CNN网络已经是近几年来用于视觉物体检测的最主要的机器学习方法了。尽管它才被提出来二十年左右,但是高速发展的硬件以及逐渐被提出来的各种网络结构已经使得深度的网络学习成为一种可能。但是随着网络层数的增加不可避免的在训练的过程中就会出现梯度消失或者梯度爆炸这样的现象。一种有效的解决方法就是通过skip增加层之间的连接,比如R二十Net以及FractalNet上都是这样去操作的。在这篇文章中作者提出了一种新的网络结构以及更加简单的连接方式,为了保证网络中层之间1信息流的最大化互换,我们干脆连接了所有层。为了保存前馈的自然,每一层都接受来自他之前所有层的输出作为输入,所以一个N层的网络,一共存在n*(n+1)/2个的连接,下面这样图简单介绍了一个五层的DenseNet实例。

DenseNet一个重要的优点是,在相同性能或者相同层数的情况下,他需要较少的参数。这是因为它与之前所有层都有着直接连接,所以一些前面已经学习出来的特征,他不需要重复学习。经过下面的这张表格实验对比可以看出,DenseNet系列的模型无论是在错误率以及模型的精简程度上都比在之前的模型有了较大的提高。
二、模型
假设一张图片X0进过一个卷积神经网络,这个网络由L个层,每个层都实现了一个非线性变换Hl,其中l代表第多少层。Hl可以是一个由batch size,pool,convolution,Relu等混合而成的方程,我们将第l层的输出表示为Xl。
1)ResNet残差网络
传统的前馈卷积网络将第l层的输出当做第l+1层的输入。残差网络加入了skip进行连接,对非线性方程的结果加入了一个偏置。残差网络的一个优点是梯度可以直接从偏置方程从后面那些层传递到前面那些层。然而identify层与前一层输出的连接是通过求和进行的,这个过程会阻碍信息流在网络里面的传递。
2)Dense connectivity 密集连接
为了数据在层之间更好的流通我们提出了一种不同的连接方案:我们引入了所有层与他之后的层里面进行直接连接这样的机制。上面图一展现了真个模型的分布。作为结果,第l层获得了它之前所有层的特征图。x 0 ,...,xl−1 作为输入:

其中X0到Xl-1代表前面第l层的输出。由于模型的密集性,我们将这个模型称为DenseNet(密集网络)。为了易于实现,我们将上述多输入连接为一个张量。
3)Composite function复合函数
2中所提及的hl是三种连续操作的混合:首先是batch-normalization,然后之后是一个Relu的过程,最后再加上一个3*3的卷积。
4)Pooling layers 池化层
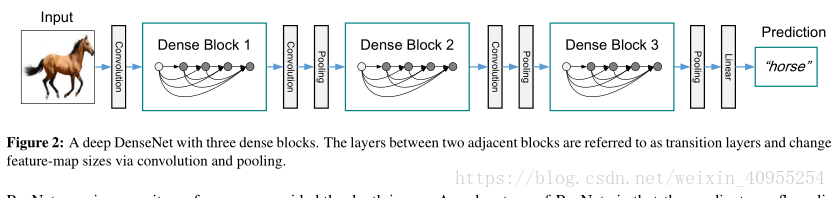
当特征图的大小改变的时候,用于方程二中的连接操作就变得不可行。然而,卷积网络中的一个重要部分就是下采样层会改变特征图的大小。为了促进我们结构里的下采样过程我们将网络分为densely连接的dense block。如图2所示,我们将block之间的层叫做转换层,转换层执行卷积和池化操作。我们实验中用到的转换层包含了一个batch normalization,一个1*1的卷积层以及一个2*2的均值池化层。
5)Growth rate
如果每个Hl产生k个特征映射关系,他就相当于第l层由k0+k*(l-1)个输入,k0是输入层的通道数。Densenet与显存网络结构一个重要的不同在于densenet可以有十分狭窄的层,我们将超参数k定义为网络的生长速率。在第四节我们展示了一个小的生长率足够获得好的表现在我们测试的数据及上。对这个的一个解释是每一层都可以访问他所在模块之前层的表现因此拥有这个网络框架的集中地信息。我们可以将这些特征图看作为网络的整体状态。生长率决定了每一层对整体状态贡献了多少新信息。这里的全局状态,不同于传统网络需要一层一层复制所有的信息。
6)bottleneck layers瓶颈层
尽管每一层只有k个输出,但是他拥有更多的输入唯独。有文章中提出这样的观点,在每个3*3的卷积之前使用1*1的卷积作为bottleneck layer可以减少输入特征层的数量,并且因此提高计算的有效性。我们发现这个设计对于densenet特别有用,所以在我们的网络中采取了这样的bottleneck layer,具体的过程是这样的BN-ReLU-Cov(1*1)-BN-ReLU-Cov(3*3)作为densenetB。在我们的实验里,我们让1*1的卷基层产生4000个特征映射。
7)Compression 压缩
为了更好的提高模型的经凑性,我们可以在转换层减少feature-map的数量。如果一个denseblock包含了m和featuremap,我们让之后的转换层输出θm个特征映射,0<θ<1被视为压缩系数,我们将θ<1的网络称为densenet-c,我们的实验中这个值为0.5,当bottleneck和θ都被用上了,我们就把这个网络称为densenet-BC。
个block拥有相同层数。在进入第一个denseblock之前,一个拥有16个输出通道的卷积层先被执行了。对于卷积核大小为3*3的卷基层,每边的输入都被0填补了为了使特征图的大小固定。我们在两个denseblock之间使用2*2的均值池化层加上1*1的卷积层作为转换层。在最后一个denseblock的最后,一个全局池化以及一个softmax 分类器被执行了。三个dense block里面的特征图大小分别是32*32,16*16,8*8.在关于imagenet的实验中,我们采用了四个denseblock模块,具体细节可以见下表。
