紧接着上一篇博文我们学习了MapReduce得到输出格式之后,在这篇博文里,我们将通过一个实战小项目来熟悉一下MultipleOutputs(多输出)格式的用法。
项目需求:
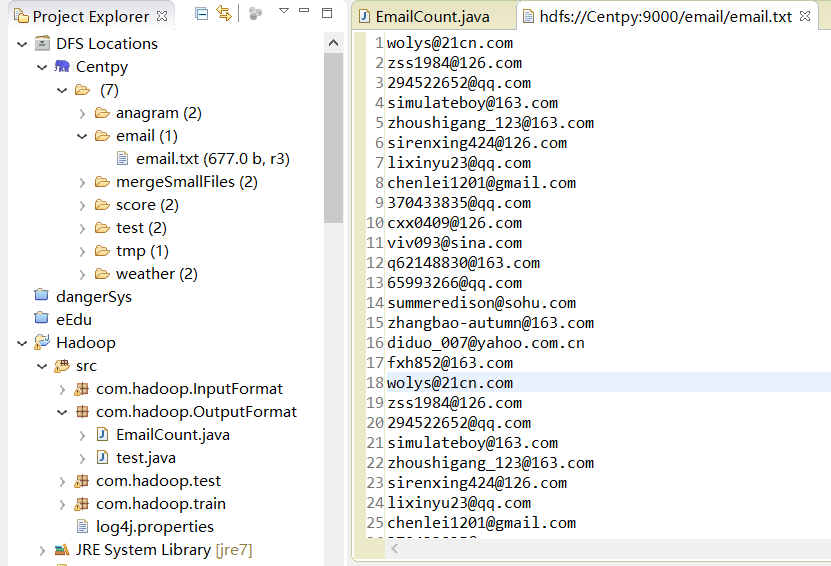
假如这里有一份邮箱数据文件,我们期望统计邮箱出现次数并按照邮箱的类别,将这些邮箱分别输出到不同文件路径下(MultipleOutputs)。数据集示例如下所示。
wolys@21cn.com
zss1984@126.com
294522652@qq.com
simulateboy@163.com
zhoushigang_123@163.com
sirenxing424@126.com
lixinyu23@qq.com
chenlei1201@gmail.com
370433835@qq.com
cxx0409@126.com
viv093@sina.com
q62148830@163.com
65993266@qq.com
summeredison@sohu.com
zhangbao-autumn@163.com
diduo_007@yahoo.com.cn
fxh852@163.com
下面我们编写 MapReduce 程序,实现上述业务需求。
项目实现:
新建一个EmailCount.java类,在其中编写一下程序
package com.hadoop.OutputFormat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class EmailCount extends Configured implements Tool{
public static class MailMapper extends Mapper< LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, one);
}
}
public static class MailReducer extends Reducer< Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
private MultipleOutputs< Text, IntWritable> multipleOutputs;
@Override
protected void setup(Context context) throws IOException ,InterruptedException{
multipleOutputs = new MultipleOutputs< Text, IntWritable>(context);
}
protected void reduce(Text Key, Iterable< IntWritable> Values,Context context) throws IOException, InterruptedException {
//294522652@qq.com
int begin = Key.toString().indexOf("@");
int end = Key.toString().indexOf(".");
if(begin>=end){
return;
}
//获取邮箱类别,比如 qq
String name = Key.toString().substring(begin+1, end);
int sum = 0;
for (IntWritable value : Values) {
sum += value.get();
}
result.set(sum);
multipleOutputs.write(Key, result, name);
}
@Override
protected void cleanup(Context context) throws IOException ,InterruptedException
{
multipleOutputs.close();
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();// 读取配置文件
Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);//创建输出路径
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
Job job = Job.getInstance();// 新建一个任务
job.setJarByClass(EmailCount.class);// 主类
FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径
job.setMapperClass(MailMapper.class);// 设置Mapper类
job.setReducerClass(MailReducer.class);// 设置Reducer类
job.setOutputKeyClass(Text.class);// key输出类型
job.setOutputValueClass(IntWritable.class);// value输出类型
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
String[] args0 = {
"hdfs://Centpy:9000/email/email.txt",
"hdfs://Centpy:9000/email/outputs/"
};
int ec = ToolRunner.run(new Configuration(), new EmailCount(), args0);
System.exit(ec);
}
}
项目测试:
首先,我们的输入文件如下所示。
将项目文件导出为JAR文件,然后上传到Hadoop集群上。
运行以下指令
hadoop jar EmailCount.jar com.hadoop.OutputFormat.EmailCount /email /email/outputs
项目结果:
项目测试结果如下所示
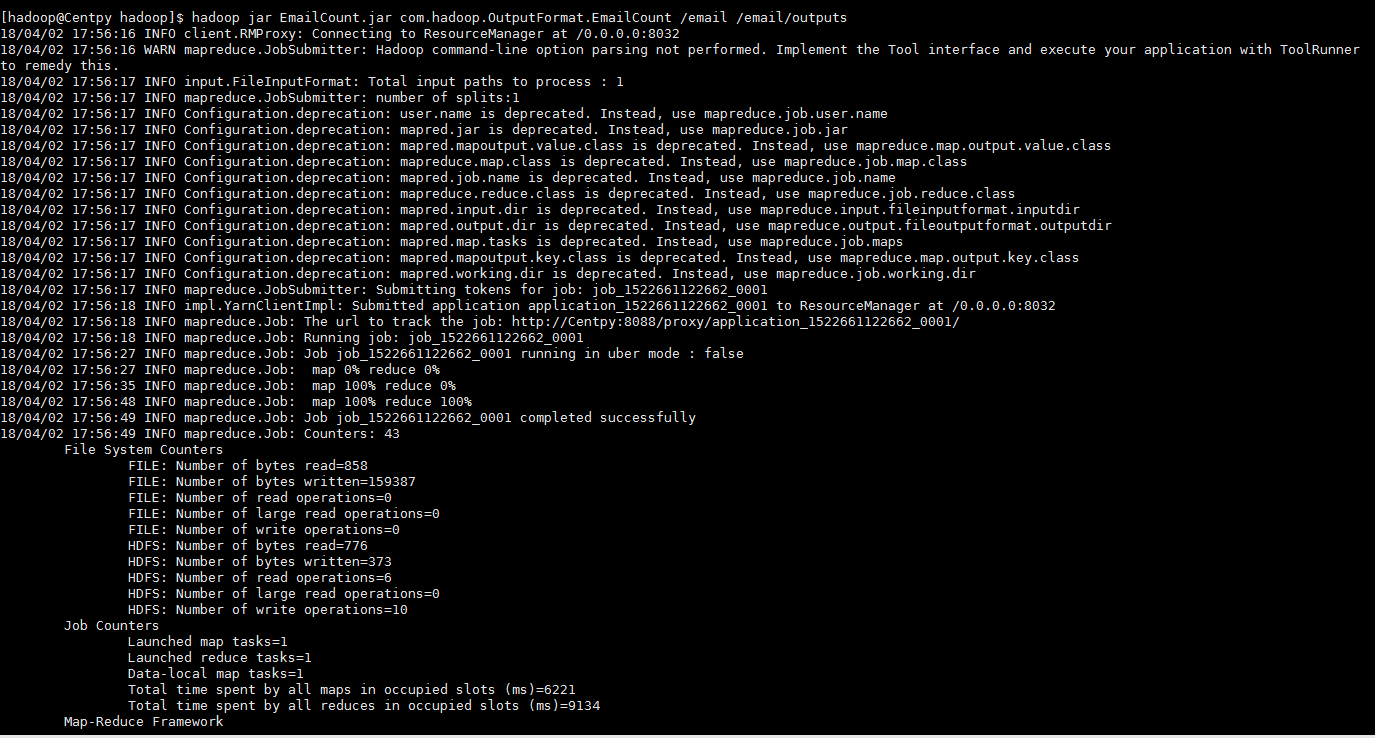
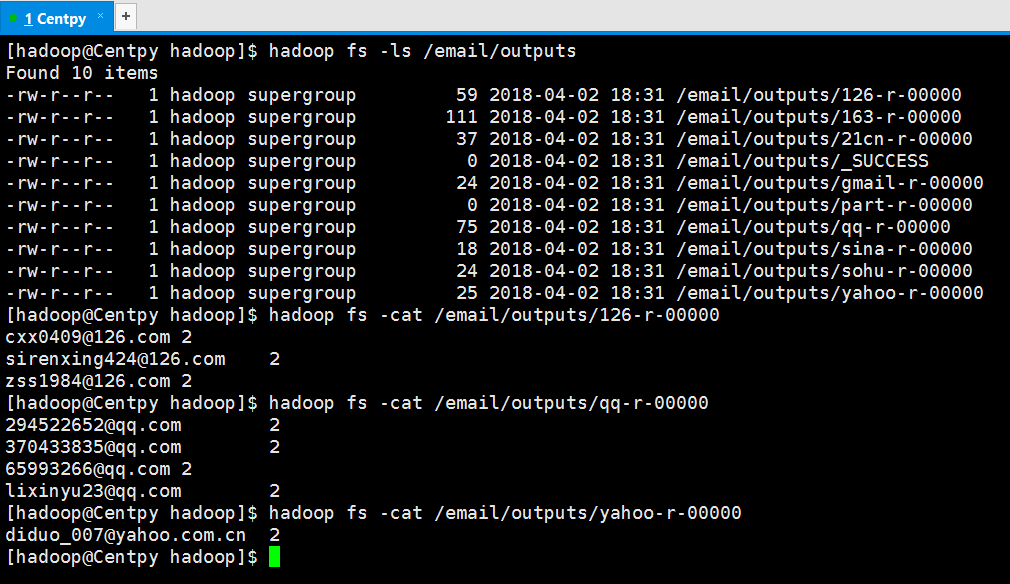
从结果可以看出,我们通过MapReduce成功实现了邮箱统计的MultipleOutputs格式,即将邮箱进行分类,然后每一个类型的邮箱单独存储到一个输出文件中,并在其中显示邮箱的统计次数。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。