作者认为这主要来源于这样的一对矛盾:
图像分类:要求图像具有平移不变性(translation invariance)
目标检测:要求图像具有位置敏感性(translation variance)

首先来看一下R-FCN的网络结构。和Faster R-CNN一样,R-FCN也是 基于region proposal的两级检测架构。
“对于region-based的检测方法,以Faster R-CNN为例,实际上是分成了几个subnetwork,第一个用来在整张图上做比较耗时的conv,这些操作与region无关,是计算共享的。第二个subnetwork是用来产生候选的boundingbox(如RPN),第三个subnetwork用来分类或进一步对box进行regression(如Fast RCNN),这个subnetwork和region是有关系的,必须每个region单独跑网络,衔接在这个subnetwork和前两个subnetwork中间的就是ROI pooling。我们希望的是,耗时的卷积都尽量移到前面共享的subnetwork上。因此,和Faster RCNN中用的ResNet(前91层共享,插入ROI pooling,后10层不共享)策略不同,本文把所有的101层都放在了前面共享的subnetwork。最后用来prediction的卷积只有1层,大大减少了计算量。

R-FCN 首先也是一个RPN的网络,用于生成和训练proposal(ROI)。所不同的是,Faster R-CNN中,ROI Pooling层直接对ROI进行分块池化输出用于分类和回归的特征向量。
R-FCN中,则将每一个ROI划分成k×k个格,池化输出每个格的位置得分,再通过投票方式得到 ROI 最后的输出特征向量。的首先生成 k^2(C+1) 通道大小的输出。其中,C 为类别数(+1为背景), k^2 表示将ROI区域划分成 k×k个格,如上图所示。如 k=3,则对应9个格,分别为上左(左上角),上中,上右,中左,中中,中右,下左,下中,下右(右下角),如下图所示:

Backbone网络:ResNet101——去除原始网络最后的平均池化层和全连接层,保留100层的卷积层用于特征提取。为了降维,100层卷积层之后又添加了一层1×1×1024的卷积层,使输出维度变成1024(原始的是2048)。之后再接一层卷积层用于产生得分图
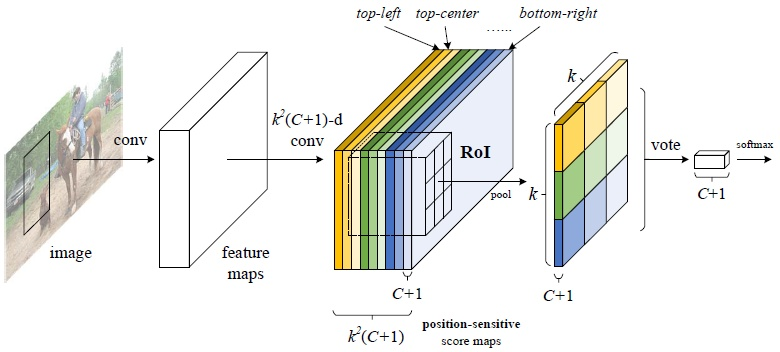
这张图就是R-FCN的网络结构图,其主要设计思想就是“位置敏感得分图position-sensitive score map”。现在就对着这张图来解释其设计思路。如果一个RoI含有一个类别c的物体,那么作者将该RoI划分为 个区域,分别表示该物体的各个部位,比如假设该RoI中含有人这个物体,k=3,那么就将“人”划分为了9个子区域,top-center区域毫无疑问应该是人的头部,而bottom-center应该是人的脚部,而将RoI划分为
个区域是希望这个RoI在其中的每一个区域都应该含有该类别c的物体的各个部位,即如果是人,那么RoI的top-center区域就必须含有人的头部。而当这所有子区域都含有各自对应的该物体的相应部位后,那么分类器才会将该RoI判断为该类别。物体的各个部位和RoI的这些子区域是“一一映射”的对应关系。
好了,现在我们知道了一个RoI必须是 个子区域都含有该物体的相应部位,才能判断该RoI属于该物体,如果该物体的很多部位都没有出现在相应的子区域中,那么就判断该RoI为背景类别。那么现在的问题就是“网络如何判断一个RoI的
个子区域都含有相应部位呢?”前面我们是假设知道每个子区域是否含有物体的相应部位,那么我们就能判断该RoI是否属于该物体还是属于背景。那么现在的任务就是“判断RoI子区域是否含有物体的相应部位
这就是position-sensitive score map设计的核心思想了。R-FCN会在共享卷积层的最后再接上一层卷积层,而该卷积层就是“位置敏感得分图position-sensitive score map”,该score map是什么意义呢?首先它就是一层卷积层,它的height和width和共享卷积层的一样,但是它的channels= ,如上图所示。那么C表示物体类别种数再加上1个背景类别,每个类别都有
个score maps。现在我们先只针对其中的一个类别来讨论,假设是人这个类别,那么其有
个score maps,每一个score map表示“原图image中的哪些位置含有人的某个一个部位”,而该score map会在含有“该score map对应的人体的某个部位”的位置有“高响应值”,也就是说每一个score map都是用来“描述人体的其中一个部位出现在该score map的何处,而在出现的地方就有高响应值”。那么好了既然是这样,那么我们只要将RoI的各个子区域对应到“属于人的每一个score map”上然后获取它的响应值不就好了。对,就是这样。但是要注意,由于一各score map都是只属于“一个类别的一个部位”的,所以RoI的第
个子区域一定要到第
张score map上去找对应区域的响应值,因为RoI的第
的子区域需要的部位和第
张score map关注的部位是一样的,所以就是这样的对应关系。那么现在该RoI的
个子区域都已经分别到“属于人的
个score maps”上找到其响应值了,那么如果这些响应值都很高,那么就证明该RoI是人呀~对吧。不过,当然这有点不严谨,因为我们只是在“属于人的
个score maps”上找响应值,我们还没有到属于其它类别的score maps上找响应值呢,万一该RoI的各个子区域在属于其它类别的上的score maps的响应值也很高,那么该RoI就也有可能属于其它类别呢?是吧,万一2个类别的物体本身就长的很像呢?所以呢,当然就是看那个类别的响应值更高了。
https://zhuanlan.zhihu.com/p/30867916文章很不错,可以借鉴读一读。