图 1,是我们这里讨论的文本舆情分析的整体框架图。从每个用户的评论语料的输入到分析结果的输出,是通过管道串联的方式连接在一起。其中包括词法分析、观点识别、关系提取、情感分析、文本分类等多个模块。输出的分析结果可以归结为用户单句的观点和情感 (如上面图 1 所示的分析结果)以及用户整体观点和情感的分类 (如图 2 和图 3 所示的分析结果)。
整个文本分析流程中词法分析是第一步, 也是后续分析中最重要的基础。爱奇艺的词法分析服务已经广泛应用在公司多个亿级流量的业务线。它包括基于 CRF 的分词服务实体识别、词权重、实体链接等多种服务。我们的这里重点介绍的观点提取和情感分析也主要基于这个服务的分词功能。
词法分析之外,流程中重要的部分包括:
1) 观点的提取, 即用户评价对象、评价词的提取和评价词与评价对象之间关系的确定:

评价对象的提取是寻找用户想要表达观点的对象。评价词的提取是确定用户具体想表达的观点内容。如图 5(同图 1 的示例)绿色字体的词语或者短语展示了观点,提取模型提取出的用户评价对象和可能对应的评价词。为简化任务,我们可以仅考虑显式表达的提取。我们采用了 NLP 中序列标注的方式提取评价词和评价对象。通过数据集中分别标注评价词和评价对象,从而训练模型推断单个评论中对应观点和评价词的位置。 基于双向 LSTM 与 CRF 的模型 [1] 在我们自建的数据集中表现较好。
评价对象和评价词之间关系的确定是用户观点理解的另外一个重要组成部分。 见图 5, 我们会通过关系提取的方式确定绿色关键词或者短语之间的关系,比如在示例中,“有进步”在描述“颖宝的演技”, ”期待”在描述《你和我的倾城时光》,而不是在描述”颖宝的演技“。这样的方式不光可以处理示例中评价词和评价对象之间一对一的关系提取,还可以处理评价词和评价对象之间多对多的情况。
我们关系提取的模型经历了规则为主、简单模型和优化词语特征,到引入注意力机制等迭代,目前采用了基于双向 GRU 与注意力机制的分类模型。其中注意力机制部分是一种基于词和句子级别的自注意力机制 [2,3]。通过词和句子级别注意力机制的引入,在我们的数据集上解决了加权重点词和解决部分标注噪音的问题。
2) 整句和对特定评价对象的情感分析:
用户情感的解析是舆情分析中比较重要的部分。用户单句评论往往会表达一个明显的情感倾向。这个可以参照图 1 中的结果 1。我们这里跟大多数场景中一样,归纳情感为正中负三种。整句情感体现了用户整体的情感表达,这是句子或者段落级别的文本情感分析。 但是用户表达比较复杂,含有多种情感的时候需要对用户每个观点对象进行情感分析,即对用户的每个观点分别给予正中负三种情感倾向。这个可以参照图 1 中的结果 4。具体的算法我们在判断整句情感和对特定评价对象的细粒度情感时,都采用了基于双向 LSTM 的模型,并在其中引入注意力或者门的机制 [4,5],用于强化特定评价词对评价对象的作用。
3) 观点的聚合:
单句级别的观点分析和情感识别,只是单个用户的态度和感受。作为用户群体,我们需要某些特定维度上的观点总结。 参考图 2 中的示例, 我们再算法上利用了单句的观点分析结果,再加上基于 CNN 的分类模型 [6],在事先设定好的维度下聚合所有用户的观点。
总结和规划
通过电视剧评论的分析,介绍了一些利用深度学习模型和 NLP 技术从文本评论中提取用户观点和情感的方法,包括如何确定用户的评价对象、评价词和情感类别。结合这些模型和技术可以挖掘用户对影视内容的主观感受,作为基石之一,为深入的理解用户、内容运营、影视评估提供智能参考。另外,这里我们虽然主要讨论影视评论上应用,但上述流程作为一个基本通用流程,还可以应用到对产品、艺人的舆情分析中,理解用户对这些方面的观点和情感。
我们还在进行更多的尝试和迭代。功能方面,虽然用户的基本观点和情感可以被提取和聚合, 但还需要更加合理的找出用户的真正关注点,和接受程度; 数据层面、用户对影视剧、艺人、产品的关注点是有所不同的,需要在不同场景积累不同的标注文本数据;模型层面,用户的表达方式还是多种多样的,口语化,显示和隐式的表达都会出现,无法通过单一的模型解决所有问题,更多的特定场景模型优化和迭代需要持续进行。