我今天学习了spark sql
Spark SQL可以很好地支持SQL查询,一方面,可以编写Spark应用程序使用SQL语句进行数据查询,另一方面,也可以使用标准的数据库连接器(比如JDBC或ODBC)连接Spark进行SQL查询,这样,一些市场上现有的商业智能工具(比如Tableau)就可以很好地和Spark SQL组合起来使用,从而使得这些外部工具借助于Spark SQL也能获得大规模数据的处理分析能力。
对于实验五了解了Spark sql的基本操作 以及如何利用编程将RDD转化为DataFrame和编程实现利用 DataFrame 读写 MySQL 的数据 编程实现利用 DataFrame 读写 MySQL 的数据
1.Spark SQL 基本操作
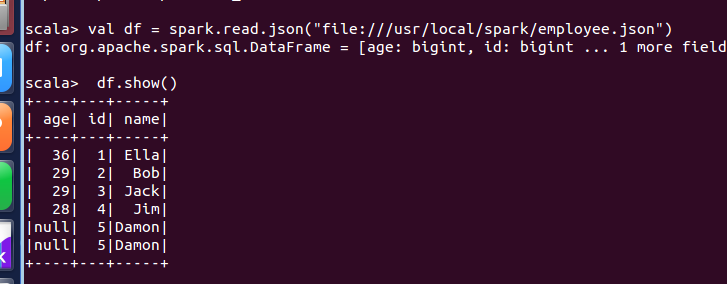
(1) 查询所有数据;
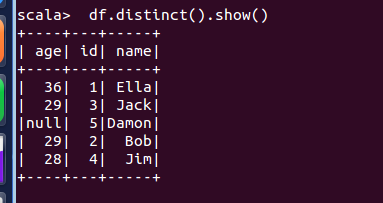
(2) 查询所有数据,并去除重复的数据;
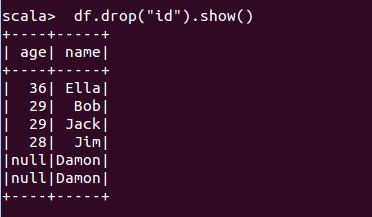
(3) 查询所有数据,打印时去除 id 字段;
(4) 筛选出 age>30 的记录;
df.filter(df("age") > 30 ).show()
5) 将数据按 age 分组;
df.groupBy("name").count().show()
(6) 将数据按 name 升序排列;
df.sort(df("name").asc).show()
(7) 取出前 3 行数据;
df.take(3) 或 scala> df.head(3
8) 查询所有记录的 name 列,并为其取别名为 username;
df.select(df("name").as("username")).show()
(9) 查询年龄 age 的平均值;
df.agg("age"->"avg")
(10) 查询年龄 age 的最小值。
df.agg("age"->"min")
l例如 df.select(df("name"), df("age") + 1).show() // 将 "age" 加 df.filter(df("age") > 21).show() # 条件语句
2.编程实现将 RDD 转换为 DataFrame
3. 编程实现利用 DataFrame 读写 MySQL 的数据

- cd /usr/local/spark
- ./bin/spark-shell
- --jars /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar
- --driver-class-path /usr/local/spark/jars/mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar
- 把下面程序一条条拷贝到spark-shell中执行
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
object TestMySQL {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("RddToDFrame").master("local").getOrCreate()
val employeeRDD = spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" "))
val schema = StructType(List(StructField("id", IntegerType,true),StructField("name", StringType, true),StructField("gender", StringType,true),StructField("age", IntegerType, true)))
val rowRDD = employeeRDD.map(p => Row(p(0).toInt,p(1).trim,p(2).trim,p(3).toInt))
val employeeDF = spark.createDataFrame(rowRDD, schema)
val prop = new Properties()
prop.put("user", "root")
prop.put("password", "199126")
prop.put("driver","com.mysql.jdbc.Driver")
employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest","sparktest.employee", prop)
Val jdbcDF = spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee").option("user","root").option("password", "199126").load()
jdbcDF.agg("age" -> "max", "age" -> "sum").show() //查询
print("ok") } }