1.理解分类与监督学习、聚类与无监督学习。
简述分类与聚类的联系与区别。
简述什么是监督学习与无监督学习。
分类,通常需要你告诉它“这个东西被分为某某类”这样一些例子,理想情况下,一个 classifier 会从它得到的训练集中进行“学习”,从而具备对未知数据进行分类的能力,这种提供训练数据的过程通常叫做supervised learning (监督学习),
聚类,简单地说就是把相似的东西分到一组,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,因此 clustering 通常并不需要使用训练数据进行学习,这在Machine Learning中被称作unsupervised learning (无监督学习).
2.朴素贝叶斯分类算法 实例
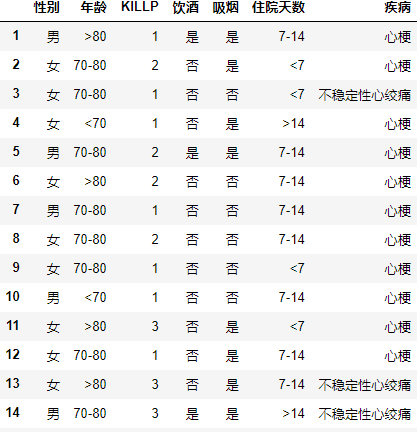
利用关于心脏情患者的临床数据集,建立朴素贝叶斯分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:–心梗–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
上传演算过程。
3.编程实现朴素贝叶斯分类算法
利用训练数据集,建立分类模型。
输入待分类项,输出分类结果。
可以心脏情患者的临床数据为例,但要对数据预处理。
import pandas as pd def get(data,dic,result_doc): r1,r2,r3 = result_doc#第一个值为疾病 2心梗 3心绞痛 df1 = data.groupby([r1]).size().reset_index() geng = 0 jiao = 0 for i,j in df1.values: if(i == r2): geng = j else: jiao = j temp1 =1 temp2 = 1 for i,j in dic.items(): #a = data.ix[:,[i,'疾病']] df=data.groupby([i,r1]).size().reset_index() for a,b,c in df.values: if(a==j and b==r2): temp1 = temp1*c/geng for i,j in dic.items(): #a = data.ix[:,[i,'疾病']] df=data.groupby([i,r1]).size().reset_index() for a,b,c in df.values: if(a==j and b==r3): temp2 = temp2*c/jiao if geng/len(data)*(temp1/temp2) > jiao/len(data)*(temp1/temp2): return '心梗' else: return '心绞' if __name__ == '__main__': data = pd.read_excel("d:/my_excel.xlsx") dic = {'性别': '男', '年龄': '<70', 'KILLP': '1', '饮酒': '是', '吸烟': '是', '住院天数': '<7'} print(get(data,dic,['疾病','心梗','不稳定性心绞痛']))
from sklearn.naive_bayes import GaussianNB from sklearn.datasets import load_iris iris = load_iris() gnb = GaussianNB() gnb.fit(iris.data,iris.target) gnb.predict([[4.8, 3.5 , 4.2, 1.2])