Hadoop学习笔记(8)
——实战 做个倒排索引
倒排索引是文档检索系统中最常用数据结构。根据单词反过来查在文档中出现的频率,而不是根据文档来,所以称倒排索引(Inverted Index)。结构如下:
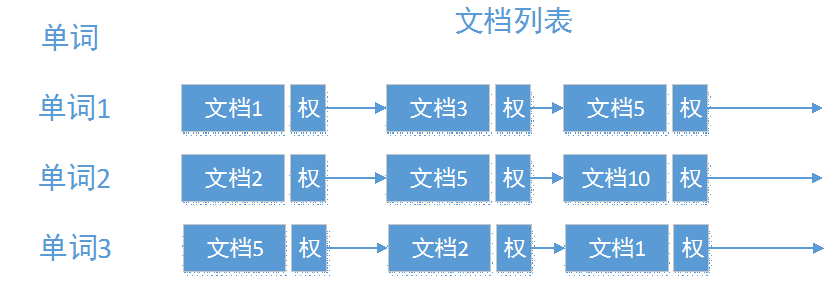
这张索引表中, 每个单词都对应着一系列的出现该单词的文档,权表示该单词在该文档中出现的次数。现在我们假定输入的是以下的文件清单:
|
T1 : hello world hello china T2 : hello hadoop T3 : bye world bye hadoop bye bye |
输入这些文件,我们最终将会得到这样的索引文件:
|
bye T3:4; china T1:1; hadoop T2:1;T3:1; hello T1:2;T2:1; world T1:1;T3:1; |
接下来,我们就是要想办法利用hadoop来把这个输入,变成输出。从上一章中,其实也就是分析如何将hadoop中的步骤个性化,让其工作。整个步骤中,最主要的还是map和reduce过程,其它的都可称之为配角,所以我们先来分析下map和reduce的过程将会是怎样?
首先是Map的过程。Map的输入是文本输入,一条条的行记录进入。输出呢?应该包含:单词、所在文件、单词数。 Map的输入是key-value。 那这三个信息谁是key,谁是value呢? 数量是需要累计的,单词数肯定在value里,单词在key中,文件呢?不同文件内的相同单词也不能累加的,所以这个文件应该在key中。这样key中就应该包含两个值:单词和文件,value则是默认的数量1,用于后面reduce来进行合并。
所以Map后的结果应该是这样的:
|
Key value Hello;T1 1 Hello:T1 1 World:T1 1 China:T1 1 Hello:T2 1 … |
即然这个key是复合的,所以常归的类型已经不能满足我们的要求了,所以得设置一个复合健。复合健的写法在上一章中描述到了。所以这里我们就直接上代码:
-
public static class MyType implements WritableComparable<MyType>{
-
public MyType(){
-
}
-
-
private String word;
-
public String Getword(){return word;}
-
public void Setword(String value){ word = value;}
-
-
private String filePath;
-
public String GetfilePath(){return filePath;}
-
public void SetfilePath(String value){ filePath = value;}
-
-
@Override
-
public void write(DataOutput out) throws IOException {
-
out.writeUTF(word);
-
out.writeUTF(filePath);
-
}
-
-
@Override
-
public void readFields(DataInput in) throws IOException {
-
word = in.readUTF();
-
filePath = in.readUTF();
-
}
-
-
@Override
-
public int compareTo(MyType arg0) {
-
if (word != arg0.word)
-
return word.compareTo(arg0.word);
-
return filePath.compareTo(arg0.filePath);
-
}
-
}
有了这个复合健的定义后,这个Map函数就好写了:
-
public static class InvertedIndexMapper extends
-
Mapper<Object, Text, MyType, Text> {
-
-
public void map(Object key, Text value, Context context)
-
throws InterruptedException, IOException {
-
-
FileSplit split = (FileSplit) context.getInputSplit();
-
StringTokenizer itr = new StringTokenizer(value.toString());
-
-
while (itr.hasMoreTokens()) {
-
MyType keyInfo = new MyType();
-
keyInfo.Setword(itr.nextToken());
-
keyInfo.SetfilePath(split.getPath().toUri().getPath().replace("/user/zjf/in/", ""));
-
context.write(keyInfo, new Text("1"));
-
}
-
}
-
}
注意:第13行,路径是全路径的,为了看起来方便,我们把目录替换掉,直接取文件名。
有了Map,接下来就可以考虑Recude了,以及在Map之后的Combine。Map的输出的Key类型是MyType,所以Reduce以及Combine的输入就必须是MyType了。
如果直接将Map的结果送到Reduce后,发现还需要做大量的工作来将Key中的单词再重排一下。所以我们考虑在Reduce前加一个Combine,先将数量进行一轮合并。
这个Combine将会输入下面的值:
|
Key value bye T3:4; china T1:1; hadoop T2:1; hadoop T3:1; hello T1:2; hello T2:1; world T1:1; world T3:1; |
代码如下:
-
public static class InvertedIndexCombiner extends
-
Reducer<MyType, Text, MyType, Text> {
-
-
public void reduce(MyType key, Iterable<Text> values, Context context)
-
throws InterruptedException, IOException {
-
int sum = 0;
-
for (Text value : values) {
-
sum += Integer.parseInt(value.toString());
-
}
-
context.write(key, new Text(key.GetfilePath()+ ":" + sum));
-
}
-
}
有了上面Combine后的结果,再进行Reduce就容易了,只需要将value结果进行合并处理:
-
public static class InvertedIndexReducer extends
-
Reducer<MyType, Text, Text, Text> {
-
-
public void reduce(MyType key, Iterable<Text> values, Context context)
-
throws InterruptedException, IOException {
-
Text result = new Text();
-
-
String fileList = new String();
-
for (Text value : values) {
-
fileList += value.toString() + ";";
-
}
-
result.set(fileList);
-
-
context.write(new Text(key.Getword()), result);
-
}
-
}
经过这个Reduce处理,就得到了下面的结果:
|
bye T3:4; china T1:1; hadoop T2:1;T3:1; hello T1:2;T2:1; world T1:1;T3:1; |
最后,MapReduce函数都写完后,就可以挂在Job中运行了。
-
public static void main(String[] args) throws IOException,
-
InterruptedException, ClassNotFoundException {
-
Configuration conf = new Configuration();
-
System.out.println("url:" + conf.get("fs.default.name"));
-
-
Job job = new Job(conf, "InvertedIndex");
-
job.setJarByClass(InvertedIndex.class);
-
job.setMapperClass(InvertedIndexMapper.class);
-
job.setMapOutputKeyClass(MyType.class);
-
job.setMapOutputValueClass(Text.class);
-
-
job.setCombinerClass(InvertedIndexCombiner.class);
-
job.setReducerClass(InvertedIndexReducer.class);
-
-
job.setOutputKeyClass(Text.class);
-
job.setOutputValueClass(Text.class);
-
-
Path path = new Path("out");
-
FileSystem hdfs = FileSystem.get(conf);
-
if (hdfs.exists(path))
-
hdfs.delete(path, true);
-
-
FileInputFormat.addInputPath(job, new Path("in"));
-
FileOutputFormat.setOutputPath(job, new Path("out"));
-
job.waitForCompletion(true);
-
}
注:这里为了调试方便,我们把in和out都写死,不用传入执行参数了,并且,每次执行前,判断out文件夹是否存在,如果存在则删除。